TutorialFest @ POPL'13
The POPL 2013 TutorialFest contains no less than six tutorials, covering a variety of topics. The tutorials will be held on January 21, two days ahead of the main POPL conference and the day before the Programming Languages Mentoring Workshop (PLMW). Attending TutorialFest is free for all POPL and PLMW attendees. In the event of available spaces filling up, PLMW attendees will be prioritised.
Registrants of POPL or PLMW may attend any of the tutorials offered throughout the day. (This allows following four tutorials in full.) To keep costs down, no meals are included.
Link to registration here.
All tutorials will be held twice during the day, giving attendees plenty of options for scheduling. As last year, POPL is favouring a "distilled tutorial format": each tutorial will be 90 minutes, rather than a half day.
Questions may be directed to Tobias Wrigstad (tobias.wrigstad@it.uu.se).
Speakers
 Susmit Sarkar — Shared-Memory Concurrency in the Real World: Working with Relaxed Memory Consistency
Susmit Sarkar — Shared-Memory Concurrency in the Real World: Working with Relaxed Memory Consistency
Room: Sforza B.
Times: 9:00-10:30 and 14:00-15:30.
Abstract: Shared-memory concurrency is now mainstream, from phones to servers. However, real-world implementations do not validate the basic assumption of Sequential Consistency traditionally made in work on concurrent programming and verification. Instead, we get subtle relaxed consistency models. Furthermore, the consistency models of different hardware architectures vary widely and have often been poorly defined, while programming language models (aiming to abstract from hardware details) are different again.
This tutorial will explain what relaxed consistency models we actually get on current mainstream systems: the x86 multiprocessor architecture, the IBM Power and ARM lines of multiprocessors, and in the new concurrency model in ISO C/C++11. We will discuss these models, how they work, and how to understand them. We will also see how we can work with such models: for testing programs, for proving facts about the models, and for proving correctness of programs above those models.
Learning objectives: On completing the tutorial, the student will understand the memory consistency models of modern multiprocessors, a necessary ingredient for research in reasoning about shared-memory concurrent systems code.
Bio: Susmit Sarkar is an EPSRC Research Fellow at the University of Cambridge. He has recently researched concurrency on modern hardware such as x86, ARM, and POWER, and the new concurrency model introduced in C11/C++11. Before that, his PhD from Carnegie Mellon studied programming languages for certified code systems. His research interests are in developing and using mathematically rigorous models of real-world systems, particularly high-performance low-level code.
 Alexey Gotsman — Consistency in Concurrent and Distributed Systems
Alexey Gotsman — Consistency in Concurrent and Distributed Systems
Room: Sforza C.
Times: 9:00-10:30 and 11:00-12:30.
Abstract: When constructing complex concurrent systems, abstraction is vital: programmers should be able to reason about separate components of a system in terms of abstract specifications that hide the implementation details. Whereas notions of specification for components in sequential programming languages have been well-studied, those for concurrent and distributed environments are poorly understood. The main challenge when dealing with components in such settings lies in formulating the level of data consistency - guarantees that processes accessing a component concurrently observe a coherent view of the data it stores.
In this tutorial, I will present a range consistency notions, from strong levels of consistency used in shared-memory, such as linearizability, to weaker notions used in distributed systems, such as eventual consistency. I will also discuss the principles of how new consistency notions can be defined for various programming models and will demonstrate their use in modular verification. The material presented will be complementary to that in the tutorial on relaxed memory models.
Learning objectives: After attending the tutorial, participants will know about common notions of data consistency and criteria defining their correctness. They will also get a flavour of how such notions can be defined for various programming models.
Bio: Alexey Gotsman is an Assistant Research Professor at the IMDEA Software Software Institute in Madrid, Spain. Before joining IMDEA, he was a postdoctoral fellow at the University of Cambridge, UK, where he also got his Ph.D. His research interests are in software verfication, particularly, in developing reasoning techniques and automated verification tools for real-world systems software.
 Matthew Flatt — Building Languages in Racket
Matthew Flatt — Building Languages in Racket
Room: Sforza B.
Times: 11:00-12:30 and 16:00-17:30.
Abstract: Racket is an extensible programming language that allows programmers to define syntactic forms, create embedded domain-specific languages (DSLs), and construct entirely new programming languages. Racket inherits its basic approach to extensibility from Lisp and Scheme, but Racket's unique features enable an even greater degree of language extension and composition. This tutorial will provide a refresher on Lisp-style extensibility, cover Scheme-style pattern-matching and procedural macros, and delve into Racket-specific topics like syntax parameters, redefining implicit macros, the syntax-parse library, macros that cooperate through compile-time information, non-parenthesized syntax, and integrating with the DrRacket programming environment.
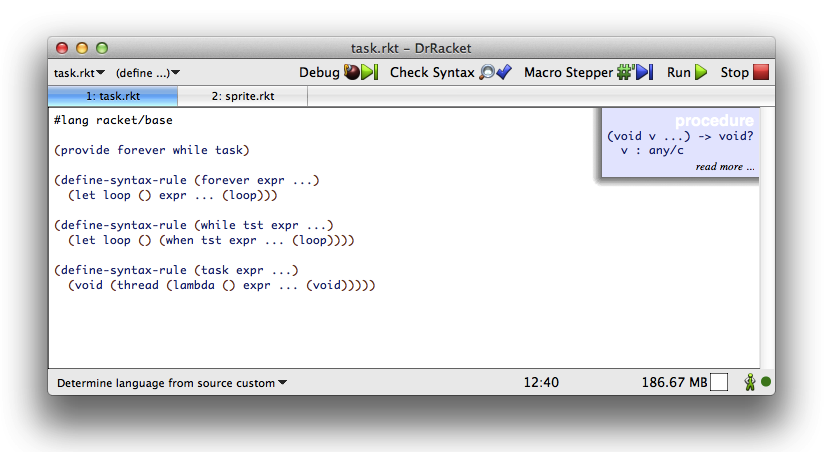
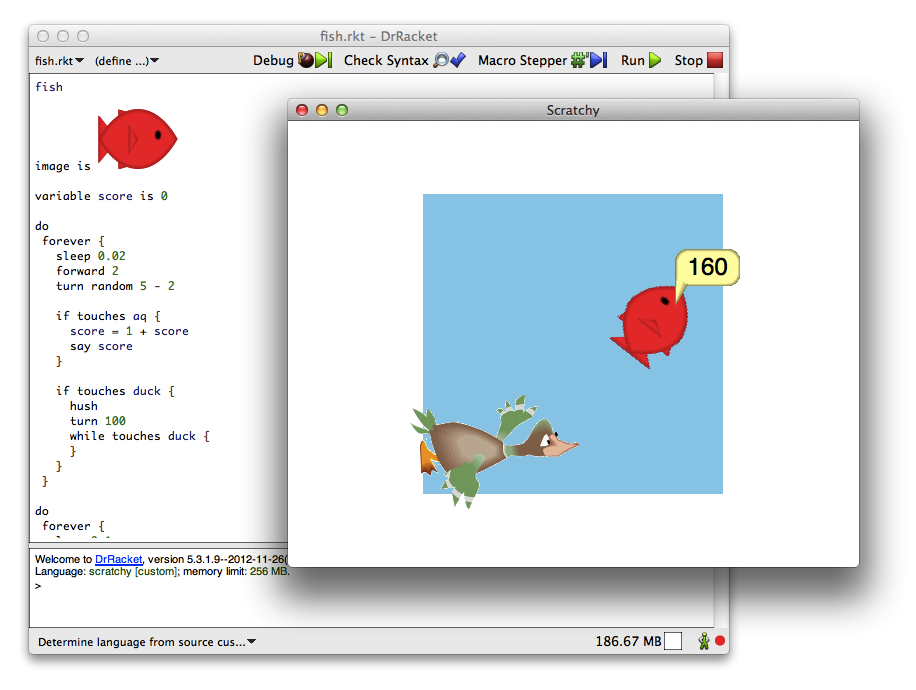
Learning objectives: Participants will learn to use Racket macros to implement the core of a programming language and use it directly as a new `#lang'-based language. Participants will also see how Racket and DrRacket can be adapted to non-parenthesized syntax through `#lang'.
Bio: University of Utah. He is one of the developers of the Racket programming language and a co-author of the introductory programming textbook ``How to Design Programs''. He received his PhD in computer science from Rice University in 1999 and joined Utah in 1999.
 Adam Chlipala — A Taste of Effective Coq Proof Automation
Adam Chlipala — A Taste of Effective Coq Proof Automation
Room: Sforza C.
Times: 14:00-15:30 and 16:00-17:30.
Abstract: Many POPL folks are using computer proof assistants these days, and more or less all of them are feeling the pain of writing and maintaining detailed manual proof scripts. In this tutorial, I will give a taste of how to skip the pain by writing highly automated proof scripts in Coq. These scripts in a sense explain why a theorem is true at a high level rather than giving the nitty-gritty details, which often allows a single script to be used through multiple evolutions of a theorem. Examples will be drawn from semantics of programming languages and compiler verification. No prior Coq experience will be assumed, though familiarity with the basics of programming language semantics will be helpful.
Learning objectives: Participants should come away able to write simple Coq proof scripts that adapt automatically as new cases are added to the syntax and semantics of programming languages.
Bio: Adam Chlipala is an assistant professor in computer science at MIT. His research focus is applying mechanized logical reasoning to improve software development. Much of his work uses the Coq proof assistant, about which he has written a popular book, "Certified Programming with Dependent Types." Adam has worked in proof-carrying code, mechanized metatheory, compiler verification, proof automation for higher-order separation logic, and applying ideas from dependent type theory to the domain of Web programming (in the domain-specific language Ur/Web).
 Juergen Giesl — Automated Termination Analysis: From Term Rewriting to Programming Languages
Juergen Giesl — Automated Termination Analysis: From Term Rewriting to Programming Languages
Room: Sforza D.
Times: 11:00-12:30 and 16:00-17:30.
Abstract: Termination is a crucial property of programs. Therefore, techniques to analyze the termination behavior automatically are highly important for program verification. Traditionally, techniques for automated termination analysis were mainly studied for declarative programming paradigms such as logic programming and term rewriting. However, in the last years, several powerful techniques and tools have been developed which analyze the termination of programs in many programming languages including Java, C, Haskell, and Prolog.
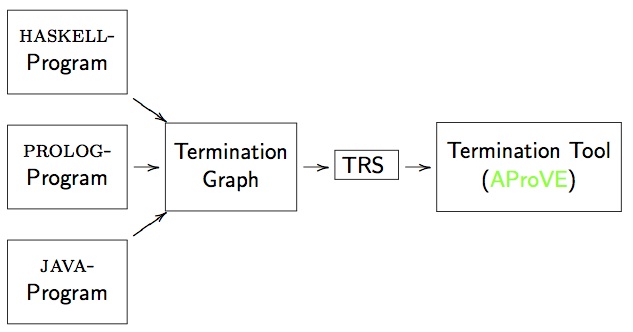
In the tutorial, we will consider automated termination analysis for several different programming languages. We start with the foundations of termination proving and introduce powerful techniques to analyze declarative programming paradigms like term rewriting. Afterwards, we show how to extend such techniques in order to tackle programs in real programming languages. In particular, we present a powerful approach for automated termination analysis of Java programs, which uses techniques from term rewriting as a back-end.
Learning objectives: After attending the tutorial, a student will know about the basics of automated termination analysis, both for general models of computation (like term rewriting) and for actual programming languages (like Java). Moreover, the student will get an intuition how analysis techniques can be adapted from one programming paradigm to another.
Bio: Jürgen Giesl is professor of computer science at RWTH Aachen University, Germany. His research interests are in automated program analysis and verification as well as in automated reasoning and term rewriting. In particular, he and his research group developed the AProVE tool for automated termination analysis of languages like Java, Haskell, Prolog, and term rewriting.
 Grigore Rosu — Design you own programming language with K
Grigore Rosu — Design you own programming language with K
Room: Sforza D.
Times: 9:00-10:30 and 14:00-15:30.
Abstract: K is a rewrite-based executable semantic framework in which programming languages, type systems and formal analysis tools can be defined using configurations, computations and rules. Configurations organize the state in units called cells, which are labeled and can be nested. Computations carry computational meaning as special nested list structures sequentializing computational tasks, such as fragments of program. Computations extend the original language abstract syntax. K (rewrite) rules make it explicit which parts of the term they read-only, write-only, read-write, or do not care about. This makes K suitable for defining truly concurrent languages even in the presence of sharing. Computations are like any other terms in a rewriting environment: they can be matched, moved from one place to another, modified, or deleted. This makes K suitable for defining control-intensive features such as abrupt termination, exceptions or call/cc. Several real languages have been defined in K, such as C, Java (1.4), Scheme, Verilog, and dozens of prototypical or classroom ones.
Learning objectives: The attendees will learn how to define a language or a type system in K in an executable manner, and then how to use that definition to get a useful model of the defined language or system which is amenable for analysis. In spite of being quite formal, K is easy to learn and use, and quite colorful and fun.
Bio: Grigore Rosu is an associate professor in the Department of Computer Science at the University of Illinois at Urbana-Champaign (UIUC), where he leads the Formal Systems Laboratory (FSL). His research interests encompass both theoretical foundations and system development in the areas of formal methods, software engineering and programming languages. Before joining UIUC in 2002, he was a research scientist at NASA Ames.
Schedule
Room names will be updated to the proper venue names soon.
| Time/Room | Sforza B | Sforza C | Sforza D |
|---|---|---|---|
| 09:00-10:30 | Susmit | Alexey | Grigore |
| 11:00-12:30 | Matthew | Alexey | Jürgen |
| 14:00-15:30 | Susmit | Adam | Grigore |
| 16:00-17:30 | Matthew | Adam | Jürgen |
Register for POPL tutorials now!
Click here. This link will take you to a Google Docs Form where you will be instructed to provide contact information and choose what tutorials you will attend.