C Bootstrapping (2 weeks)
Table of Contents
- 1. Introduktionslabbar i C (V1-2)
- 2. Skillnader mellan Haskell och C
- 3. Labb 1: Grundläggande koncept
- 3.1. Steg 1: Emacs-fix
- 3.2. Steg 2: Setup
- 3.3. Hello, world!
- 3.4. Skriv ut talföljden 1–10
- 3.5. Skriv ut talföljden 10–1
- 3.6. Nästade loopar
- 3.7. Kommandoradsargument 1/2
- 3.8. Primtalstest
- 3.9. Största gemensamma delare (GCD)
- 3.10. Kontrollera om en sträng är ett tal redovisas
- 3.11. Extrauppgifter
- 3.12. Heltalsvariablernas ändlighet
- 4. Labb 2: I/O och funktioner
- 5. Labb 3: Rekursion, Generalisering & Funktionspekare
- 6. Labb 4: Del 1 – pekare
- 7. Labb 5: mer I/O och utökning av
db.c - 8. Ladda upp alla dina labbar på GitHub
Did you know that you can collapse () and expand () entire sections of these pages? Try clicking a heading! Try “scrolling” to content deep down in a page by collapsing preceeding sections.
Found a bug? Select the faulty text and hit C-x to start a GitHub issue.
1 Introduktionslabbar i C (V1-2)
Välkommen till vad som i IOOPM-mytologin kallas för Adams Weckor1! De här två första veckorna är till för att du ska lära dig programmera i C. Du kommer garanterat inte känna dig färdig med C efter bara två veckor, men om du går på alla sex labbar kommer du ha fått minst 24 timmar av de 10.000 timmar som behövs2 för att bli en expert på programmering, och du kommer vara väl förberedd på resten av kursen.
Samtliga labbars uppgifter finns på denna sida! Varje labb har en eller flera uppgifter markerade med redovisas. Dessa uppgifter ska redovisas för en labbassistent. Senare under kursens kommer redovisningarna vara mer utförliga men under de här labbarna räcker det med att skriva upp sig på tavlan i 1515 och visa vad du har gjort. Förbered gärna ett litet körexempel!
Uppgifterna bygger ofta på tidigare uppgifter och tidigare labbar, så det bästa sättet att lösa dem är helt enkelt att jobba uppifrån och ner.
During the C bootstraps, there will be a specific task for each lab. Depending on your programming background, it is possible that you will not finish each lab during the four scheduled lab hours.
During the first C assignment, there will be a collection of discrete steps to perform. From then on, labs will be an opportunity to get help or make demonstrations and most work will be done outside of labs.
During the second C assignment, there is no given trajectory – you will have to not only code, but decide in what order to implement features, tackle problems, etc.
1.1 Är labbarna obligatoriska?
Det är obligatoriskt att göra dem, men inte att göra dem på plats. Redovisning är enbart möjligt på plats, men alla labbar finns ute från dag 1 och kan göras när som helst.
1.2 Måste jag arbeta med någon annan?
Ja. Nej. Nja. Det är bra att arbeta i par om två – dels för att du kommer att göra det senare under kursen, ev. också arbetslivet, men också för att det främjar reflektion att samarbeta med någon annan – eftersom ni måste diskutera vad ni håller på med och inte “bara göra det” i en blind jakt på att bli klar3. Det viktigaste är att varje enskild person har varit med och gjort allt som labbarna innehåller. Om du jobbar själv händer det automagiskt. Om du jobbar med någon annan måste du se till att vara 50% av tiden framför tangentbordet! *Du kommer inte att lära dig programmering om du låter någon annan skriva all kod!!!*
1.3 Deadlines
Vi rekommenderar att du försöker hinna klart med uppgifterna på det labbtillfälle de ges (under Adams Weckor). Varje labbs mjuka deadline är alltså samma dag som den ges. Om du av någon anledning inte hinner klart, eller om du missar en labb kan du göra klart labben på egen hand och istället redovisa den på efterföljande labb. Varje labbs hårda deadline är alltså efterföljande labbtillfälle.
Om du av någon anledning tror att du inte kommer klara någon hård deadline, hör av dig till en senior assistent eller till huvudläraren så hittar vi en lösning!
1.4 Om du kör fast
Det finns många sätt att komma vidare om du kör fast:
- Fråga en labbassistent - Assarna är här för att hjälpa till
- Kom ihåg att de inte sitter på “det rätta svaret” (det finns nästan aldrig bara en enda lösning när man programmerar) men förmodligen kan hjälpa dig komma vidare med din egen lösning.
- Fråga en kompis
- Att prata om programmering är ett utmärkt sätt att lära sig programmera, oavsett om man är den som förklarar eller den som får hjälp. Så länge man inte skriver av varandras lösningar rakt av så finns det inga problem att diskutera lösningar med varandra.
- Ställ en fråga på Piazza
- På Piazza kan din fråga besvaras av assistenter och av andra studenter utanför labbtid. Gör gärna din fråga publik så att fler kan ta del av svaren!
- Googla problemet
- Att kunna hitta svaret på sina frågor på Internet är en av de viktigaste sakerna man måste lära sig som programmerare. Någon gång kommer du hamna i en situation där det inte finns någon annan att be om hjälp, och då är det bra att veta hur man letar själv.
- Börja om
- Det låter kanske konstigt, men ofta när man kör fast beror det på att man har lett in sig själv i en återvändsgränd. Var inte rädd att skriva om program (eller i alla fall delar av ett program) helt från början. Ta bort (eller flytta) gammal kod så att du inte ser den när du skriver den nya.
1.5 Om du redan “kan programmera”
De första två veckorna har vi valt att prioritera de som inte har programmerat mycket utanför tidigare kurser på IT/DV så att fler ska nå en nivå där det går att samarbeta och göra intressanta och roliga saker. Om du redan kan det som tas upp här kommer labbarna att gå snabbt. Om du stöter på något som tar längre tid så visade det sig att det fanns något för dig att lära dig ändå!
Blir du klar med uppgiften tidigt får du gärna hjälpa andra, men kom ihåg att poängen med att ge någon hjälp inte är att den andra ska bli klar så snabbt som möjligt utan denne ska lära sig så mycket som möjligt!
1.6 Att programmera med SIMPLE
Programming is about problem solving. Most time is spent thinking – and the time it takes to write down the outcome of the thinking, the banging on the keyboard, is only a small fraction of the time. Also note that the goal of this course is to teach programming – not programming in a specific language. We use C (and later Java) to illustrate concepts like how to think about problem decomposition, resource management, code quality etc. We could use different languages, but still teach the same (well, mostly) course.
How to transform a specification (or an idea or a task…) into a running program is something that many beginner programmer consider magical. Often, it feels like the solution should just magically appear, or be obvious. This is far from the truth. However, a finishied program rarely gives us any idea of all the intermediate steps – and buggy variants of the final program – that the programmers went through to get there.
As a guide to the personal programming process, we recommend following the steps of the SIMPLE programming methodology. It provides some good practises and introduces some key tricks that experienced programmers often use to incrementally approach a solution to a problem.
Even if you have programming experience from before, please take a look at SIMPLE!
2 Skillnader mellan Haskell och C
Skillnaderna mellan Haskell och C är så stora att de inte går att lista på ett vettigt sätt. Här fokuserar vi på några viktiga skillnader som brukar vara förvirrande i början. Läs detta först innan du sätter igång med labben!
2.1 Haskell är “lättjefullt” (lazy), C är ivrigt (eager)
Evaluering i Haskell följer normal order reduction vilket betyder att argument till en funktion evalueras när de behövs. Ponera följande enkla C-program som räknar ut summan av två kvadrater:
int square(int a) { return a * a; } int sum_of_squares(int a, int b) { return square(a) + square(b); } ... sum_of_squares(5 + 2, 6 * 7);
int%20square%28int%20a%29%20%7B%0A%20%20%20%20return%20a%20%2A%20a%3B%0A%7D%0Aint%20sum_of_squares%28int%20a%2C%20int%20b%29%20%7B%0A%20%20%20%20return%20square%28a%29%20%2B%20square%28b%29%3B%20%0A%7D%0A...%0Asum_of_squares%285%20%2B%202%2C%206%20%2A%207%29%3B%0A
I Haskell kan vi tänka på evaluering av detta program enligt följande:
sum_of_squares(5 + 2, 6 * 7); =>
square(5 + 2) + square(6 * 7); =>
((5 + 2) * (5 + 2)) + ((6 * 7) * (6 * 7)); =>
(7 * 7) + (42 * 42) =>
49 + 1764 =>
1813
Dvs. vi “knuffar” argument-uttrycken 5 + 2 och 6 * 7 “inåt” i uträckningen
tills vi inte längre kan fortsätta (progress) med mindre än att vi räknar ut
5 + 2 och 6 * 7. Så är inte fallet i C!
C använder applicative order reduction vilket betyder att vi först evaluerar alla argument till en funktion, innan vi kan anropa funktionen. I C kan skall vi alltså tänka på evaluering av programmet enligt följande:
sum_of_squares(5 + 2, 6 * 7); =>
sum_of_squares(7, 42); =>
square(7) + square(42); =>
(7 * 7) + (42 * 42) =>
49 + 1764 =>
1813
Som synes är resultatet detsamma – i detta fall! Men det är enkelt att konstruera program där ordningen i vilket argument utförs (eller inte utförs beroende på något villkor) påverkar resultatet.
2.2 C tillåter godtyckliga sido-effekter
I C kan en variabels värde ändras, t.ex. x = x + 1 är ett
uttryck som inte bara returnerar värdet på x + 1, utan ändrar
värdet på x så att nästa gång x läses av programmet har dess
värde ökat. Enkelt exempel:
int x = 42; // Nu är värdet på x 42 x = x + 1; // Evalueras till 43, värdet på x ändras nu till 43 x = x + 1; // Evalueras till 44, värdet på x ändras nu till 44
int%20x%20%3D%2042%3B%20%2F%2F%20Nu%20%C3%A4r%20v%C3%A4rdet%20p%C3%A5%20x%2042%0Ax%20%3D%20x%20%2B%201%3B%20%2F%2F%20Evalueras%20till%2043%2C%20v%C3%A4rdet%20p%C3%A5%20x%20%C3%A4ndras%20nu%20till%2043%0Ax%20%3D%20x%20%2B%201%3B%20%2F%2F%20Evalueras%20till%2044%2C%20v%C3%A4rdet%20p%C3%A5%20x%20%C3%A4ndras%20nu%20till%2044%0A
Konsekvensen av detta blir uppenbar om vi kombinerar detta med föregående punkt om lazy vs. eager. Ponera följande:
sum_of_squares(x = x + 1, x = x - 1);
sum_of_squares%28x%20%3D%20x%20%2B%201%2C%20x%20%3D%20x%20-%201%29%3B%0A
När vi inte har sidoeffekter spelar det ingen roll i vilken ordning
argumenten till sum_of_squares() evalueras, men med sidoeffekter är
det av största vikt. Ponera t.ex. att värdet på x är 1. Om x = x + 1 körs
före x = x - 1 blir resultatet 5, men i fallet då x = x - 1 körs först
blir resultatet 1. Det faktum att programmets beteende påverkas av när tilldelningar
till x görs är en anledning till (att vara tacksam för) att C är eager (applicative order reduction).
I C är det dessutom så att ordningen i vilken argumenten till en funktion utförs är s.k. implementation defined, vilket betyder att beteendet kan skilja sig mellan olika implementationer av C. Det betyder att man inte skall skriva program som gör som ovan under några som helst omständigheter!
Man skall överlag vara varsam med sidoeffekter, men det är något som kommer att komma upp både implicit och explicit under kursens gång.
2.3 Haskell är funktionellt, C är procedurellt och imperativt
I Haskell är en funktion en process som utför en “uträkning” givet ett eller flera argument, och returnerar ett resultat. De Haskell-program som ni har skrivit tar ofta följande form:
f(g(h(x) + 7))
dvs, resultatet av h(x) (plus 7) är argumentet till g och
resultatet är i sin tur argumentet till f. Ett C-program har
ofta formen (OBS! inte riktig C-kod och försöker inte vara
ekvivalent med programmet ovan):
y = h(x) y = y + 42 // notera att vi ändrar y:s värde här g() f(y)
dvs, varje sats i programmet avser ett diskret steg och vissa steg tar varken (synligen) input från tidigare steg eller ger output som skickas till efterföljande steg. Satsernas inbördes ordning i programmet är det som (implicit) länkar samman dem – inte något tillstånd som flödar in eller ut. Det betyder att vi måste vara mer uppmärksamma på detta i C-program.
Eftersom C inte är funktionellt finns det heller inget “krav” att
funktioner skall returnera något. Det är ganska vanligt att en
funktion inte har något returvärde (t.ex. en funktion som skriver
ut text i terminalen, men många andra). Ett tydligt exempel är att
if-villkoret i C inte returnerar något! Ett ganska vanligt
mönster i imperativa program är att använda if-satser utan
någon else-sats t.ex. så här (OBS! Inte valid C):
/// Make a copy of a file (source) to a new file name (dest) byte /// by byte, and return the number of bytes copied int clone_file(file source, file dest) { if (does_non_exist(source)) { // Source file does not exist! return 0; } if (exists(dest)) { // Destination already exists! return 0; } ... // now copy the file }
%2F%2F%2F%20Make%20a%20copy%20of%20a%20file%20%28source%29%20to%20a%20new%20file%20name%20%28dest%29%20byte%0A%2F%2F%2F%20by%20byte%2C%20and%20return%20the%20number%20of%20bytes%20copied%0Aint%20clone_file%28file%20source%2C%20file%20dest%29%20%7B%0A%20%20if%20%28does_non_exist%28source%29%29%20%7B%0A%20%20%20%20%2F%2F%20Source%20file%20does%20not%20exist%21%0A%20%20%20%20return%200%3B%0A%20%20%7D%0A%0A%20%20if%20%28exists%28dest%29%29%20%7B%0A%20%20%20%20%2F%2F%20Destination%20already%20exists%21%0A%20%20%20%20return%200%3B%0A%20%20%7D%0A%0A%20%20...%20%2F%2F%20now%20copy%20the%20file%0A%7D%0A
Observera att ingen av if-satserna ovan har en else-sats.
I båda fallen utför vi helt enkelt ett “test” och avbryter exekveringen
och returnerar 0 om testvillkoren är sanna. Vi kommer alltså enbart
till raden ... // now copy the file, om inget av testvillkoren
håller.
En progammerare med ett funktionellt “mind set” skulle förmodligen skriva programmet så här istället:
int clone_file(file source, file dest) { if (does_non_exist(source)) { // Source file does not exist! return 0; } else { if (exists(dest)) { // Destination already exists! return 0; } else { ... // now copy the file } }
int%20clone_file%28file%20source%2C%20file%20dest%29%20%7B%0A%20%20if%20%28does_non_exist%28source%29%29%20%7B%0A%20%20%20%20%2F%2F%20Source%20file%20does%20not%20exist%21%0A%20%20%20%20return%200%3B%0A%20%20%7D%20else%20%7B%0A%20%20%20%20if%20%28exists%28dest%29%29%20%7B%0A%20%20%20%20%20%20%2F%2F%20Destination%20already%20exists%21%0A%20%20%20%20%20%20%20return%200%3B%0A%20%20%20%20%7D%20else%20%7B%0A%20%20%20%20%20%20%20...%20%2F%2F%20now%20copy%20the%20file%0A%20%20%20%20%7D%0A%7D%0A
eller mer kompakt, eftersom resultatet av båda testerna råka vara detsamma i detta exempel:
int clone_file(file source, file dest) { if (does_non_exist(source) || exists(dest)) { // || means "or" // Source file does not exist or destination already exists! return 0; } else { ... // now copy the file } }
int%20clone_file%28file%20source%2C%20file%20dest%29%20%7B%0A%20%20if%20%28does_non_exist%28source%29%20%7C%7C%20exists%28dest%29%29%20%7B%20%2F%2F%20%7C%7C%20means%20%22or%22%0A%20%20%20%20%2F%2F%20Source%20file%20does%20not%20exist%20or%20destination%20already%20exists%21%0A%20%20%20%20return%200%3B%0A%20%20%7D%20else%20%7B%0A%20%20%20%20...%20%2F%2F%20now%20copy%20the%20file%0A%20%20%7D%0A%7D%0A
Observera att dessa versioner är likvärdiga och att det inte finns någon som är objektivt “bäst”. Det finns däremot många programmerare med starka åsikter som kommer att försöka påtvinga sina normer på dig och övertyga dig om att den stil som hen gillar bäst också råkar vara bäst.
3 Labb 1: Grundläggande koncept
På lab 5 kommer du att bli ombedd om att spara alla dina labbar på GitHub! Se därför till att inte kasta bort eller slarva bort någon fil innan dess!
3.1 Steg 1: Emacs-fix
Som du säkert vet kommer vi att använda Emacs som editor på kursen. (Notera att med Emacs avses också vi/vim.) Emacs är en utökningsbar editor som är skriven i C och programspråket Emacs-lisp. Man utökar och raffinerar sin egen Emacs genom ytterligare paket skrivna i Emacs-lisp. Man kan skriva dessa paket själv, eller ladda ned dem och installera dem själv eller via Emacs inbyggda pakethanterare.
Emacs-resurser på kurswebben:
Nu följer två olika uppsättningar instruktioner beroende på om du kör Linux eller OS X/macOS. För dig som kör Windows har vi tyvärr ingen handledning, men vi råder dig att installera Linux under kursens gång då det är en bättre programmeringsmiljö för den C-programmering som vi skall göra.
3.1.1 Linux
Om du vill installera Emacs på din egen Linux-maskin kan du pröva
t.ex. apt-get install emacs. Eventuellt med sudo före apt-get.
Kör emacs --version i terminalen. Om du har en yngre Emacs än
version 24 skall måste du uppgradera den för att nedanstående
skall fungera.
$ cd ~ $ mv .emacs .emacs.old # Not 1 nedan $ mkdir .emacs.d $ cd .emacs.d $ curl http://wrigstad.com/ioopm18/misc/emacs.zip -o e.zip # Not 2 nedan $ unzip e.zip $ rm -f e.zip
Not 1: Om filen .emacs inte finns får du fel i steg 2, men det
gör ingenting eftersom steg 2 handlar om att “bli av med den
filen”.
Not 2: Om du skriver fel i den långa URL:en ovan kommer du
fortfarande att få en fil e.zip men som inte går att packa upp.
Om unzip-steget inte fungerar – kontrollera din stavning i
curl-steget!
3.1.2 OS X/macOS
Kör emacs --version i terminalen. Om du har en Emacs som är
yngre än version 24 skall måste du uppgradera den för att
nedanstående skall fungera. Vid behov kan du ladda hem och
installera en okonfigurerad version från
https://emacsformacosx.com som är tillräckligt ny. Om du vill att
din nya version ska öppnas när du skriver emacs i terminalen kan
du skapa ett alias. Skriv följande i en terminal:
$ cd ~ # Gå till hemkatalogen $ emacs .bash_profile # Öppna din profil
I den öppnade filen, lägg till följande rad:
alias emacs=/Applications/Emacs.app/Contents/MacOS/Emacs
Spara och avsluta (C-x C-s C-x C-c) och kör ytterligare ett
kommando i terminalen:
$ source ~/.bash_profile
Nu kommer du att öppna Emacs i ett eget fönster när du skriver
emacs. Om du vill köra Emacs i terminalen kan du använda
kommandot emacs -nw.
För att skaffa kursens Emacs-konfiguration, kör nedanstående i en terminal.
$ cd ~ $ mkdir .emacs.d $ cd .emacs.d $ curl http://wrigstad.com/ioopm18/misc/emacs.zip -o e.zip $ unzip e.zip $ rm -f e.zip
Notera att om du skriver fel i den långa URL:en ovan kommer du
fortfarande att få en fil e.zip men som förstås inte går att
packa upp. Om unzip-steget inte fungerar – kontrollera din
stavning i curl-steget!
Om du installerar Emacs på macOS så är Alt din Meta-tangent. Det är inget fel med det, men avsaknaden av AltGr (en Mac har två Alt istället) gör att vissa tecken som är vanligt förekommande i programmering inte går att skriva:
[tolkas som kortkommandot M-8 och]som kortkommandot M-9.{tolkas som kortkommandot M-7 och}som kortkommandot M-0.$tolkas som kortkommandot M-4, etc.
Lösningen på detta är att lägga till följande i filen init.el
som finns i katalogen .emacs.d i din hemkatalog. Kopiera och
klistra in!
;; Teach Emacs Swedish keyboard layout (define-key key-translation-map (kbd "M-8") (kbd "[")) (define-key key-translation-map (kbd "M-9") (kbd "]")) (define-key key-translation-map (kbd "M-(") (kbd "{")) (define-key key-translation-map (kbd "M-)") (kbd "}")) (define-key key-translation-map (kbd "M-7") (kbd "|")) (define-key key-translation-map (kbd "M-/") (kbd "\\")) (define-key key-translation-map (kbd "M-2") (kbd "@")) (define-key key-translation-map (kbd "M-4") (kbd "$"))
%3B%3B%20Teach%20Emacs%20Swedish%20keyboard%20layout%0A%28define-key%20key-translation-map%20%28kbd%20%22M-8%22%29%20%28kbd%20%22%5B%22%29%29%0A%28define-key%20key-translation-map%20%28kbd%20%22M-9%22%29%20%28kbd%20%22%5D%22%29%29%0A%0A%28define-key%20key-translation-map%20%28kbd%20%22M-%28%22%29%20%28kbd%20%22%7B%22%29%29%0A%28define-key%20key-translation-map%20%28kbd%20%22M-%29%22%29%20%28kbd%20%22%7D%22%29%29%0A%0A%28define-key%20key-translation-map%20%28kbd%20%22M-7%22%29%20%28kbd%20%22%7C%22%29%29%0A%28define-key%20key-translation-map%20%28kbd%20%22M-%2F%22%29%20%28kbd%20%22%5C%5C%22%29%29%0A%0A%28define-key%20key-translation-map%20%28kbd%20%22M-2%22%29%20%28kbd%20%22%40%22%29%29%0A%28define-key%20key-translation-map%20%28kbd%20%22M-4%22%29%20%28kbd%20%22%24%22%29%29%0A
Tips: klistra in i Emacs är C-y. För att slippa starta om
Emacs för att inställningarna skall gälla kan du markera den
inklippta texten och köra M-x eval-region.
3.2 Steg 2: Setup
Nu är det dags att skapa en katalog för kursen i din hemkatalog på
Linux-maskinerna (eller på din egen dator, eller båda). Ett
lämpligt namn för denna katalog är ioopm. Sedan skall vi skapa en
underkatalog lab1, en tom fil hello.c i den och starta Emacs
för att editera filen.
$ cd ~ # gå till din hemkatalog $ mkdir ioopm # skapa underkatalogen ioopm $ cd ioopm # gå in i ioopm-katalogen $ mkdir lab1 # skapa underkatalogen lab1 $ cd lab1 # gå in i lab1-katalogen $ touch hello.c # skapa en tom fil hello.c $ emacs hello.c & # starta Emacs för att editera filen $
Om du kör på institutionens Linux och inte har gjort någon egen
konfigurering kan du växla mellan program med Alt+Tab. Vi kommer
att använda editorn för att skriva text och terminalen för
att kompilera och köra programmet. Pröva att växla några gånger
mellan programmen.
Om du använder förstersystemet Gnome (standard på t.ex. Ubuntu)
kan du använda Ctrl+Win+vänsterpil för att maximera det aktuella
fönstret på skärmens vänstra halva och motsvarande för den högra.
Det är ett bra sätt att ha både terminalen och editorn så att man
kan se all information alltid.
Nu är du redo att börja med labben!
Var noga med att spara en version av varje färdigt program! Ta för vana att experimentera i en ny fil som du antingen skapar tom eller kopierar från en som fungerar.
3.3 Hello, world!
Det klassiska första programmet att skriva i varje programspråk är “Hello, world!”
Börja med att skapa filen hello.c så här: C-x C-f
hello.c. Tangentbordskombinationen C-x C-f i Emacs är
bunden till funktionen find-file som alltså öppnar en fil, eller
skapar en fil – om filen inte finns. För att spara filen trycker
du C-x C-s som är bunden till funktionen save-buffer som
sparar innehållet i den buffer som du editerar i, i den fil som
den är knuten till.
Det finns många sätt att skriva detta program. Ett enkelt sätt är:
#include <stdio.h> int main(void) { puts("Hello, world!"); return 0; }
%23include%20%3Cstdio.h%3E%0A%0Aint%20main%28void%29%0A%7B%0A%20%20puts%28%22Hello%2C%20world%21%22%29%3B%0A%20%20return%200%3B%0A%7D%0A
Skriv av (eller kopiera, men ännu hellre skriv av) programmet ovan
i en editor och döp det till hello.c. Alla C-program startar i
funktionen main() (aka “main()-funktionen”) som är en funktion
som returnerar ett heltal som berättar för det underliggande
operativsystemet om körningen av programmet gick bra. Tillsvidare
returnerar vi alltid 0.
Kompilera programmet med gcc hello.c – nu skapas filen a.out
som du kör så här: ./a.out. Så här kan det se ut i terminalen:
$ emacs hello.c & # startar Emacs $ gcc hello.c # kompilerar hello.c $ ls # listar filerna i terminalen a.out hello.c $ ./a.out # kör a.out Hello, world! # programmets output $ _ # väntande kommandoprompt
Funktionen puts() skriver ut en sträng på terminalen (puts = “put
string”). Låt oss nu experimentera med att använda funktionen
printf(). Denna funktion tar ett variabelt antal argument. Börja
med att ändra puts("Hello, world!"); till printf("Hello,
world!");, kompilera om och kör programmet igen. Kan du se någon
skillnad?
Skillnaden är add printf() inte automatiskt skriver ut en
radbrytning efter utskriften. Sätt dit det genom att skriva
\n efter !, dvs. printf("Hello, world!\n");.
Funktionerna puts() och printf() är två helt olika funktioner.
Den första skriver ut en enskild sträng medan den andra kan
användas för att skriva ut en mängd olika saker: strängar, heltal,
flyttal, minnesadresser etc.
Pröva gärna att titta på skillnaden mellan puts() och
printf() genom att skriva man puts och man printf i
terminalen och titta på manualsidorna för funktionerna. Du
scrollar med mellanslag och avslutar med q. (Du kan skriva
man pager för att läsa vilka kortkommandon som finns för att
läsa manualsidor med man-kommandot. Du kan också skriva man man
för att få veta mer om man-kommandot.)
Pröva att ändra utskriften så här:
char *msg = "Hello, world!"; int year = 2019; printf("%s in the year %d\n", msg, year);
char%20%2Amsg%20%3D%20%22Hello%2C%20world%21%22%3B%0Aint%20year%20%3D%202019%3B%0Aprintf%28%22%25s%20in%20the%20year%20%25d%5Cn%22%2C%20msg%2C%20year%29%3B%0A
Vi deklarerar nu en variabel msg som är en sträng (i C är
typen för sträng char *, mer om detta senare) vars innehåll är
texten “Hello, world!” och en variabel year som innehåller
heltalet 2019. (Minns att en typ är ett namn på en samling värden
som delar vissa egenskaper. I C har vi t.ex. en typ för heltal, en
för flyttal, etc.)
Sedan säger vi åt printf() att skriva ut en sträng (%s) följt
av texten “ in the year ”, följt av ett heltal (%d) följt av en
radbrytning (\n). Sedan skickar vi med msg och year – i samma
ordning som %s och %d (vad händer om du råkar byta plats på dem?).
Observera att printf() nu tar 3 argument. Funktionen tar alltid
in en formatsträng (i vårt exempel "%s in the year %d\n") och
sedan ytterligare ett argument för varje “styrkod” (%s och %d
i detta exempel) som finns med i formatsträngen.
Från Haskell är du van vid att man binder namn till värden, t.ex.
let x = 5 in BLAHRG. Där är x en konstant vars värde är 5.
När vi har denna typ av namnbindningar kan vi söka och ersätta
alla förekomster av x med 5 i BLAHRG och få samma resultat.
Variabler i C fungerar annorlunda i och med att deras värden kan
ändras! int x = 5; ... betyder att vi har skapat ett namn, x,
som avser ett heltal, som initialt är 5, men som kan komma att
ändra värde. Om ... ovan t.ex. är
printf("%d\n", x); x = 42; printf("%d\n", x);
printf%28%22%25d%5Cn%22%2C%20x%29%3B%0Ax%20%3D%2042%3B%0Aprintf%28%22%25d%5Cn%22%2C%20x%29%3B%0A
kommer första utskriften av x att bli 5 och den andra 42.
3.3.1 Mini-övning
Skriv av följande program och ändra ... till kod som byter plats
på värdena i variablerna x och y genom att tilldela dem till varandra (din lösning kan alltså inte vara t.ex. x = 2; y = 1;):
#include <stdio.h> int main(void) { int x = 1; int y = 2; printf("x = %d\n", x); printf("y = %d\n", y); puts("====="); ... printf("x = %d\n", x); printf("y = %d\n", y); return 0; }
%23include%20%3Cstdio.h%3E%0A%0Aint%20main%28void%29%0A%7B%0A%20%20int%20x%20%3D%201%3B%0A%20%20int%20y%20%3D%202%3B%0A%20%20printf%28%22x%20%3D%20%25d%5Cn%22%2C%20x%29%3B%0A%20%20printf%28%22y%20%3D%20%25d%5Cn%22%2C%20y%29%3B%0A%20%20puts%28%22%3D%3D%3D%3D%3D%22%29%3B%0A%20%20...%0A%20%20printf%28%22x%20%3D%20%25d%5Cn%22%2C%20x%29%3B%0A%20%20printf%28%22y%20%3D%20%25d%5Cn%22%2C%20y%29%3B%0A%20%20return%200%3B%0A%7D%0A
Tips Använd en tredje variabel tmp för att “komma ihåg”
värdet på x så att du kan skriva över x med y och sen y
med tmp. Var noggrann med skillnaden mellan int x = 1, som
introducerar en ny variabel x med värdet 1, och x = 1, som
ändrar värdet på en existerande variabel x till värdet 1.
Om du gjort rätt borde programmet ge följande output när du kompilerar och kör det:
$ gcc swap.c $ ./a.out x = 1 y = 2 ===== x = 2 y = 1
Använd tab-tangenten för att indentera kod! Du kommer att märka att Emacs kommer att göra “rätt” (naturligtvis beroende på vad rätt är – och allt går att konfigurera!) så att du slipper tänka på hur många mellanslag etc. Pröva gärna att markera flera rader och trycka tab.
Förresten, du kan markera utan mus! Tryck C-<space> för att börja markera och flytta sedan markören med tangentbordet som vanligt.
3.4 Skriv ut talföljden 1–10
Skriv ett program p1 som, när det körs, skriver ut talen 1 till 10 så här:
$ gcc p1.c $ ./a.out 1 2 3 4 5 6 7 8 9 10
Du ska använd en for-loop och kan utgå från följande
programskelett:
#include <stdio.h> int main(void) { int i = 1; // deklaration och initiering av iterationsvariabeln while (i <= 10) // iterationsvillkor (utför blocket så länge i är mindre än 11) { // loop-kropp (utförs så länge iterationsvillkoret är uppfyllt) printf("%d\n", 1); // skriv ut 1, och en radbrytning i = i + 1; // öka i:s värde med 1 (förändring av iterationsvariabeln) } return 0; }
%23include%20%3Cstdio.h%3E%0A%0Aint%20main%28void%29%0A%7B%0A%20%20int%20i%20%3D%201%3B%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20deklaration%20och%20initiering%20av%20iterationsvariabeln%0A%20%20while%20%28i%20%3C%3D%2010%29%20%20%20%20%20%20%20%20%20%2F%2F%20iterationsvillkor%20%28utf%C3%B6r%20blocket%20s%C3%A5%20l%C3%A4nge%20i%20%C3%A4r%20mindre%20%C3%A4n%2011%29%0A%20%20%7B%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20loop-kropp%20%28utf%C3%B6rs%20s%C3%A5%20l%C3%A4nge%20iterationsvillkoret%20%C3%A4r%20uppfyllt%29%0A%20%20%20%20printf%28%22%25d%5Cn%22%2C%201%29%3B%20%20%20%20%2F%2F%20skriv%20ut%201%2C%20och%20en%20radbrytning%0A%20%20%20%20i%20%3D%20i%20%2B%201%3B%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20%C3%B6ka%20i%3As%20v%C3%A4rde%20med%201%20%28f%C3%B6r%C3%A4ndring%20av%20iterationsvariabeln%29%0A%20%20%7D%0A%20%20return%200%3B%0A%7D%0A
Om du trycker på den vänstra knappen ovan som tar dig till
PyTutor kan du stega genom programmet steg för steg och se hur
värdet på i växer. De flesta kompletta programexempel på dessa
webbsidor har en länk till PyTutor.
Detta program är trasigt: det skriver ut 1 hela tiden. Börja med att
fixa det (ledning: titta anropet till printf()), och skriv sedan om
while-loopen med en for-loop som har följande syntax:
for ( deklaration och initiering av iterationsvariabel ; iterationsvillkor ; förändring av iterationsvariabel ) { loop-kropp }
for%20%28%20deklaration%20och%20initiering%20av%20iterationsvariabel%20%3B%0A%20%20%20%20%20%20iterationsvillkor%20%3B%0A%20%20%20%20%20%20f%C3%B6r%C3%A4ndring%20av%20iterationsvariabel%20%29%0A%20%20%7B%0A%20%20%20%20loop-kropp%0A%20%20%7D%0A
Det så-kallade preprocessormakrot #include <stdio.h> talar om
för C-kompilatorn att vi vill använda standardbiblioteket för
input/output, som alltså heter stdio. Filen stdio.h som finns
någonstans i filsystemet innehåller deklaration av funktioner och
datatyper som blir tillgängliga i och med att man skriver
#include <stdio.h> i den fil som vill använda biblioteket.
3.5 Skriv ut talföljden 10–1
Kopiera programmet p1.c ovan till p2.c4 och skriv om det så att talföljden går ned från 10
till 1 istället:
$ gcc p2.c $ ./a.out 10 9 8 7 6 5 4 3 2 1
3.6 Nästade loopar
Nu skall vi experimentera med nästade loopar, dvs. loopar vars
loopkroppar innehåller loopar. Kopiera p1.c till p3.c och
skriv om programmet så att det istället för tal skriver ut en
ökande mängd *. Sist skall det skrivas ut hur många *
(asterisker) som skrev ut:
$ gcc p3.c $ ./a.out * ** *** **** ***** ****** ******* ******** ********* ********** Totalt: 55 $ _
Skriva ut N stycken * kan enkelt göras med en loop som i N
varv skriver ut ett * i varje varv utan efterföljande
radbrytning.
Ett program ska ofta göra mer än en sak. Börja aldrig med att
försöka skriva hela programmet på en gång. Om du inte kan skriva
en enskild loop som skriver ut N stycken * så kommer du inte
kunna skriva ett program som skriver ut 1 till N stycken *.
Försök alltid hitta delproblemen och lös dem var och en för sig.
Här är ett förslag på delproblemen för den här uppgiften som alla kan lösas en i taget:
- Skriv en loop som itererar från 1 till 10 (redan löst i
p1.c). - Skriv en loop som skriver ut N stycken asterisker (för något värde på N).
- Ändra loopen i 1. så att asterisker skrivs ut istället för tal (använd loopen från 2.).
- Skriv ut summan av alla utskrivna asterisker (
*).
3.7 Kommandoradsargument 1/2
Kopiera p3.c till p4.c – nu skall vi utöka programmet så att
det går att skicka in antalet staplar som skall skrivas ut, samt
hur snabbt staplarna skall växa. Här är tre exempelkörningar av
programmet:
$ gcc p4.c $ ./a.out 3 2 ** **** ****** Totalt: 12 $ ./a.out 0 25 Totalt: 0 $ ./a.out 4 4 **** ******** ************ **************** Totalt: 40 $ ./a.out Usage: ./a.out rows growth $ _
Kommandoradsargument skickas automagiskt in som argument till
main()-funktionen. Vi kan skriva programmet eko så här (som
bara “ekar” alla kommandoradsargument):
#include <stdio.h> int main(int argc, char *argv[]) { for (int i = 0; i < argc; ++i) { puts(argv[i]); } return 0; }
%23include%20%3Cstdio.h%3E%0A%0Aint%20main%28int%20argc%2C%20char%20%2Aargv%5B%5D%29%0A%7B%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20argc%3B%20%2B%2Bi%29%0A%20%20%7B%0A%20%20%20%20puts%28argv%5Bi%5D%29%3B%0A%20%20%7D%0A%20%20return%200%3B%0A%7D%0A
Observera nu att main()-funktionens signatur ser annorlunda ut. Två
nya parametrar har lagts till:
int argc– heltaletargcsom håller reda på hur många argument som skickades inchar *argv[]– en array av strängar som motsvarar kommandoradsargumenten
Minns att char * är C:s strängtyp – det efterföljande [] visar
att argv inte är bara en sträng, utan en hel array av strängar.
Minns att en array är som en lista – dvs. en sekvens av
värden, men till skillnad från en lista (i t.ex. Haskell) kan en
array inte utökas. Om arrayen arr är en array med tre element
kan vi komma åt element 1 med arr[0], element 2 med arr[1] och
element 3 med arr[2]. Om vi skriver arr[3] för att komma åt
det 4:e elementet är resultatet skräp, och exakt vad det betyder
kan variera mellan olika implementationer av kompilatorer, etc.
Det är alltså något som vi skall undvika, men som kompilatorn inte
skyddar oss emot.
Arrayer indexeras från 0 i C (och många andra programspråk), dvs.
puts(argv[0]) skriver ut den första strängen i argv. argv[0]
= "Ivor Cutler" gör så att den första strängen i argv-arrayen
blir strängen “Ivor Cutler”.
När programmet ovan körs skriver det ut sina kommandoradsargument så här:
$ gcc eko.c $ ./a.out hej hopp fallera 42 ./a.out hej hopp fallera 42 $ _
I ovanstående körning anropas main()-funktionen med argc = 5
och argv = ["./a.out", "hej", "hopp", "fallera", "42"].
Observera att den första strängen i argv alltid är det namn som
man använde för att starta programmet – alltså ./a.out i alla
våra exempel hittills.
Observera att "42" är en sträng och att 42 är ett heltal – de
är alltså olika datatyper som inte är kompatibla. Man
kan konvertera strängen "42" till talet 42 med hjälp av
funktionen atoi():
char *str = "42"; int num = atoi(str); printf("%s == %d?\n", str, num);
char%20%2Astr%20%3D%20%2242%22%3B%0Aint%20num%20%3D%20atoi%28str%29%3B%0Aprintf%28%22%25s%20%3D%3D%20%25d%3F%5Cn%22%2C%20str%2C%20num%29%3B%0A
atoi() står för ASCII to Integer. (En av anledningarna till
att namnen på många funktioner är så korta och usla är att man i
förhistorisk tid kunde tjäna många sekunder på att slippa skicka
“onödiga” tecken över väldigt långsamma linor när man skulle
programmera via terminaler. Det är inte en giltig anledning
längre, men det är svårt att ändra 30+ år gamla standardbibliotek
som regleras av trögrörliga standardiseringsorgan.)
För att använda atoi() måste programmet inkludera
standardbiblioteket stdlib.h:
#include <stdio.h> // stod redan #include <stdlib.h>
%23include%20%3Cstdio.h%3E%20%20%20%2F%2F%20stod%20redan%0A%23include%20%3Cstdlib.h%3E%0A
(Senare skall vi skriva en funktion som konverterar från ett heltal till en sträng.)
I körningsexemplet ovan detekterar programmet om det körs utan några argument (eller – mer korrekt – utan andra argument än programmets namn) och skriver i så fall ut en hjälptext:
Usage: ./a.out rows growth
Vi kan använda en if-sats för att kontrollera om antalet
argument är felaktigt.
if (antalet argument < 2 || antalet argument > 3) { skriv ut felmeddelande } else { utför uppgiften }
if%20%28antalet%20argument%20%3C%202%20%7C%7C%20antalet%20argument%20%3E%203%29%0A%7B%0A%20%20skriv%20ut%20felmeddelande%0A%7D%0Aelse%0A%7B%0A%20%20utf%C3%B6r%20uppgiften%0A%7D%0A
Den märkliga ||-symbolen är ett logiskt eller dvs. a || b är
sant om a är sant, eller om b är sant, eller om båda är sanna.
Nu kan du skriva klart programmet!
Betänk följande:
- Arrayer indexeras från 0
argv[0]är programmets namn- Programmet blir lättare att läsa och förstå om du sparar
argv[1]ochargv[2]i variabler med vettiga namn. - Programmet klarar inte av kommandoradsargument som inte är tal
Du kan använda M-g g för att hoppa till en speciell rad i
bufferten. M-g g 42 <ret>.
3.8 Primtalstest
Med hjälp av vad vi lärt oss hittills kan vi nu skriva ett enkelt
program som tar emot ett tal som kommandoradsargument och avgör om
det är ett primtal. Utgå från p4.c och kopiera det till p5.c.
En enkel algoritm för att kontrollera om talet N är ett primtal
är att pröva om x * y = N för alla kombinationer av x och
y i intervallet 2 till N. Om det inte går att hitta ett sådant
x anser vi att N är ett primtal. Två tal kan jämföras med
operatorn ==, t.ex. så här:
if (a == b) { puts("Lika"); } else { puts("Inte lika"); }
if%20%28a%20%3D%3D%20b%29%0A%7B%0A%20%20puts%28%22Lika%22%29%3B%0A%7D%0Aelse%0A%7B%0A%20%20puts%28%22Inte%20lika%22%29%3B%0A%7D%0A
Ett vanligt nybörjarfel är att man blandar ihop a == b, som
kontrollerar om a och b har samma värde, med a = b som
skriver värdet av b till variabeln a. Det är ett svårt fel att
upptäcka i början, så var försiktig!
Med en nästad loop kan du prova alla kombinationer av x och y
genom att räkna ut 2*2, 2*3, …, 2*(N-1), 3*2, 3*3…
och se om någon produkt är lika med N.
En optimering av algoritmen ovan är att inte växa x högre än
roten av N. Roten av N kan räknas fram med
biblioteksfunktionen sqrt(). Optimeringar kan vi göra först när
vi fått en första version av programmet att fungera.
Om du har problem med att kompilera program med sqrt()
i för att en sådan funktion inte finns, lägg till -lm till
kompileringen. Det betyder “länka mot matematikbiblioteket”,
dvs. sök också i matematikbiblioteket efter funktioner som
programmet kan vilja använda.
float roten_ur_n = sqrt(N);
float%20roten_ur_n%20%3D%20sqrt%28N%29%3B%0A
För att använda sqrt() måste programmet inkludera
matematikbiblioteket math.h på samma sätt som du inkluderat
stdio.h och stdlib.h tidigare: #include <math.h>.
Notera att sqrt() returnerar ett flyttal. Hjälpfunktionen
floor() skapar ett heltal från ett flyttal och avrundar nedåt.
Gränsen för x blir därför:
float tmp = sqrt(N); int limit = floor(tmp) + 1;
float%20tmp%20%3D%20sqrt%28N%29%3B%0Aint%20limit%20%3D%20floor%28tmp%29%20%2B%201%3B%0A
Det går också att skriva detta program utan variabeln tmp. (Gör gärna det – här ville vi lyfta fram de två delstegen.)
Skriv klart programmet och testa det:
$ gcc p5.c $ ./a.out 7 7 is a prime number $ ./a.out 2 2 is a prime number $ ./a.out 4 4 is not a prime number
Anser programmet att 1 är ett primtal? Anser programmet att 0 är ett primtal?
3.9 Största gemensamma delare (GCD)
Skriv nu ett program som tar emot två positiva tal och skriver ut deras största gemensamma delare med hjälp av Euklides algoritm:
gcd(a, b) = a om a = b gcd(a, b) = gdc(a - b, b) om a > b gcd(a, b) = gdc(a, b - a) om a < b
Använd en while-loop eller en for-loop för att lösa
problemet. Varje varv i loopen kommer variabeln a eller
variabeln b att ändra värde beroende på vilken som innehåller det
största värdet. Till slut är de lika och då har vi svaret.
Du kan utgå från p5.c och skapa p6.c eller skriva programmet
från grunden. Så här skall en exempelkörning av programmet se ut:
$ gcc p6.c $ ./a.out 40 12 gcd(40, 12) = 4
Använd printf() för utskriften. Minns att %d är styrkoden för
heltal och %s är styrkoden för strängar.
Tips på jämförelseoperatorer:
a == b // sant om a och b innehåller samma värde a != b // sant om a och b inte innehåller samma värde a < b // sant om a:s värde är strikt mindre än b:s värde a > b // sant om a:s värde är strikt större än b:s värde
Boolesk algebra i C:
!a // sant om a är falskt a && b // sant om både a och b är sanna a || b // sant om a och/eller b är sanna/sant
Vi kan nu beskiva ytterligare C-operatorer i termer av de vi redan sett:
a <= bär logiskt ekvivalent meda < b || a == ba >= bär logiskt ekvivalent meda > b || a == ba != bär logiskt ekvivalent med!(a == b)alternativta < b || a > ba == bär logiskt ekvivalent med!(a < b || a > b)alternativt!(a < b) && !(a > b)
Tips på sätt att manipulera numeriska variabler:
a = a - 1ändrar värdet påatill 1 mindre än vad det var innana -= 1är ekvivalent med ovanståendea--och--aminskar värdet påamed 1 på samma sätt, men har subtila skillnader – tills vidare bör du enbart använda dem för sido-effekter (om alls!)- Motsvarande finns för addition
+=och++ *=och/=existerar även för multiplikation och division
Frivilliga extrauppgifter:
- Detektera att programmet används korrekt – exakt två positiva tal skickas in
- Utöka programmet med stöd för hantering av negativa tal
3.10 Kontrollera om en sträng är ett tal redovisas
Nu har det blivit dags för oss att skriva vår första funktion (förutom
main()-funktionen då) – vilket vi kommer att ägna oss åt under nästa
labb. Vi skall skriva funktionen is_number() som tar emot en sträng
(char *) och returnerar en boolean (bool) – true om den inskickade
strängen är ett positivt eller negativt tal, annars false.
Av historiska skäl måste stöd för booleaner inkluderas explicit i C på följande sätt:
#include <stdbool.h>
%23include%20%3Cstdbool.h%3E%0A
Genom detta bibliotek får du tillgång till datatypen bool samt
konstanterna true och false. (Nästan alla värden i C går att
konvertera till sanningsvärden, även om det ofta inte är
semantiskt vettigt. 0 är falskt och alla andra värden är sanna.
Konverteringen sker automatiskt, så bool b = 1; är logiskt
ekvivalent med bool b = true; även om det är vansinnig kod att
skriva.)
Skapa en ny fil temp.c med en tom main()-funktion med
kommandoradsargumenten i (du kan kopiera texten från högre upp på
denna sida). Inkludera stdlib.h, stdio.h och stdbool.h med
#include-direktivet. Ovanför main()-funktionen, skriv in
följande:
bool is_number(char *str) { return false; }
bool%20is_number%28char%20%2Astr%29%0A%7B%0A%20%20return%20false%3B%0A%7D%0A
Du har nu deklarerat en funktion, is_number(), som tar emot en
sträng och returnerar ett sanningsvärde – ett booleskt värde (aka
“en boolean”). Funktionens kropp är just nu tom, så när som på
satsen return false, vilket innebär att funktionen alltid svarar
med falskt. Detta är en s.k. dummy eller stub, dvs. en funktion vars
existens är explict men vars implementation ännu inte är skriven.
Den innehåller bara minimalt med kod för att den skall vara legal
enligt C-kompilatorn, och då är vi konservativa, dvs. ingen sträng
är ett tal. Som kropp i main() kan vi skriva följande:
if (argc > 1 && is_number(argv[1])) { printf("%s is a number\n", argv[1]); } else { if (argc > 1) { printf("%s is not a number\n", argv[1]); } else { printf("Please provide a command line argument!\n"); } }
if%20%28argc%20%3E%201%20%26%26%20is_number%28argv%5B1%5D%29%29%0A%7B%0A%20%20printf%28%22%25s%20is%20a%20number%5Cn%22%2C%20argv%5B1%5D%29%3B%0A%7D%0Aelse%0A%7B%0A%20%20if%20%28argc%20%3E%201%29%0A%20%20%7B%0A%20%20%20%20printf%28%22%25s%20is%20not%20a%20number%5Cn%22%2C%20argv%5B1%5D%29%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20printf%28%22Please%20provide%20a%20command%20line%20argument%21%5Cn%22%29%3B%0A%20%20%7D%0A%7D%0A
Pröva nu att kompilera och köra programmet:
$ gcc temp.c $ ./a.out 42 42 is not a number $ _
Perfekt! Nu har vi något som “fungerar” men som gör fel, och vår uppgift nu är att modifiera detta program tills det gör rätt.
Det är viktigt att alltid ha ett fungerande program så att det går att experimentera sig fram till en lösning. Så arbetar såväl nybörjade som experter – ingen tycker att det är en bra idé att skriva 10 rader kod mellan varje kompilering, även om värdet på 10 varierar mellan personer och ofta stiger något med erfarenhet med den aktuella kodbasen.
En sträng i C är en array av tecken och varje tecken representeras
som ett heltal (ASCII-värdet för tecknet). Sist i en välformad
sträng kommer ett s.k. “nulltecken”, som har värdet 0, och som
avser att “nu är strängen slut”. Strängen "Hej" i C innehåller
alltså 4 tecken: ['H', 'e', 'j', '\0'] (skrivet som en array av
teckenliteraler) eller [72, 101, 106, 0] (skrivet som en array av
ASCII-värden).
Ett enkelt sätt att kontrollera om en sträng är ett (hel)tal är
att inspektera om varje tecken i strängen är en siffa (0-9),
förutom det första tecknet som också kan vara ett minustecken -.
- Funktionen
strlen()i biblioteketstring.h(#include <string.h>) returnerar längden av en sträng (med eller utan nulltecknet? Utforska!) - Funktionen
isdigit()i biblioteketctype.htestar om ett enskilt tecken är en siffra - Implementera testet med hjälp av en loop från
i=0till längden av strängen (utan nulltecknet) - Minns att
str[42]läser ut det 43:e tecknet från arrayenstr
Nu har du nog med information för att skriva programmet! När du
fått det att fungera, kopiera funktionen (och import-satser) över
in i p6.c och använd funktionen för att kontrollera att
kommandoradsargumenten är heltal. Lägg också in en kontroll att
de inte är negativa (dvs. tal >= 0). Denna kontroll skall inte
ske i is_number() eftersom is_number() stöder negativa tal.
Om funktioners ordning i filen
Som du har märkt har du blivit instruerad att placera funktioner
högre upp i filen än där de anropas. C-kompilatorn läser filen i
radordning, och om den inte först har sett en funktions
deklaration så kan den inte kontrollera att anropen till den
är korrekta, till exempel med avseende på antalet parametrar.
Redan i nästa labb skall vi se hur man kan komma runt detta med
så-kallade header-filer.
Om return-satsen
Alla funktioner i C vars returtyp inte är void måste returnera
ett värde explicit med hjälp av return-satsen, varvid funktionen
omedelbart avbryts. Det är därmed tillåtet för en funktion att ha
flera return-satser utan att det blir tveksamt vad funktionen
returnerar. Även funktioner vars returtyp är void kan ha en “tom”
return-sats: return;. Detta avbryter funktionen men returnerar
inget värde.
Felaktigt användande av return kan leda till död kod, dvs. kod
som aldrig kommer att utföras, t.ex.:
int dead_code_example() { return 17; // Här avbryts funktionen puts("This string will never be printed"); // denna rad körs aldrig }
int%20dead_code_example%28%29%0A%7B%0A%20%20return%2017%3B%20%2F%2F%20H%C3%A4r%20avbryts%20funktionen%0A%20%20puts%28%22This%20string%20will%20never%20be%20printed%22%29%3B%20%2F%2F%20denna%20rad%20k%C3%B6rs%20aldrig%0A%7D%0A
Det är viktigt att hitta död kod och ta bort den av flera skäl – inte minst säkerhet!
Du kan använda M-i för att navigera till vilken funktion som helst i filen. Pröva!
3.11 Extrauppgifter
För dig som är tidigt färdig eller känner att du vill arbeta mer med materialet.
3.11.1 Egen isdigit
Du kan implementera din egen isdigit() genom att kontrollera att
det inskickade tecknet c är '0' <= c && c <= '9'. Notera
skillnaden mellan '0' som är tecknet ’0’, och 0 som är
heltalet 0. Glöm inte att ta bort importen av ctype.h eller
döpa din funktion (t.ex. till is_digit()) så att namnet inte
krockar med ctype.h:s funktion.
Observera: du måste skriva din isdigit() ovanför is_number().
3.11.2 Fibonacci
Skriv ett program fib.c som skriver ut de första N talen i Fibonacciserien.
N skickas in som ett kommandoradsargument som vanligt.
$ gcc fib.c $ ./a.out 10 0 1 1 2 3 5 8 13 21 34 $ _
Fibonacciserien definieras så här:
fib(0) = 0 fib(1) = 1 fib(i) = fib(i-1) + fib(i - 2) om i >= 2
Som synes är definitionen av fib() rekursiv – men vi skall implementera
den med hjälp av en loop. Använd två variabler a och b som
sätts till 0 respektive 1.
För att räkna ut fib(3), utför följande beräkning i en loop:
- räkna ut summan av
aochb - sätt
atill värdet påb - sätt
btill summan i (1) - skriv ut
b
För att räkna ut fib(4) kan vi fortsätta på samma sätt eftersom
a innehåller värdet på fib(2) och b innehåller värdet på
fib(3), etc.
Generalisera detta i en loop så att det går att räkna ut godtyckliga Fibonaccital.
3.12 Heltalsvariablernas ändlighet
Här behandlas den “vita lögnen” ovan om “en typ för heltal […]”.
Hittills har vi använt typen int som en heltalsvariabel. Under
programmets körning sparas en int som ett binärt tal i ett
utrymme som är lika stort som ett maskinord, dvs. 32 eller 64
bitar beroende på vilken typ av dator man sitter på. Antalet bitar
styr (naturligtvis) hur stora tal som ryms i variabeln. En
32-bitars int har som maxvärde 2^31-1 och minvärde -2^31.
- Hur stor är en
intpå datorn du sitter på? Du kan pröva detta genom att lägga till#include <limits.h>överst i filen och sedan göraprintf("%d\n%d\n", INT_MIN, INT_MAX); - En
unsigned inthar endast positiva värden och - Pröva vad som händer om du sparar ett för stort tal i en
heltalsvariabel! (T.ex. genom att räkna ut ett för stort tal med
fib-programmet.)
Datatypen long rymmer större tal (se LONG_MAX).
I modern C använder vi ofta datatyper vars storlek är garanterad
oavsett vilken plattform vi sitter på. Om du inkluderar #include <stdint.h>
i dina program får du tillgång till typer som:
int64_tett heltal som är garanterat att vara 64 bitar stortuint64_tett “unsigned” heltal som är garanterat att vara 64 bitar stort (och alltså bara sparar positiva tal)int8_tett heltal som är garanterat att vara 8 bitar stort- etc.
Liknande gäller för flyttal. Analogt med int och long finns
float och double, samt ytterligare bibliotek för flyttalsberäkningar
enligt olika standarder.
4 Labb 2: I/O och funktioner
4.1 Varningar
Från och med den här labben kommer vi att använda flaggan -Wall
(show all warnings) varje gång vi kompilerar. Det berättar för
kompilatorn att den ska ge varningar för fler saker än vanligt.
Var vaksam om du får en varning från kompilatorn. Även om felet
inte alltid ligger precis där kompilatorn varnar så betyder en
varning att någonting är fel i programmet, eller borde skrivas
om. Om man tar för vana att inte fixa “ofarliga varningar” kommer
det att vara svårare att hitta “de farliga varningarna” i allt
mummel som kompilatorn spottar ur sig. (Läs mer om att kompilera C-program här!)
Goda vanor är enklast att etablera om man tar de till sig redan från start: Åtgärda alltid varningar innan du går vidare.
4.2 Debugging
Ingen människa skriver felfria program direkt. Ibland kan ett
program kompilera men ändå göra fel eller krascha, och det är inte
alltid lätt att hitta vad som orsakar en bugg. Ett verktyg som kan
användas för att hitta buggar i ett körande program kallas för en
“debugger” (på stolpig svenska kallas de ibland för “avlusare”).
Program skrivna i C kan “debuggas” med programmet gdb (eller
lldb om du kör på OS X).
Här finns en en kort screencast om gdb som du bör se vid
tillfälle, samt en lathund som går igenom hur gdb fungerar. Om
du stöter på en bugg och vill prova att använda gdb redan på den
här labben kan du be en assistent om hjälp.
4.3 Uppvärmning: Fizz Buzz
Fizz Buzz är en klassisk programmeringsövning som går ut på att implementera leken “Fizz Buzz” där man sitter i en ring och räknar uppåt från 1. Den som börjar börjar säger 1, och nästa person säger 2, etc. – men alla tal som är delbara med 3 ersätts med “Fizz”, alla tal som är delbara med 5 ersätts med “Buzz” och alla tal som är delbara med både 3 och 5 med “Fizz Buzz”.
Skriv ett program som räknar från 1 till ett på kommandoraden angivet tal på detta sätt:
$ gcc -Wall fizzbuzz.c $ ./a.out 16 1, 2, Fizz, 4, Buzz, Fizz, 7, 8, Fizz, Buzz, 11, Fizz, 13, 14, Fizz Buzz, 16 $ _
Strukturera programmet så här:
- En
main()-funktion som läser in ett tal T som ett kommandoradsargument (se föregående labb) - En loop i
main()-funktionen som räknar från 1 till T - En funktion
void print_number(int num)som anropas för varje T och skriver /T_, Fizz, Buzz eller Fizz Buzz - Fundera på hur du skall göra för att inte ha något sista avslutande
,-tecken
Tips: i C är modulo-operatorn %, dvs. 10 % 5 = 0 och 10 % 3 = 1.
4.4 I/O
I/O – input/output – är en viktig del av många program, och ibland knepigt beroende på hur långt ned i mjukvarustacken man befinner sig. Ju närmare hårdvaran – desto lägre abstraktionsnivå erbjuds, vilket tvingar oss att tänka på fler detaljer.
Vi skall börja med att implementera en generell rutin för att ställa en fråga och läsa in ett svar i form av ett heltal. Vi kommer att göra det i ett antal delsteg som förbättrar programmet på ett antal sätt, och därigenom illustrera en vanlig programmeringsprocess.
Börja med att skapa filen ioopm/lab2/utils.c – vi skall jobba
med den idag. Den skall inkludera stdio.h, som är C:s
standardbibliotek för I/O-funktioner.
4.4.1 Del 1: ask_question_int()
Tillägg i utils.c.
Funktionen scanf() fungerar analogt med printf() men för
inläsning av data, inte utskrift. Följande två rader visar
hur man kan deklarera en heltalsvariabel result och sedan
läsa in ett heltal från terminalen och spara i variabeln:
int result; scanf("%d", &result);
int%20result%3B%0Ascanf%28%22%25d%22%2C%20%26result%29%3B%0A
Observera &-tecknet före result ovan! Det är den så-kallade
adresstagningsoperatorn som returnerar adressen till en
plats i minnet. Alltså, result är en int (enligt vår
deklaration) men &result har typen int * vilket betyder
adressen till en plats i minnet där det finns en int. Detta är
en så-kallad pekare, och vi skall få anledning att återkomma till
pekare tusentals gånger under kursen. Nu räcker det med att veta
att alla anrop till scanf() måste innehålla adresser till
platser i minnet där resultaten av en inläsning skall läggas. Om
vi t.ex. vill läsa in tre tal:
int first; int second; int third; scanf("%d %d %d", &first, &second, &third);
int%20first%3B%0Aint%20second%3B%0Aint%20third%3B%0Ascanf%28%22%25d%20%25d%20%25d%22%2C%20%26first%2C%20%26second%2C%20%26third%29%3B%0A
Funktionen scanf() har väldigt många olika möjligheter och
“features” som vi inte hinner gå in på här – vi uppmuntrar att du
bläddrar genom manualsidan för scanf() och dess syskonfunktioner
för att bilda dig en uppfattning (man scanf, men inte under
labben).
Nu kan vi skriva en funktion ask_question_int() som tar en
sträng (char *) som indata, skriver ut strängen på terminalen,
läser in ett heltal, och returnerar det. Signaturen för
ask_question_int() skall följaktigen vara:
int ask_question_int(char *question)
int%20ask_question_int%28char%20%2Aquestion%29%0A
(Strikt sett är question inte en del av signaturen – det är bara
ett internt namn på det inskickade argumentet och kan fritt döpas
om utan att det påverkar användare av funktionen.)
Vi är nu redo att skriva vår första implementation av funktionen.
Innan det finns en main()-funktion i denna fil måste du
kompilera med flaggan -c för att tala om för kompilatorn att du
inte försöker skapa ett körbart program. Vi återkommer till denna
flagga senare under kursen. (Du kan också lägga till en
main()-funktion som vi gör nedan.)
int ask_question_int(char *question) { printf("%s\n", question); int result = -1; // godtyckligt valt nummer scanf("%d", &result); return result; }
int%20ask_question_int%28char%20%2Aquestion%29%0A%7B%0A%20%20printf%28%22%25s%5Cn%22%2C%20question%29%3B%0A%20%20int%20result%20%3D%20-1%3B%20%2F%2F%20godtyckligt%20valt%20nummer%0A%20%20scanf%28%22%25d%22%2C%20%26result%29%3B%0A%20%20return%20result%3B%0A%7D%0A
För enkelhets skull lägger vi till en main()-funktion som kan
testa vårt program. Senare kommer vi att ta bort den. Syftet med
utils.c är nämligen att vi skall skapa några grundläggande
funktioner i ett bibliotek som kommer att återanvändas i
inlämningsuppgifterna senare.
int main(void) { int tal; tal = ask_question_int("Första talet:"); printf("Du skrev '%d'\n", tal); tal = ask_question_int("Andra talet:"); printf("Du skrev '%d'\n", tal); return 0; }
int%20main%28void%29%0A%7B%0A%20%20int%20tal%3B%0A%0A%20%20tal%20%3D%20ask_question_int%28%22F%C3%B6rsta%20talet%3A%22%29%3B%0A%20%20printf%28%22Du%20skrev%20%27%25d%27%5Cn%22%2C%20tal%29%3B%0A%0A%20%20tal%20%3D%20ask_question_int%28%22Andra%20talet%3A%22%29%3B%0A%20%20printf%28%22Du%20skrev%20%27%25d%27%5Cn%22%2C%20tal%29%3B%0A%0A%20%20return%200%3B%0A%7D%0A
Kompilera och kör programmet! Testa med följande input och notera vad resultatet blir:
1och11aoch11och1aaoch42
Inläsning från tangentbordet i C fungerar genom en
tangentbordsbuffert som du kan tänka på som en sträng i datorns
minne. scanf()-funktionen ovan förväntar sig ett heltal
(styrkoden %d – tänk digits) vilket betyder att inläsningen
av 1a slutar vid 1, så att a\n lämnas kvar i minnet
(observera radbrytningstecknet \n). Vid nästa inläsning finns
a\n kvar i bufferten och eftersom scanf() läser rad för rad
kommer scanf inte att kunna läsa in något tal.
Vår ask_question_int() behöver bli lite smartare: vi måste
kontrollera vad scanf() lyckas med.
Returvärdet från scanf() är så många inläsningar som scanf()
lyckades med. I vårt fall försöker vi bara göra en (en styrkod
%d) så om scanf() returnerar 1 vet vi att inläsningen är
lyckad.
Intuitivt kanske man kan tycka att följande funktion borde lösa problemet:
int ask_question_int(char *question) { int result = -1; do { printf("%s\n", question); } while (scanf("%d", &result) != 1); return result; }
int%20ask_question_int%28char%20%2Aquestion%29%0A%7B%0A%0A%20%20int%20result%20%3D%20-1%3B%0A%0A%20%20do%0A%20%20%7B%0A%20%20%20%20printf%28%22%25s%5Cn%22%2C%20question%29%3B%0A%20%20%7D%0A%20%20while%20%28scanf%28%22%25d%22%2C%20%26result%29%20%21%3D%201%29%3B%0A%0A%20%20return%20result%3B%0A%7D%0A
Det gör den inte, och problemet ligger i att en misslyckad
scanf() inte tömmer tangentbordsbufferten (vi har ju bara bett
om att läsa till och med nästa tal – inte det som kommer efter).
Nästa varv i loopen i detta program är alltså dömt att misslyckas.
Det betyder att om vi skriver in 1a med detta program kommer
programmet att köra för evigt!
Det finns ingen bästa lösning på detta problem, men en möjlig
lösning som är både vettig och enkel är att kasta bort resten av
den inlästa raden. Dvs. om du skriver in 1a..., läses 1 in,
och a... kastas bort oavsett vad som är i ....
Vi kan tömma tangentbordets buffer så här:
int c; do { c = getchar(); } while (c != '\n');
int%20c%3B%0Ado%0A%7B%0A%20%20c%20%3D%20getchar%28%29%3B%0A%7D%0Awhile%20%28c%20%21%3D%20%27%5Cn%27%29%3B%0A
Denna loop tar tecken från terminalen, ett efter ett, tills den
läser ett \n. På så vis töms tangentbordets buffert. Vi kan nu
skriva en fungerande ask_question_int():
int ask_question_int(char *question) { int result = 0; int conversions = 0; do { printf("%s\n", question); conversions = scanf("%d", &result); int c; do { c = getchar(); } while (c != '\n'); putchar('\n'); } while (conversions < 1); return result; }
int%20ask_question_int%28char%20%2Aquestion%29%0A%7B%0A%0A%20%20int%20result%20%3D%200%3B%0A%20%20int%20conversions%20%3D%200%3B%0A%20%20do%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22%25s%5Cn%22%2C%20question%29%3B%0A%20%20%20%20%20%20conversions%20%3D%20scanf%28%22%25d%22%2C%20%26result%29%3B%0A%20%20%20%20%20%20int%20c%3B%0A%20%20%20%20%20%20do%0A%09%7B%0A%09%20%20c%20%3D%20getchar%28%29%3B%0A%09%7D%0A%20%20%20%20%20%20while%20%28c%20%21%3D%20%27%5Cn%27%29%3B%0A%20%20%20%20%20%20putchar%28%27%5Cn%27%29%3B%0A%20%20%20%20%7D%0A%20%20while%20%28conversions%20%3C%201%29%3B%0A%20%20return%20result%3B%0A%7D%0A
Ändra gärna while (c != '\n'); till while (c != '\n' && c != EOF);.
Den andra villkoret betyder att c inte skall vara specialtecknet
som avser att en fil är slut – End Of File. Det hanterar inmatning
som avslutas utan att det kommer en ny rad sist.
Funktionen blir enklare att läsa och förstå om du flyttar ut den
inre loopen (den som tömmer tangentbordets buffert) till en egen
funktion med ett bra namn, till exempel clear_input_buffer().
4.4.2 Del 2: Inläsning av en sträng
Tillägg i utils.c.
Vi har nu sett ett exempel på inläsning av ett heltal. Låt oss nu
läsa in en sträng istället. Vi skall skriva
ask_question_string() med motsvarande beteende – men denna gång
skall vi inte tillåta den tomma strängen. Något som gör denna
funktion mycket svårare att skriva är att strängar inte har en fix
storlek. Om vi skall använda scanf() för att läsa in en sträng
måste vi skicka med adressen till en plats i minnet där resultatet
skall sparas, analogt med inläsning av heltal. Ett klassiskt
säkerhetshål i C är s.k. “buffer exploits” som i stort går ut på
att mata in för långa strängar i ett program så att de inte
ryms i buffrarna och spiller över in i programmets övriga minne.
Ta därför alltid för vana när du läser in data i ett C-program att
enbart använda funktioner som låter dig ange hur många tecken som
ryms på den plats där det inlästa datat skall sparas!
Här är en regelvidrig (och dessutom felaktig – testa
själv) inläsningsfunktion som absolut aldrig får användas. Här
använder vi en array med 255 tecken som inläsningsbuffert (vi har
alltså plats för 254 tecken + null-tecknet), och använder oss av
två hjälpfunktioner för att kontrollera strängens längd
(strlen()) och skapa en kopia av den inlästa strängen som vi
returnerar (strdup()):
#include <string.h> char *ask_question_string(char *question) { char result[255]; // <-- bufferstorlek 255 do { printf("%s\n", question); scanf("%s", result); // <-- scanf vet ej bufferstorlek! (inläsning av >254 tecken möjligt!) } while (strlen(result) == 0); return strdup(result); }
%23include%20%3Cstring.h%3E%0A%0Achar%20%2Aask_question_string%28char%20%2Aquestion%29%0A%7B%0A%0A%20%20char%20result%5B255%5D%3B%20%2F%2F%20%3C--%20bufferstorlek%20255%0A%20%20do%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22%25s%5Cn%22%2C%20question%29%3B%0A%20%20%20%20%20%20scanf%28%22%25s%22%2C%20result%29%3B%20%2F%2F%20%3C--%20scanf%20vet%20ej%20bufferstorlek%21%20%28inl%C3%A4sning%20av%20%3E254%20tecken%20m%C3%B6jligt%21%29%0A%20%20%20%20%7D%0A%20%20while%20%28strlen%28result%29%20%3D%3D%200%29%3B%0A%20%20return%20strdup%28result%29%3B%0A%7D%0A
Nu skall du skriva en funktion som tar emot en buffert (i form av
en sträng, char *), en storleksangivelse för bufferten i form av
ett heltal och som läser in en sträng i bufferten. Det avslutande
'\n'-tecknet skall inte vara med i strängen som returneras.
Funktionens signatur skall vara:
int read_string(char *buf, int buf_siz)
int%20read_string%28char%20%2Abuf%2C%20int%20buf_siz%29%0A
Där returvärdet är antalet inlästa tecken, alltså hur många av de
buf_siz tecknen i buf som faktiskt används, förutom
null-tecknet. Valida värden är alltså [0..buf_siz-1].
Att läsa in en sträng är väldigt likt att tömma
tangentbordsbufferten som vi gjorde ovan, med den lilla skillnaden
att vi sparar det vi läste in i buf. Vidare måste vi:
- Lägga till en räknare för hur många tecken vi läst in
- Se till att räknarens värde inte överstiger
buf_siz-1 - Se till att strängen vi läser in blir korrekt nullterminerad
Som du kanske minns från föregående labb är en sträng en array av
tecken som slutar med tecknet '\0'. Eftersom detta tecken också
tar upp en plats i strängen får vi inte läsa in buf_siz tecken
utan högst buf_siz-1 tecken. Genom att skriva '\0' sist i
strängen har vi markerat dess slut. Alltså: om vi har läst in 5
tecken i en buffert buf skall vi sätta buf[5] = '\0'; dvs.
skriva '\0' på den sjätte platsen i buf. Om buf endast
hade längden 5 hade vi fått sluta läsa in efter 4 tecken så
att vi kunde göra buf[4] = '\0'.
Om vi lyckas läsa hela vägen till det sista '\n'-tecknet behöver
vi inte tömma tangentbordets buffer. Om vår inläsningsbuffer tar
slut först, dock, så skall vi tömma tangentbordets buffer på samma
sätt om vi gjorde i ask_question_int().
Här är en enkel main()-funktion som du kan använda för att
testa ditt program:
int main(void) { int buf_siz = 255; int read = 0; char buf[buf_siz]; puts("Läs in en sträng:"); read = read_string(buf, buf_siz); printf("'%s' (%d tecken)\n", buf, read); puts("Läs in en sträng till:"); read = read_string(buf, buf_siz); printf("'%s' (%d tecken)\n", buf, read); return 0; }
int%20main%28void%29%0A%7B%0A%20%20%20%20int%20buf_siz%20%3D%20255%3B%0A%20%20%20%20int%20read%20%3D%200%3B%0A%20%20%20%20char%20buf%5Bbuf_siz%5D%3B%0A%0A%20%20%20%20puts%28%22L%C3%A4s%20in%20en%20str%C3%A4ng%3A%22%29%3B%0A%20%20%20%20read%20%3D%20read_string%28buf%2C%20buf_siz%29%3B%0A%20%20%20%20printf%28%22%27%25s%27%20%28%25d%20tecken%29%5Cn%22%2C%20buf%2C%20read%29%3B%0A%0A%20%20%20%20puts%28%22L%C3%A4s%20in%20en%20str%C3%A4ng%20till%3A%22%29%3B%0A%20%20%20%20read%20%3D%20read_string%28buf%2C%20buf_siz%29%3B%0A%20%20%20%20printf%28%22%27%25s%27%20%28%25d%20tecken%29%5Cn%22%2C%20buf%2C%20read%29%3B%0A%0A%20%20%20%20return%200%3B%0A%7D%0A
Notera att read_string() inte returnerar den inlästa strängen –
genom att main()-funktionen delat adressen till buf-arrayen
med read_string() kan den senare skicka data tillbaka till den
förra genom att skriva i arrayen.
Pröva med långa strängar, korta strängar, med och utan mellanslag,
en lång följd av en kort, en kort följd av en lång, etc. Notera
att första varje anrop till read_string() använder samma
buffert, dvs. den andra inläsningen skriver över innehållet som
var inläst av den första inläsningen. Detta är i sig inget
problem, men kan kanske hjälpa dig att förstå varför du kan få
rester av gammal input i din sträng om du gör fel.
4.4.3 Del 3: ask_question_string()
Tillägg i utils.c.
Nu när vi har en read_string()-funktion är det enkelt att
implementera en ask_question_string(). Gör det, och använd
returvärdet från read_string() för att fånga tomma strängen
(vars längd är 0) och i så fall upprepa frågan på samma sätt som
ask_question_int().
Funktionen ask_question_string() går i stort sett att extrahera
från det första försöket att implementera ask_question_string()
men skall ha signaturen:
char *ask_question_string(char *question, char *buf, int buf_siz)
char%20%2Aask_question_string%28char%20%2Aquestion%2C%20char%20%2Abuf%2C%20int%20buf_siz%29%0A
Senare under kursen skall vi se hur vi kan ändra så att signaturen för funktionen blir
char *ask_question_string(char *question)
char%20%2Aask_question_string%28char%20%2Aquestion%29%0A
genom att skapa ett dynamiskt allokerat minnesutrymme i vilket vi kan spara den inlästa strängen.
4.5 Gör om utils.c till ett “riktigt bibliotek”
Nu skall vi skapa vår första header-fil! Skapa utils.h i
samma katalog som utils.c och flytta dit samtliga
funktionsprototyper från utils.c. I utils.h borde det nu alltså
åtminstone stå:
#include <stdbool.h> int read_string(char *buf, int buf_siz); bool is_number(char *str); int ask_question_int(char *question); char *ask_question_string(char *question, char *buf, int buf_siz);
%23include%20%3Cstdbool.h%3E%0Aint%20read_string%28char%20%2Abuf%2C%20int%20buf_siz%29%3B%0Abool%20is_number%28char%20%2Astr%29%3B%0Aint%20ask_question_int%28char%20%2Aquestion%29%3B%0Achar%20%2Aask_question_string%28char%20%2Aquestion%2C%20char%20%2Abuf%2C%20int%20buf_siz%29%3B%0A
Som första rader i utils.h skriv
#ifndef __UTILS_H__ #define __UTILS_H__
%23ifndef%20__UTILS_H__%0A%23define%20__UTILS_H__%0A
och som sista rader skriv
#endif
%23endif%0A
(alternativt skriv bara #pragma once högst upp i utils.c!)
Vi återkommer till dessa magiska instruktioner senare. Om du är nyfiken – kolla i kurslitteraturen, sök på nätet, eller fråga en assistent!
Lägg till #include "utils.h" i utils.c – notera "..." istället för <...>.
Passa också på att ta bort main()-funktione ur utils.c. Nu har vi
ett “riktigt bibliotek” som kan inkluderas av program som behöver komma
åt hjälpfunktionerna.
4.6 Applikation: Gissa talet redovisas
Nu skall vi skapa programmet guess.c som använder sig av våra
två ask_-funktioner. Interaktion med programmet skall se ut så här:
$ gcc -Wall guess.c $ ./a.out Skriv in ditt namn: Tobias Du Tobias, jag tänker på ett tal ... kan du gissa vilket? 0 För litet! 1000 För stort! 500! För stort! ... (osv) För litet! 42 Bingo! Det tog Tobias 12 gissningar att komma fram till 42 $ _
Om man tar mer än 15 gissningar på sig skall programmet skriva ut:
... Nu har du slut på gissningar! Jag tänkte på 42! $ _
Programmet skall alltså:
- Slumpa fram ett tal T (med hjälp av funktionen
random()istdlib.h) - Fråga efter användarens namn N
- Skriva ut “Du N, jag tänker på ett tal kan du gissa vilket?”
- I en loop, läsa in tal från användaren och skriva ut “För litet!” eller “För stort!” eller “Bingo!”
- Vid bingo, skriv ut “Det tog N G gissningar att komma fram till T”
- Om G når 15, skriva ut “Nu har du slut på gissningar! Jag tänkte på T!”
På vissa maskiner fungerar rand() bättre än random(). Den senare är en
del av POSIX, den förra är en del av C:s standardbibliotek. Jag har låtit mig
förstå att rand()-funktionen har problem, men på kursen fungerar den fint!
Funktionen random() i stdlib.h returnerar ett slumptal som kan vara mycket
stort. För att skapa ett slumptal mellan 0 och N kan du använda
modulo:
random() % 1024 // slumptal mellan 0 och 1023
random%28%29%20%25%201024%20%20%2F%2F%20slumptal%20mellan%200%20och%201023%0A
Programmet använder naturligtvis funktionerna från utils.c, utefter
den beskrivning som finns i utils.h. Importera dem
i guess.c så här:
#include "utils.h"
%23include%20%22utils.h%22%0A
Om när du kompilerar – ange båda källkodsfilerna:
$ gcc -Wall utils.c guess.c
Om du har glömt att ta bort main()-funktionen från utils.c
kommer detta inte att fungera eftersom det då finns två
main()-funktioner, vilket är tvetydigt och därför inte är
tillåtet!
Angående slumptal
Om man vill använda slumptal i produktion är det bra att initiera
slumptalsgeneratorn. Detta görs genom att anropa funktionen
srandom() med (alt. srand() om du använde rand() istf.
random()) ett s.k. seed, dvs. input till en funktion som ser
till att datorn producerar hyggligt slumpvisa tal. Denna funktion
anropas en gång i programmet, t.ex. i main() med något
“slumpvist” värde, t.ex. antalet sekunder sedan midnatt första
januari 1970. Alltså så här:
#include <stdlib.h> #include <time.h> ... srandom(time(NULL)); /// initialize randomness -- call once per program run ... int r = rand(); /// generate a random value
%23include%20%3Cstdlib.h%3E%0A%23include%20%3Ctime.h%3E%0A%0A...%0A%0Asrandom%28time%28NULL%29%29%3B%20%2F%2F%2F%20initialize%20randomness%20--%20call%20once%20per%20program%20run%0A...%0Aint%20r%20%3D%20rand%28%29%3B%20%2F%2F%2F%20generate%20a%20random%20value%0A
Observera att en upplösning på 1 sekund inte är mycket att hänga i julgranen! Om du skriver ett program som skriver ut ett slumptal och kör det två gånger samma sekund får du samma “slumptal”.
Jag rekommenderar att du inte använder srandom() (srand())
på kursen eftersom det gör det svårare att felsöka ditt program om
du t.ex. inte kan lita på gissa-talet-programmet stabilt drar 4711
ur hatten varje gång…
Läs mer om generering av slumptal på t.ex. Wikipedia.
4.7 Extrauppgifter
För dig som är tidigt färdig eller känner att du vill arbeta mer med materialet.
4.7.1 Implementera om ask_question_int()
Implementera om ask_question_int() i termer av read_string()
och den is_number() som du implementerade på föregående labb.
Du skall alltså använda read_string() för att läsa in en sträng,
och sedan is_number() för att verifiera att den inlästa strängen
faktiskt är ett tal.
Om du lägger till is_number() i utils.c har du utökat ditt
utility-bibliotek!
4.7.2 Implementera ask_question_float()
Implementera funktione ask_question_float() i termer av
read_string() och en is_float() som du själv måste skriva. Du
kan utgå från is_number() men också tillåta förelkomsten av
en punkt . någonstans i strängen. Funktionen atof() i
ctype.h vet hur man omvandlar en sträng till ett flyttal.
4.7.3 Enkel aritmetikdrillare
Skriv ett enkelt program som ett enkelt artitmetiskt uttryck på formatet
\(tal_1 \odot tal_2 = ?\)
Där \(tal_1\) och \(tal_2\) är framslumpade tal i intervallet \([1,1024]\) och \(\odot\) är en framslumpad operator i mängden \(\{+, -, *, /\}\).
Användaren skall mata in tal och programmet kontrollerar att det inmatade talet är korrekt.
En rolig utökning av denna uppgift är att tillåta att användaren
svarar fyrahundratjugosju istället för 427. Du kan
implementera detta på två sätt:
- implementera en funktion som konverterar heltal till dess
textuella motsvarighet. Du kan sedan använda funktionen
strcmp()frånstring.hför att göra jämförelsen. - implementera en funktion som konverterar från ett heltals
textuella motsvarighet till heltalet, dvs. från
tvåtill2. Du kan nu använda==-operatorn för att göra jämförelsen.
Notera att strcmp()-funktionen tar emot två strängar och
returnerar 0 om de är lika. Dvs.:
char *str1 = "foo"; char *str2 = "bar"; if (strcmp(str1, str2) == 0) { puts("Strängarna är lika"); } else { puts("Strängarna är inte lika"); }
char%20%2Astr1%20%3D%20%22foo%22%3B%0Achar%20%2Astr2%20%3D%20%22bar%22%3B%0Aif%20%28strcmp%28str1%2C%20str2%29%20%3D%3D%200%29%0A%7B%0A%20%20puts%28%22Str%C3%A4ngarna%20%C3%A4r%20lika%22%29%3B%0A%7D%0Aelse%0A%7B%0A%20%20puts%28%22Str%C3%A4ngarna%20%C3%A4r%20inte%20lika%22%29%3B%0A%7D%0A
5 Labb 3: Rekursion, Generalisering & Funktionspekare
Om du känner att du är stressad och har ont om tid – kan det ibland vara en god idé att pröva att gå direkt på funktionspekare, dvs. hoppa över början. Så går du tillbaka efter att du har redovisat.
5.1 Att arbeta med flera filer i Emacs
Att arbeta med fler än en fil i Emacs är lämpligt att göra genom att öppna flera windows i samma Emacs-fönster (eller frame med Emacs-termer). Nedan använder jag ordet frame för det som du normalt kallar för fönster, och ordet window för en del av en frame som visar en buffer med text.
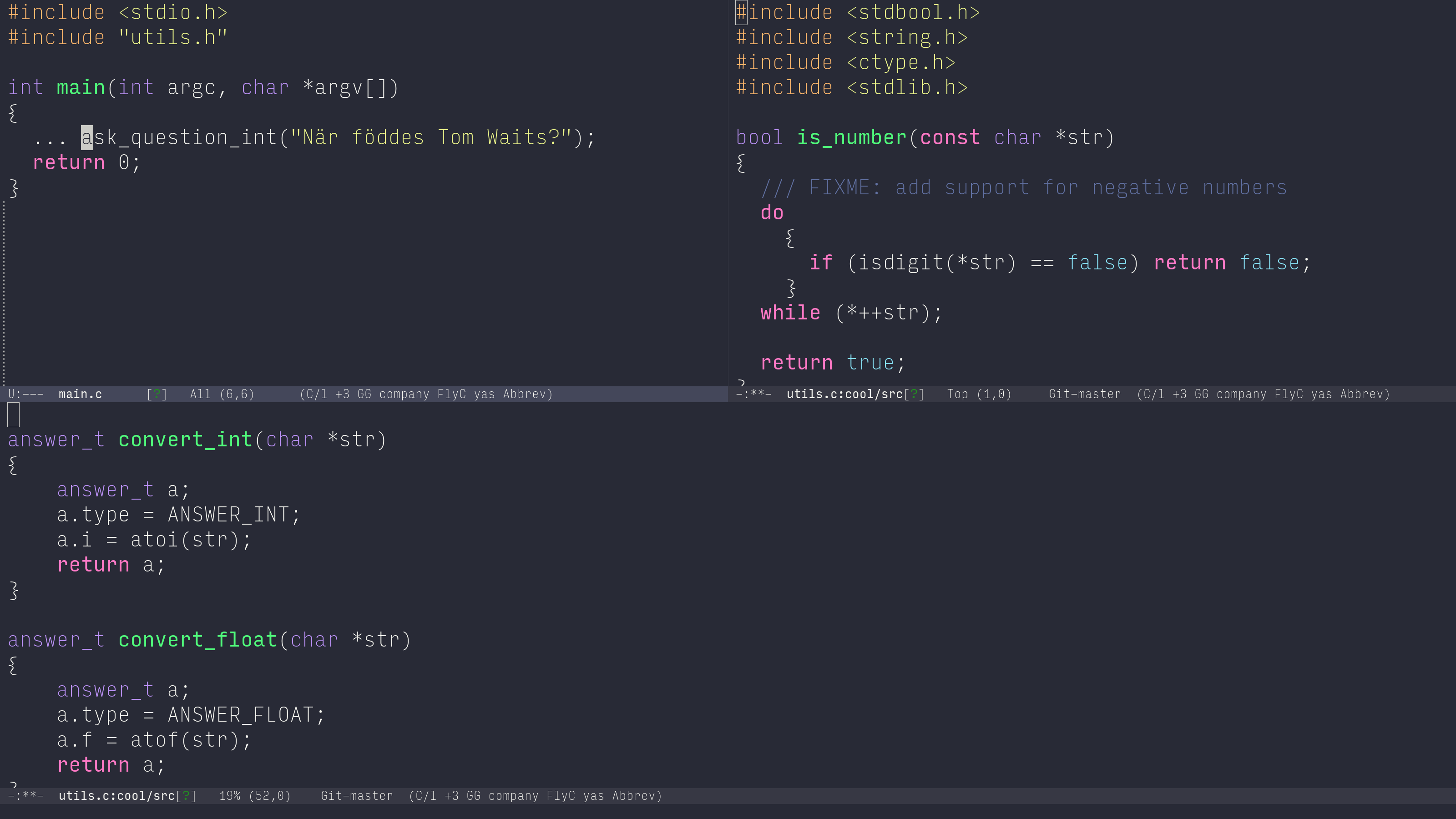
Figure 1: Ett Emacs-frame med tre windows
För att återskapa ovanstående split i tre windows. Gör så här efter att du startat Emacs:
- C-x − för att dela (det aktuella) window:et horizontellt
- C-x ∣ för att dela (det aktuella) window:et vertikalt
Navigera mellan de olika Emacs-window:arna så här: C-x ←, C-x →, C-x ↑ och C-x ↓.
Positionera dig längst ned (med kommandona ovan) och öppa utils.c med C-x C-f utils.c ↵.
Positionera dig i övre vänstre window:et ned (med kommandona ovan) och öppa tmp.c med C-x C-f tmp.c ↵.
Positionera dig i övre högra window:et och växla så att den visar samma buffert
som någon av de andra window:arna med C-x b. Skriv sedan namnet på buffern (du kan använda tab för autocomplete)
och tryck ↵.
Om du gillar att ha många filer öppna i Emacs samtidigt kan du pröva att trycka till exempel C-x C-b för att lista alla öppna buffrar. Nu kan du navigera till den buffer du vill öppna med piltangenterna och trycka enter.
Om du vill stänga window:et som du står i: C-x 0. Om du vill stänga alla andra windows utom det du står i: C-x 1.
Två anledningar till att det inte är bra att köra emacs fil.c
& flera gånger i terminalen är att det startar flera instanser av
Emacs och:
- det åtgår en massa mer minne – \(N\) gånger för \(N\) instanser
- de olika instanserna är inte medvetna om varandra – och en fil som är öppen i flera instanser kan hamna i osynk
Ovanstående gäller inte bara Emacs utan generellt. På macOS med
ett grafiskt Emacs kommer emacs fil.c & att öppna ett redan
körande Emacs om ett sådant finns.
Om du föredrar att ha flera separata fönster öppet på skärmen kan
du använda kommandot M-x make-frame ↵ för att öppna
ett nytt fönster och sedan C-x C-f som vanligt för att öppna
en fil i det fönstret.
5.2 Uppvärmning: strängfunktioner
Skapa ett program str.c.
Som du säkert minns är C:s strängtyp char *. Det betyder en
adress till en plats i minnet där det finns lagrat ett eller
fler tecken. Det är i de flesta avseenden ekvivalent med typen
char [] som avser en array av ett eller fler tecken. Strängar
innehåller ingen information om hur långa de är – istället
används ett speciellt tecken som ett stopptecken: det s.k.
null-tecknet som skrivs '\0'.
Om vi skriver char *str = "Guy Maddin, Winnipeg"; har vi skapat
en sträng vars innehåll är 21 tecken. Om vi skriver detta som en
array: ['G', 'u', 'y', ' ', 'M', 'a', 'd', 'd', 'i', 'n', ',', ' ', 'W', 'i', 'n', 'n', 'i', 'p', 'e', 'g', '\0']. Det enda sättet att ta reda på hur lång
en sträng är är att “loopa igenom den” och leta efter null-tecknet.
5.2.1 Uppvärmningsuppgift 1: implementera en egen strlen()-motsvarighet
Implementera en funktion string_length() som tar som argument en
sträng och returnerar ett heltal som avser hur många tecken som
var i strängen. Du kan t.ex. använda en loop och en
heltalsvariabel som räknare för att lösa uppgiften. För varje varv
i loopen, gå ett steg längre “till höger” i arrayen, och leta
efter ett '\0'-tecken. Antalet gångna steg är strängens längd.
Testa ditt program genom att jämföra dess output med strlen()
som finns i string.h. Du kan t.ex. skriva så här:
int main(int argc, char *argv[]) { if (argc < 2) { printf("Usage: %s words or string", argv[0]); } else { for (int i = 1; i < argc; ++i) { int expected = strlen(argv[i]); int actual = string_length(argv[i]); printf("strlen(\"%s\")=%d\t\tstring_length(\"%s\")=%d\n", argv[i], expected, argv[i], actual); } } return 0; }
int%20main%28int%20argc%2C%20char%20%2Aargv%5B%5D%29%0A%7B%0A%20%20if%20%28argc%20%3C%202%29%0A%20%20%7B%0A%20%20%20%20printf%28%22Usage%3A%20%25s%20words%20or%20string%22%2C%20argv%5B0%5D%29%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20for%20%28int%20i%20%3D%201%3B%20i%20%3C%20argc%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20int%20expected%20%3D%20strlen%28argv%5Bi%5D%29%3B%0A%20%20%20%20%20%20int%20actual%20%20%20%3D%20string_length%28argv%5Bi%5D%29%3B%0A%20%20%20%20%20%20printf%28%22strlen%28%5C%22%25s%5C%22%29%3D%25d%5Ct%5Ctstring_length%28%5C%22%25s%5C%22%29%3D%25d%5Cn%22%2C%0A%09%20%20%20%20%20argv%5Bi%5D%2C%20expected%2C%20argv%5Bi%5D%2C%20actual%29%3B%0A%20%20%20%20%7D%0A%20%20%7D%0A%20%20return%200%3B%0A%7D%0A
Observera att för att skriva ut " inuti en sträng så måste vi
“escape:a dem”, dvs. skriva dem som \". Tecknet \t står för
tab.
Exempelkörning:
$ gcc -Wall str.c
$ ./a.out hej hopp
strlen("hej")=3 string_length("hej")=3
strlen("hopp")=4 string_length("hopp")=4
$ _
Ovan kan vi se att strlen() och string_length() ger samma svar
för de ord vi skickade in vilket ger förhoppning om att
string_length() är korrekt implementerad.
5.2.2 Uppvärmningsuppgift 2: implementera egna enkla print-satser
Analogt med hur vi har använt funktionen getchar() för att läsa
in tecken för tecken kan vi använda funktionen putchar() för att
skriva tecken för tecken. Om jag t.ex. har en sträng s kan jag
skriva putchar(s[3]) för att skriva ut dess fjärde tecken.
- Implementera funktionen
print()som tar en sträng och skriver ut den på terminalen (med hjälp avputchar()) fast utan avslutande radbrytning. - Implementera
println()– en egen motsvarighet tillputs(), som tar en sträng och skriver ut den på terminalen (med hjälp avprint()) med en avslutande radbrytning. Jämför medputs()i ditt program för att kontrollera att du gör rätt. - Lägg till
print()ochprintln()iutils-biblioteket!
5.3 Rekursion i C
Du är bekant med rekursionsbegreppet sedan förut. Rekursion i C
fungerar i stort sett likadant. I labb 1 var en extrauppgift att implementera ett
program som skrev ut tal ur Fibonacci-serien på ett imperativt
sätt. Nedan följer ett liknande program, som bara skriver ut det
sista talet i serien och inte varenda tal på vägen dit. Målet med
denna uppgift är att skriva om fib()-funktionen så att den blir
rekursiv. Efter koden nedan kommer ett exempel som visar hur man
kan skriva en annan imperativ funktion med rekursion.
#include <stdio.h> #include <stdlib.h> /// Den intressanta delen av programmet int fib(int num) { int ppf = 0; // the two given fib values int pf = 1; for (int i = 1; i < num; ++i) { int tmp = pf; pf = ppf + pf; ppf = tmp; } return pf; } /// Den ointressanta main()-funktionen int main(int argc, char *argv[]) { if (argc != 2) { printf("Usage: %s number\n", argv[0]); } else { int n = atoi(argv[1]); if (n < 2) { printf("fib(%d) = %d\n", n, n); } else { printf("fib(%s) = %d\n", argv[1], fib(n)); } } return 0; }
%23include%20%3Cstdio.h%3E%0A%23include%20%3Cstdlib.h%3E%0A%0A%2F%2F%2F%20Den%20intressanta%20delen%20av%20programmet%0Aint%20fib%28int%20num%29%0A%7B%0A%20%20int%20ppf%20%3D%200%3B%20%2F%2F%20the%20two%20given%20fib%20values%0A%20%20int%20pf%20%20%3D%201%3B%0A%0A%20%20for%20%28int%20i%20%3D%201%3B%20i%20%3C%20num%3B%20%2B%2Bi%29%0A%20%20%7B%0A%20%20%20%20int%20tmp%20%3D%20pf%3B%0A%20%20%20%20pf%20%3D%20ppf%20%2B%20pf%3B%0A%20%20%20%20ppf%20%3D%20tmp%3B%0A%20%20%7D%0A%0A%20%20return%20pf%3B%0A%7D%0A%0A%2F%2F%2F%20Den%20ointressanta%20main%28%29-funktionen%0Aint%20main%28int%20argc%2C%20char%20%2Aargv%5B%5D%29%0A%7B%0A%20%20if%20%28argc%20%21%3D%202%29%0A%20%20%7B%0A%20%20%20%20printf%28%22Usage%3A%20%25s%20number%5Cn%22%2C%20argv%5B0%5D%29%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20int%20n%20%3D%20atoi%28argv%5B1%5D%29%3B%0A%20%20%20%20if%20%28n%20%3C%202%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22fib%28%25d%29%20%3D%20%25d%5Cn%22%2C%20n%2C%20n%29%3B%0A%20%20%20%20%7D%0A%20%20%20%20else%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22fib%28%25s%29%20%3D%20%25d%5Cn%22%2C%20argv%5B1%5D%2C%20fib%28n%29%29%3B%0A%20%20%20%20%7D%0A%20%20%7D%0A%20%20return%200%3B%0A%7D%0A
5.3.1 Exempel på iteration \(\Longrightarrow\) rekursion: sum
Nedanstående funktion tar in en array av heltal samt längden på arrayen och adderar talen i arrayen och returnerar summan.
long sum(int numbers[], int numbers_siz) { long result = 0; for (int i = 0; i < number_siz; ++i) { result += numbers[i]; } return result; }
long%20sum%28int%20numbers%5B%5D%2C%20int%20numbers_siz%29%0A%7B%0A%20%20long%20result%20%3D%200%3B%0A%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20number_siz%3B%20%2B%2Bi%29%0A%20%20%7B%0A%20%20%20%20result%20%2B%3D%20numbers%5Bi%5D%3B%0A%20%20%7D%0A%0A%20%20return%20result%3B%0A%7D%0A
En rekursiv motsvarighet kan skrivas utifrån insikten att summan
av en serie av N tal är lika med det första talet + summan av
resterande tal. Alltså, om vi vill beräkna sum([1, 2, 3, 4])
så kan vi räkna ut den som 1 + sum([2, 3, 4]), och så vidare,
där basfallet är sum([]) = 0, alltså summan av alla tal i en
tom array är 0.
Så här skulle vi kunna skriva C-kod som fungerar på detta sätt:
long rec_sum(int numbers[], int numbers_siz, int index) { if (index < numbers_siz) { return numbers[index] + rec_sum(numbers, numbers_siz, index + 1); } else { return 0; } }
long%20rec_sum%28int%20numbers%5B%5D%2C%20int%20numbers_siz%2C%20int%20index%29%0A%7B%0A%20%20if%20%28index%20%3C%20numbers_siz%29%0A%20%20%7B%0A%20%20%20%20return%20numbers%5Bindex%5D%20%2B%20rec_sum%28numbers%2C%20numbers_siz%2C%20index%20%2B%201%29%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20return%200%3B%0A%20%20%7D%0A%7D%0A
Om vi använder rec_sum för att summera arrayen [1, 2, 3]
kommer vi att göra följande steg (förenklat):
rec_sum([1, 2, 3]) = return 1 + rec_sum([2, 3])rec_sum([2, 3]) = return 2 + rec_sum([3])rec_sum([3]) = return 3 + rec_sum([])rec_sum([]) = return 0
Vid (4) har vi nått slutet av vår rekursion och vi kan “gå tillbaka”
och räkna ut att svaret på (3) är 3 + 0 och därmed blir svaret på
(2) 2 + 3 + 0 och (1) 1 + 2 + 3 + 0. Som man kunde förvänta sig.
Eftersom vi inte kan “skala av element från arrayen” använder vi
en extra parameter index som stiger tills den når numbers_siz.
Varje rekursionssteg har alltså tillgång till hela arrayen men
börjar titta från index. Vid startanropet skall index vara 0.
Vi kan nu implementera sum() i termer av rec_sum():
long sum(int numbers[], int numbers_siz) { return rec_sum(numbers, numbers_siz, 0); }
long%20sum%28int%20numbers%5B%5D%2C%20int%20numbers_siz%29%0A%7B%0A%20%20return%20rec_sum%28numbers%2C%20numbers_siz%2C%200%29%3B%0A%7D%0A
Nu återgår vi till uppgiften: skriv om fib()-funktionen i
programmet längst upp på sidan så att den är rekursiv.
Ledning: Vi upprepar den rekursiva definitionen av Fibonacci-serien från labb 1:
fib(1) = 1 fib(2) = 1 fib(i) = fib(i-1) + fib(i-2) om i > 2
En något mer C-lik pseudokod skulle vara:
fib(i) = 1 om i = 0
1 om i = 1
fib(i-1) + fib(i-2) annars
Senare under kursen skall vi diskutera problemet med ändligt
utrymme på stacken och djup rekursion. Ett anrop till rec_sum()
med en väldigt stor array kommer sannolikt att krascha programmet
om inte kompilatorn är smart nog att översätta rekursionen till
en loop – mer om detta senare alltså.
Testa att ditt program är korrekt genom att jämföra dess resultat med resultatet från ditt imperativa program.
5.4 Funktionspekare
Pekare är som bekant adresser till platser i datorns minne där
data finns lagrat. Vi har ännu inte stiftat någon djup bekantskap
med dem men vi har sett att strängar i C är pekare (char *), och
att vi skickat in pekare till int:ar i scanf(). Nu skall vi
stifta bekantskap med pekare till funktioner. Detta motsvarar
högre ordningens funktioner som du använt i Haskell, t.ex. när du
skickat in en funktion och en datasamling till map.
C:s syntax för funktionspekares typer är fruktansvärd och det är därför brukligt att man skapa ett typalias – dvs. skapar ett beskrivande namn på en krånglig typ som man sedan kan använda istället för dess krångliga motsvarighet. Syntaxen för ett typalias är så här:
typedef existerande_typ nytt_namn;
typedef%20existerande_typ%20nytt_namn%3B%0A
Exempel på typalias som inte berör funktionspekare:
typedef char *string_t; typedef unsigned int age_t;
typedef%20char%20%2Astring_t%3B%0Atypedef%20unsigned%20int%20age_t%3B%0A
Här har vi skapat två typalias: string_t kan nu användas överallt
som en synonym för char * och vi har angivit att typen age_t är
ett icke-negativt heltal. Suffixet _t är en namnkonvention.
Just typaliaset string_t är ett alias vi skall undvika eftersom
det avviker från alla andra C-program och därför blir förvirrande
för någon som läser din kod, även om string_t förmodligen har
mindre kognitiv belastning än char * för en ny C-programmerare.
Låt oss nu använda typedef-nyckelordet för att definiera ett
typalias för en funktion. Det är invecklat, men inte speciellt
svårt när man väl har lärt sig läsa koden:
typedef int(*int_fold_func)(int, int);
typedef%20int%28%2Aint_fold_func%29%28int%2C%20int%29%3B%0A
Koden ovan definierar typen int_fold_func som en funktion som
tar som argument två int:ar och returnerar en int. I Haskell
skulle typen skrivas Int -> Int -> Int. Asterisken * framför
namnet int_fold_func ovan är det som gör det hela till en
pekare. Denna skall dock inte vara med i namnet.
Om jag har en funktion add(...) och vill skicka en pekare till
den funktionen skriver jag alltså add. Funktionens namn utan
parenteser och argument. Om jag skriver add(2,2) är det ju
ett helt vanligt anrop till funktionen och det som skickas
in är resultatet!
Nu kan vi använda int_fold_func som en datatyp och deklarara
t.ex. en left fold (som du kanske minns från PKD). Om du inte minns hur en left fold fungerar – försök
att räkna ut det från C-koden nedan!
/// En funktion som tar en array av heltal, arrayens längd och /// en pekare till en funktion f av typen Int -> Int -> Int int foldl_int_int(int numbers[], int numbers_siz, int_fold_func f) { int result = 0; // Loopa över arrayen och för varje element e utför result = f(result, e) for (int i = 0; i < numbers_siz; ++i) { result = f(result, numbers[i]); } return result; }
%2F%2F%2F%20En%20funktion%20som%20tar%20en%20array%20av%20heltal%2C%20arrayens%20l%C3%A4ngd%20och%0A%2F%2F%2F%20en%20pekare%20till%20en%20funktion%20f%20av%20typen%20Int%20-%3E%20Int%20-%3E%20Int%0Aint%20foldl_int_int%28int%20numbers%5B%5D%2C%20int%20numbers_siz%2C%20int_fold_func%20f%29%0A%7B%0A%20%20int%20result%20%3D%200%3B%0A%0A%20%20%2F%2F%20Loopa%20%C3%B6ver%20arrayen%20och%20f%C3%B6r%20varje%20element%20e%20utf%C3%B6r%20result%20%3D%20f%28result%2C%20e%29%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20numbers_siz%3B%20%2B%2Bi%29%0A%20%20%7B%0A%20%20%20%20result%20%3D%20f%28result%2C%20numbers%5Bi%5D%29%3B%0A%20%20%7D%0A%0A%20%20return%20result%3B%0A%7D%0A
Låt oss skriva en funktion som adderar två tal:
int add(int a, int b) { return a + b; }
int%20add%28int%20a%2C%20int%20b%29%0A%7B%0A%20%20return%20a%20%2B%20b%3B%0A%7D%0A
Eftersom add() är en funktion av typen Int -> Int -> Int kan
den användas tillsammans med foldl_int_int. För att skicka med
en funktion som en parameter skriver du bara funktionens namn, i
detta fall alltså add.
Uppgift: Skriv om sum()-funktionen ovan med hjälp av
foldl_int_int() och add(). Du behöver inte ändra i vare sig
foldl_int_int() eller add().
Du har väl inte glömt att du kan tycka M-i för att få upp en lista med alla funktioner och struktar i din C-fil så att du kan söka och snabbt hoppa mellan funktionerna i Emacs?
5.5 Generell inläsningsrutin
Skapa en ny fil med ett lämpligt namn, t.ex. experiment.c med
en tom main()-funktion. Skriv all kod för denna uppgift här,
kompilera ofta och fundera på hur du kan skriva kod i
main()-funktionen som testar/kör den kod som du skriver.
Vi kommer att vilja använda kod som du har skrivit tidigare.
Välj själv om du vill inkludera utils.h och kompilera med
gcc experiment.c utils.c eller om du vill kopiera in all
kod som behövs i experiment.c.
Med hjälp av funktionspekare skall vi nu skriva en generell inläsningsrutin som ger ytterligare abstraktion vid inläsning. Den fångar det generella mönstret för inläsning:
- Skriv ut frågan (t.ex. “mata in ett tal”)
- Läser in svaret
- Kontrollerar att svaret är på rätt format (t.ex. att det är ett tal) och går tillbaka till 1. igen vid behov
- Konverterar det till rätt format (t.ex. från
"42"till42) - Returnerar resultatet
För att göra detta skall vår nya ask_question()-funktion ha tre
parametrar:
- Frågan i form av en sträng (
char *) - En pekare till en funktion som kontrollerar att svaret har rätt format
- En pekare till en funktion som konverterar en sträng till något annat format
Typen på kontrollfunktionen skall vara char * -> bool, dvs. den tar emot
en sträng och returnerar sant eller falskt.
Typen på konverteringsfunktionen skall vara char * -> answer_t –
vilket introducerar en ny typ som vi ännu inte har sätt, nämligen
typen answer_t som är en s.k. union:
typedef union { int int_value; float float_value; char *string_value; } answer_t;
typedef%20union%20%7B%20%0A%20%20int%20%20%20int_value%3B%0A%20%20float%20float_value%3B%0A%20%20char%20%2Astring_value%3B%0A%7D%20answer_t%3B%0A
Typen answer_t avser ett värde som antingen är en int eller_
en float /eller en sträng (char *). Om val är en variabel av
typen answer_t så kan jag tilldela den ett heltal via val.int_value =
42 och läsa det på motsvarande sätt ... = val.int_value, eller en
sträng via val.string_value = ... och ... = val.string_value. Namnen int_value, float_valu och string_value
har jag valt i min definition av answer_t och kan bytas ut mot
andra namn om man så önskar.
Uppgift! Använd typedef för att definiera typerna
check_func och convert_func med typerna ovan. Utgå från
exemplet från int_fold_func.
Ett exempel på en kontrollfunktion är den is_number() som du
redan skrivit (labb 1) och som tar in en sträng och returnerar true eller
false beroende på om strängen kan konverteras till ett tal. En
kontrollfunktion som kontrollerar att en sträng inte är tom kan se
ut så här:
/// Hjälpfunktion till ask_question_string bool not_empty(char *str) { if (strlen(str) > 0) { return true; } else { return false; } }
%2F%2F%2F%20Hj%C3%A4lpfunktion%20till%20ask_question_string%0Abool%20not_empty%28char%20%2Astr%29%0A%7B%0A%20%20if%20%28strlen%28str%29%20%3E%200%29%0A%20%20%7B%0A%20%20%20%20return%20true%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20return%20false%3B%0A%20%20%7D%0A%7D%0A
Eller, mer kompakt och bättre:
/// Hjälpfunktion till ask_question_string bool not_empty(char *str) { return strlen(str) > 0; }
%2F%2F%2F%20Hj%C3%A4lpfunktion%20till%20ask_question_string%0Abool%20not_empty%28char%20%2Astr%29%0A%7B%0A%20%20return%20strlen%28str%29%20%3E%200%3B%0A%7D%0A
Ett exempel på en funktion som går att använda som
konverteringsfunktion är funktionen atoi() som vi har använt
förut. Den fungerar eftersom atoi() returnerar ett heltal som så
att säga är en delmängd av answer_t.
Dock: Om man försöker skicka in atoi som argument till en
funktion vars motsvarande parameter är convert_func kommer
kompilatorn att klaga eftersom answer_t och int inte är samma
typ. Det kan man lösa med hjälp av en typomvandling (eng. type
cast):
atoi // har typen char * -> int (convert_func) atoi // har typen char * -> answer_t
Uppgift! Nu är det dags att skriva funktionen ask_question()
med signaturen:
answer_t ask_question(char *question, check_func check, convert_func convert)
answer_t%20ask_question%28char%20%2Aquestion%2C%20check_func%20check%2C%20convert_func%20convert%29%0A
Inuti denna funktion avser variablerna check och convert
funktioner som kan anropas check(str) etc.
- Skapa en buffert av lämplig längd
- I en loop
- skriv ut frågan
- läs in en sträng med din egen
read_string()-funktion - Använd
checkför att kontrollera att det du läst in är korrekt och terminera loopen
- Använd
convertför att konvertera resultatet och returnera det
Med hjälp av din generella ask_question()-funktion är det nu busenkelt
att definiera nya. T.ex. kan vi definiera ask_question_int() så här:
int ask_question_int(char *question) { answer_t answer = ask_question(question, is_number, (convert_func) atoi); return answer.int_value; // svaret som ett heltal }
int%20ask_question_int%28char%20%2Aquestion%29%0A%7B%0A%20%20answer_t%20answer%20%3D%20ask_question%28question%2C%20is_number%2C%20%28convert_func%29%20atoi%29%3B%0A%20%20return%20answer.int_value%3B%20%2F%2F%20svaret%20som%20ett%20heltal%0A%7D%0A
Om du har skrivit en is_float() på en tidigare labb kan du
använda den för att definiera ask_question_float(). Dock – för
att göra detta måste vi skapa en funktion som skapar ett
answer_t från en double:
answer_t make_float(char *str) { answer_t a; // skapa ett oinitierat answer_t-värde a.float_value = atof(str); // gör det till en float, via atof return a; // returnera värdet }
answer_t%20make_float%28char%20%2Astr%29%0A%7B%0A%20%20answer_t%20a%3B%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20skapa%20ett%20oinitierat%20answer_t-v%C3%A4rde%0A%20%20a.float_value%20%3D%20atof%28str%29%3B%20%2F%2F%20g%C3%B6r%20det%20till%20en%20float%2C%20via%20atof%0A%20%20return%20a%3B%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20returnera%20v%C3%A4rdet%0A%7D%0A
Eller, mer kompakt (skapar ett nytt answer_t-värde) – via en syntax
som vi skall behandla i mer detalj på nästa labb:
answer_t make_float(char *str) { return (answer_t) { .float_value = atof(str) }; }
answer_t%20make_float%28char%20%2Astr%29%0A%7B%0A%20%20return%20%28answer_t%29%20%7B%20.float_value%20%3D%20atof%28str%29%20%7D%3B%0A%7D%0A
Här skriver vi ask_question_float() utan den onödiga variabeln
answer bara för att visa att det också är möjligt (notera .float_value
på slutet!).
double ask_question_float(char *question) { return ask_question(question, is_float, make_float).float_value; }
double%20ask_question_float%28char%20%2Aquestion%29%0A%7B%0A%20%20return%20ask_question%28question%2C%20is_float%2C%20make_float%29.float_value%3B%0A%7D%0A
För att göra ask_question_string() måste vi tyvärr gå händelserna
i förväg en aning och använda en funktion, strdup() vars funktion
är svårt att förklara med den begränsade del av C som vi har tittat
på hittills. Den inlästa strängen i din ask_question() är ju redan
en sträng, så man kan tycka att man kunde returnera den rakt av, men
så är inte fallet!
Skriv så här längst upp i filen så länge. Senare kommer vi att skriva en egen version av denna kod:
extern char *strdup(const char *);
extern%20char%20%2Astrdup%28const%20char%20%2A%29%3B%0A
Det är nämligen så att din inläsningsbuffert (iallafall om du har
använt en array, som är det enda vi gått igenom hittills) är knuten
till den omslutande funktionen – och efter att funktionen är klar
kan minnet där texten lästes in komma att återanvändas när som helst.
Vi måste därför skapa en kopia av strängen som är fri att skickas
vart som helst. Detta görs med hjälp av funktionen strdup() som
finns i string.h och som duplicerar en sträng. Exemplet nedan
skapar en kopia och skriver ut både kopian och originalet:
char *original = "foo bar baz!" char *kopia = strdup(original); printf("%s\n%s\n", original, kopia);
char%20%2Aoriginal%20%3D%20%22foo%20bar%20baz%21%22%0Achar%20%2Akopia%20%3D%20strdup%28original%29%3B%0Aprintf%28%22%25s%5Cn%25s%5Cn%22%2C%20original%2C%20kopia%29%3B%0A
Nu kan vi skriva klar ask_question_string() så här:
char *ask_question_string(char *question) { return ask_question(question, not_empty, (convert_func) strdup).string_value; }
char%20%2Aask_question_string%28char%20%2Aquestion%29%0A%7B%0A%20%20return%20ask_question%28question%2C%20not_empty%2C%20%28convert_func%29%20strdup%29.string_value%3B%0A%7D%0A
5.6 Uppdatera utils.h och utils.c
Nu är det dags att uppdatera det generella biblioteket utils.
Kopiera in dina funktioner och typalias dit. Där bör nu ligga
följande funktioner (åtminstone), i någon ordning:
- Typen
answer_t - Typen
check_func - Typen
convert_func - Deklarationen
extern char *strdup(const char *); int read_string(char *buf, int buf_siz)bool is_number(char *str)bool is_float(char *str)ochanswer_t make_float(char *)(inte obligatoriska)bool not_empty(char *str)answer_t ask_question(char *question, check_func check, convert_func convert)char *ask_question_string(char *question)int ask_question_int(char *question)double ask_question_float(char *question)(inte obligatorisk)
Själva definitionen av funktionerna (med koden i) skall ligga i
utils.c. Funktionsprototyperna (t.ex. bool is_number(char
*str);), extern... samt typedef:arna skall ligga i utils.h.
Senare under kursen skall vi diskutera mer ingående hur man skapar bibliotek/moduler, placering av funktioner och definitioner, inkapsling och synlighet.
5.7 Grand Finale! Kompilera om Gissa Talet mot nya utils redovisas
Om du har gjort allt rätt kan du kompilera om ditt Gissa
Talet-program från föregående labb mot ditt nya utils-bibliotek:
$ gcc -Wall utils.c guess.c
Du borde inte få några varningar vid kompilering (såvida du inte fick det förut – vilket du inte borde ha gjort!) och om du kör programmet igen skall det fungera precis som förut.
Verifiera att så är fallet och fixa till eventuella buggar!
5.8 Frivilliga extrauppgifter
5.8.1 Trim
En funktion som är vanlig i moderna strängbibliotek är funktionen
trim() (aka strip()) som tar bort “skräptecken” i början och
slutet av en sträng. Exakt vad ett skräptecken är naturligtvis
subjektivt, men låt oss definiera det som “whitespace” – enligt
definitionen av isspace() i ctype.h. (Använd gärna man
isspace för att ta reda på mer.)
Du skall skriva funktionen trim() som tar in en sträng och
helt enkelt tvättar bort allt “skräp”.
trim(" hej ") => "hej"
trim(" h ej ") => "h ej"
trim(" hej \n") => "hej"
Funktionens signatur:
char *trim(char *str);
char%20%2Atrim%28char%20%2Astr%29%3B%0A
Förslag till implementation:
- Ta reda på det första tecknet från vänster, S, som inte är skräp (
!isspace()) - Ta reda på det första tecknet från höger, E, som inte är skräp (
!isspace()) - Kopiera varje tecken från S till och med E till början av
str - Skriv in ett
'\0'-tecken efter det sista flyttade tecknet - Returnera
str
Lägg till trim() i utils-biblioteket!
Du kan testa att ditt program är korrekt med hjälp av följande testprogram:
#include "utils.h" int main(void) { char str1[] = " hej "; char str2[] = " h ej "; char str3[] = " hej\t "; char str4[] = " hej\t \n"; char *tests[] = { str1, str2, str3, str4 }; for (int i = 0; i < 4; ++i) { print("Utan trim: '"); print(tests[i]); print("'\nMed trim: '"); print(trim(tests[i])); println("'\n"); } return 0; }
%23include%20%22utils.h%22%0A%0Aint%20main%28void%29%0A%7B%0A%20%20char%20str1%5B%5D%20%3D%20%22%20%20hej%20%20%22%3B%0A%20%20char%20str2%5B%5D%20%3D%20%22%20%20h%20ej%20%20%22%3B%0A%20%20char%20str3%5B%5D%20%3D%20%22%20%20hej%5Ct%20%22%3B%0A%20%20char%20str4%5B%5D%20%3D%20%22%20%20hej%5Ct%20%5Cn%22%3B%0A%0A%20%20char%20%2Atests%5B%5D%20%3D%20%7B%20str1%2C%20str2%2C%20str3%2C%20str4%20%7D%3B%0A%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%204%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20print%28%22Utan%20trim%3A%20%27%22%29%3B%0A%20%20%20%20%20%20print%28tests%5Bi%5D%29%3B%0A%20%20%20%20%20%20print%28%22%27%5CnMed%20trim%3A%20%20%27%22%29%3B%0A%20%20%20%20%20%20print%28trim%28tests%5Bi%5D%29%29%3B%0A%20%20%20%20%20%20println%28%22%27%5Cn%22%29%3B%0A%20%20%20%20%7D%0A%20%20return%200%3B%0A%7D%0A
Exempel på in- och utdata:
| Ursprunglig sträng | Output från trim() |
|---|---|
" hej " |
"hej" |
" h ej " |
"h ej" |
" \nhej " |
"hej" |
" hej\n " |
"hej" |
(En modifierad version av detta program var nyligen på ett kodprov.)
Alternativ implementation:
- Gå genom strängen från vänster till höger, och så länge enbart skräptecken hittats, gör ingeting
- Från det att första skräptecknet hittats, kopiera varje tecken som passerats till början av strängen (första gången till position 0, andra till position 1, osv.) – kopiera även skräptecken. Första gången ett skräptecken kopieras efter att ett eller flera icke-skräptecken har kopierats, kom ihåg platen P för det skräptecknet (vi är bara intresserade av det sista – högraste – P:t)
- När du når slutet på strängen, skriv
\0i P
6 Labb 4: Del 1 – pekare
Pekare – adresser till platser i minnet där data är lagrat – är en viktig del av C-programmering. Genom att dela information mellan funktioner om var något är lagrat sker två saker:
- mottagaren kan läsa datat på platsen
- mottagaren kan ändra datat på platsen
Att skicka platsen där datat finns istället för att skicka själva datat kan vara väldigt effektivt. Om funktion A har en array med 10 miljoner skivspår och vill att funktion B skall hitta antalet förekomster av “Kaffe utan grädde” skulle tiden för att kopiera 10 miljoner skivspår förmodligen vara betydligt högre än kostnaden för sökningen. Genom att dela med sig av datat via en pekare istället för att kopiera hela rasket blir programmet mycket mer effektivt.
Den stora risken med pekare ligger bland annat i att B också
får rätt att ändra i datat (det går ibland att lösa med hjälp av
nyckelordet const som vi skall se senare) – och att det inte
finns något sätt för implementatören av A att veta att B
faktiskt inte modifierar datat, förutom att läsa all kod i B
(inklusive koden för alla funktioner som B anropar).
6.1 Värdesemantik vs. pekarsemantik
Fråga: Vad skriver detta program ut på skärmen när det körs?
7, 4242, 7- Något annat
#include <stdio.h> void swap(int a, int b) { int tmp = a; a = b; b = tmp; } int main(void) { int x = 7; int y = 42; swap(x, y); printf("%d, %d\n", x, y); return 0; }
%23include%20%3Cstdio.h%3E%0A%0Avoid%20swap%28int%20a%2C%20int%20b%29%0A%7B%0A%20%20int%20tmp%20%3D%20a%3B%0A%20%20a%20%3D%20b%3B%0A%20%20b%20%3D%20tmp%3B%0A%7D%0A%0Aint%20main%28void%29%0A%7B%0A%20%20int%20x%20%3D%207%3B%0A%20%20int%20y%20%3D%2042%3B%0A%20%20swap%28x%2C%20y%29%3B%0A%20%20printf%28%22%25d%2C%20%25d%5Cn%22%2C%20x%2C%20y%29%3B%0A%20%20return%200%3B%0A%7D%0A
Om det råder minsta tvekan – kör programmet!
Programmet exemplifierar värdesemantik, dvs. att vid anrop
överförs argumentens värde genom kopiering. a och b i
swap() har samma värde som x respektive y initialt, men
förändringar av a och b påverkar inte x och y.
6.2 Skriv om swap() med pekarsemantik redovisas
Namnet swap() i programmet ovan är misledande – det antyder
något som i programmet ovan inte stämmer. Nu skall vi skriva om
swap() så att det använder pekare istället. Det påverkar typerna:
int a // a är en variabel som innehåller ett heltal int *b // b är en variabel som innehåller en adress till en plats i minnet där det finns ett heltal
int%20%20a%20%20%2F%2F%20a%20%C3%A4r%20en%20variabel%20som%20inneh%C3%A5ller%20ett%20heltal%0Aint%20%2Ab%20%20%2F%2F%20b%20%C3%A4r%20en%20variabel%20som%20inneh%C3%A5ller%20en%20adress%20till%20en%20plats%20i%20minnet%20d%C3%A4r%20det%20finns%20ett%20heltal%0A
Variabeln b ovan innehåller alltså en adress. För att komma åt
det heltal som ligger på den adressen skriver vi *b. Vi säger
att vi avrefererar b. Vi har tidigare sett adresstagningsoperatorn
& som vi kan använda för att få platsen i minnet där något data finns.
Vi kan t.ex. skriva &a för att avse platsen där a:s värde finns lagrat.
Om a och b är deklarerade enligt ovan kan vi skriva:
a = 42; // a innehåller nu heltalet 42 b = &a; // b innehåller nu en adress till där värdet på a finns lagrat printf("%d, %d\n", a, *b); // skriver ut 42, 42 a = 7; printf("%d, %d\n", a, *b); // skriver ut 7, 7 *b = 42; printf("%d, %d\n", a, *b); // skriver ut 42, 42
a%20%3D%2042%3B%20%20%2F%2F%20a%20inneh%C3%A5ller%20nu%20heltalet%2042%0Ab%20%3D%20%26a%3B%20%20%2F%2F%20b%20inneh%C3%A5ller%20nu%20en%20adress%20till%20d%C3%A4r%20v%C3%A4rdet%20p%C3%A5%20a%20finns%20lagrat%0Aprintf%28%22%25d%2C%20%25d%5Cn%22%2C%20a%2C%20%2Ab%29%3B%20%20%2F%2F%20skriver%20ut%2042%2C%2042%0Aa%20%3D%207%3B%0Aprintf%28%22%25d%2C%20%25d%5Cn%22%2C%20a%2C%20%2Ab%29%3B%20%20%2F%2F%20skriver%20ut%207%2C%207%0A%2Ab%20%3D%2042%3B%0Aprintf%28%22%25d%2C%20%25d%5Cn%22%2C%20a%2C%20%2Ab%29%3B%20%20%2F%2F%20skriver%20ut%2042%2C%2042%0A
Med hjälp av pekartypen int *, adresstagningsoperatorn & och
avrefereringsoperatorn * kan vi nu skriva om swap() så att
funktionen tar in två pekare (aka adresser) till heltal, och
byter plats på värdena som finns lagrade på dessa två platser.
Målet är att skriva om Program 1 ovan så att 42, 7 skrivs ut när
det körs.
Ledning:
- Signaturen för
swap()skall varavoid swap(int *a, int *b) - Du kommer att använda avrefereringsoperatorn i implementationen av
swap() - Du måste använda adresstagningsoperatorn i
main()för att kunna anropaswap()(detta är enda ändringen du skall göra imain())
6.3 Mer om pekare och arrayer
Vi har sett att C:s strängtyp är char * och att en sträng är en
array av tecken. Ovan såg vi att int * betyder pekare till en
int. Hur kan en sträng vara både en pekare och en array? Är inte
det typvidrigt?
Skillnaden mellan arrayer och pekare i C är extremt liten, och tillsvidare kan vi betrakta pekare och arrayer som samma sak.
Typerna t * och t[] är i regel utbytbara, för varje typ t.
Det betyder t.ex. att char *argv[] också kan skrivas char
**argv. Ovan sade vi att int * betyder en pekare till en plats
i minnet där det finns ett heltal. Det var en vit lögn – det
borde vara “där det finns ett eller flera heltal.”
Arrayer i C överförs med pekare, dvs. när man skickar en array
från en funktion till en annan skickas inte en kopia av arrayen
utan bara själva adressen till den. Att det är så är inte så
konstigt om man betänker att arrayer i C inte känner till sin egen
längd (jmf. strängar vars längd vi måste räkna ut genom att räkna
antal tecken fram till '\0'). C kan alltså inte själv räkna ut
hur många bytes som skall kopieras när man kopierar en array, så
det enda alternativ som återstår är att överföra pekaren istället.
Pekararitmetik är aritmetik som innefattar adresser. Om a
har typen int * pekar a på ett heltal och a + 1 på “nästa
heltal”. Uttrycket a + 1 skapar en ny adress från adressen i
a. Observera att a + 1 alltid kan beräknas, oavsett om det
finns något “nästa heltal” eller inte – analogt med att C inte
vet längden på en array och därmed inte kan förhindra åtkomst till
element 26 i en array med bara 20 element. Det är helt enkelt
något som programmeraren måste sköta själv!
Många program som manipulerar arrayer kan skrivas om på ett
kortare sätt med pekararitmetik. Här är t.ex. funktionen
string_copy() som kopierar en sträng till en annan (kopierar
alla tecken från en array av tecken till en annan):
void string_copy(char *source, char *dest) { while (*dst++ = *source++) ; }
void%20string_copy%28char%20%2Asource%2C%20char%20%2Adest%29%0A%7B%0A%20%20while%20%28%2Adst%2B%2B%20%3D%20%2Asource%2B%2B%29%20%3B%0A%7D%0A
En bättre (mer lättläst) version:
void string_copy(char *source, char *dest) { while (*source) { *dest = *source; ++dest; ++source; } }
void%20string_copy%28char%20%2Asource%2C%20char%20%2Adest%29%0A%7B%0A%20%20while%20%28%2Asource%29%0A%20%20%7B%0A%20%20%20%20%2Adest%20%3D%20%2Asource%3B%0A%20%20%20%20%2B%2Bdest%3B%0A%20%20%20%20%2B%2Bsource%3B%0A%20%20%7D%0A%7D%0A
Eller med en for-loop (där iterationsvillkoret har blivit tydligare):
void string_copy(char *source, char *dest) { for (; *source != '\0'; ++dest, ++source) { *dest = *source; } }
void%20string_copy%28char%20%2Asource%2C%20char%20%2Adest%29%0A%7B%0A%20%20for%20%28%3B%20%2Asource%20%21%3D%20%27%5C0%27%3B%20%2B%2Bdest%2C%20%2B%2Bsource%29%0A%20%20%7B%0A%20%20%20%20%2Adest%20%3D%20%2Asource%3B%0A%20%20%7D%0A%7D%0A
För att illustrera pekararitmetik ytterligare kan vi skriva om
string_length() från labb 3 så här:
int string_length(char *str) { char *end = str; while (*end != '\0') ++end; return end - str; }
int%20string_length%28char%20%2Astr%29%0A%7B%0A%20%20char%20%2Aend%20%3D%20str%3B%0A%20%20while%20%28%2Aend%20%21%3D%20%27%5C0%27%29%20%2B%2Bend%3B%0A%20%20return%20end%20-%20str%3B%0A%7D%0A
Förklaring:
endpekar från början på starten av strängen, precis somstr- Så länge som tecknet som
endpekar på (dvs.*end) inte är'\0', flyttaend-pekaren till nästa tecken - Längden på strängen är “avståndet” mellan
endochstrnärendpekar på strängens nulltecken
6.4 Skriv om print från labb 3 med pekare istället för array-index
void print(char *str) { ... }
void%20print%28char%20%2Astr%29%0A%7B%0A%20%20%20...%0A%7D%0A
Använd str som en pekare och använd inte array-indexering
(alltså inte str[12]).
Ledning: Vi kan implementera trim()-funktionen från labb 3 på
motsvarande sätt:
char *trim(char *str) { char *start = str; char *end = start + strlen(str)-1; while (isspace(*start)) ++start; while (isspace(*end)) --end; char *cursor = str; for (; start <= end; ++start, ++cursor) { *cursor = *start; } *cursor = '\0'; return str; }
char%20%2Atrim%28char%20%2Astr%29%0A%7B%0A%20%20char%20%2Astart%20%3D%20str%3B%0A%20%20char%20%2Aend%20%3D%20start%20%2B%20strlen%28str%29-1%3B%0A%0A%20%20while%20%28isspace%28%2Astart%29%29%20%2B%2Bstart%3B%0A%20%20while%20%28isspace%28%2Aend%29%29%20--end%3B%0A%0A%20%20char%20%2Acursor%20%3D%20str%3B%0A%20%20for%20%28%3B%20start%20%3C%3D%20end%3B%20%2B%2Bstart%2C%20%2B%2Bcursor%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20%2Acursor%20%3D%20%2Astart%3B%0A%20%20%20%20%7D%0A%20%20%2Acursor%20%3D%20%27%5C0%27%3B%0A%0A%20%20return%20str%3B%0A%7D%0A
Struktar är grupperingar av värden. En strukt-deklaration skapar en ny typ som kan användas i ett C-program.
En strukt deklareras precis som en union men använder nyckelordet strukt istället:
struct point { int x; int y; };
struct%20point%0A%7B%0A%20%20int%20x%3B%0A%20%20int%20y%3B%0A%7D%3B%0A
Strukten point innehåller två fält (aka poster, ibland
medlemmar eller medlemsvariabler), x och y – båda av
heltalstyp. Ett värde av point-typ, “en point”, grupperar alltså
två värden som hör ihop, i detta fall x- och y-koordinaterna hos
en punkt. På så vis kan man skicka runt en punkt mellan funktioner
som ett sammanhållet värde, istället för att skicka en massa “lösa
variabler”. Ponera t.ex. att du skulle vilja skapa en rektangel
från två punkter – fyra koordinater. Om du inte grupperade dem
som punkter måste du komma på något system för att veta vilken
x-koordinat som hör ihop med vilken y-koordinat.
Den närmsta motsvarigheten till struktar i Haskell är definitionen av nya datatyper:
data Point = Point {x :: Int, y :: Int}
data%20Point%20%3D%20Point%20%7Bx%20%3A%3A%20Int%2C%20y%20%3A%3A%20Int%7D%0A
Struktar i C har värdesemantik – dvs. överförs med kopiering. Så här kan man skapa (och skriva ut) en strukt:
struct point p; p.x = 10; p.y = -42; printf("point(x=%d,y=%d)\n", p.x, p.y);
struct%20point%20p%3B%0Ap.x%20%3D%2010%3B%0Ap.y%20%3D%20-42%3B%0A%0Aprintf%28%22point%28x%3D%25d%2Cy%3D%25d%29%5Cn%22%2C%20p.x%2C%20p.y%29%3B%0A
Klistra in ovanstående i ett tomt program tillsammans med
struct-deklarationen av point och kör programmet. En smidig
syntax för att skapa struktar med initialvärden finns – här är
samma program skriven med hjälp av denna:
struct point p = { .x = 10, .y = -42}; printf("point(x=%d,y=%d)\n", p.x, p.y);
struct%20point%20p%20%3D%20%7B%20.x%20%3D%2010%2C%20.y%20%3D%20-42%7D%3B%0A%0Aprintf%28%22point%28x%3D%25d%2Cy%3D%25d%29%5Cn%22%2C%20p.x%2C%20p.y%29%3B%0A
Ofta använder man en typedef för att definiera ett typalias
som inte innehåller det extra struct-nyckelordet:
typedef struct point point_t;
typedef%20struct%20point%20point_t%3B%0A
Nu är struct point och point_t synomyma och vi kan skriva
vårt program så här:
point_t p = { .x = 10, .y = -42}; printf("point(x=%d,y=%d)\n", p.x, p.y);
point_t%20p%20%3D%20%7B%20.x%20%3D%2010%2C%20.y%20%3D%20-42%7D%3B%0A%0Aprintf%28%22point%28x%3D%25d%2Cy%3D%25d%29%5Cn%22%2C%20p.x%2C%20p.y%29%3B%0A
Värt att notera med { .x = 10, .y = -42 }-syntaxen är att det är
tillåtet att utelämna fält som då får defaultvärden enligt följande:
- heltalsfält får värdet 0
- flyttalsfält får värdet 0
- booleska fält fär värdet false
- pekarfält får värdet
NULLsom betyder att de ännu inte pekar ut något – vi skall återkomma tillNULLsenare
Följande program är alltså legalt (kör det gärna för att verifiera att din uträkning av vad det skriver ut stämmer):
point_t p1 = { .x = 10 }; point_t p2 = { .y = -42 }; point_t p3 = { }; printf("point(x=%d,y=%d)\n", p1.x, p1.y); printf("point(x=%d,y=%d)\n", p2.x, p2.y); printf("point(x=%d,y=%d)\n", p3.x, p3.y);
point_t%20p1%20%3D%20%7B%20.x%20%3D%2010%20%7D%3B%0Apoint_t%20p2%20%3D%20%7B%20.y%20%3D%20-42%20%7D%3B%0Apoint_t%20p3%20%3D%20%7B%20%7D%3B%0A%0Aprintf%28%22point%28x%3D%25d%2Cy%3D%25d%29%5Cn%22%2C%20p1.x%2C%20p1.y%29%3B%0Aprintf%28%22point%28x%3D%25d%2Cy%3D%25d%29%5Cn%22%2C%20p2.x%2C%20p2.y%29%3B%0Aprintf%28%22point%28x%3D%25d%2Cy%3D%25d%29%5Cn%22%2C%20p3.x%2C%20p3.y%29%3B%0A
Eftersom struktar har värdesemantik tar följande funktion för att flytta en punkt i planet in två struktar och skapar en ny, flyttad punkt, som returneras:
struct point translate(point_t p1, point_t p2) { p1.x += p2.x; p1.y += p2.y; return p1; }
struct%20point%20translate%28point_t%20p1%2C%20point_t%20p2%29%0A%7B%0A%20%20p1.x%20%2B%3D%20p2.x%3B%0A%20%20p1.y%20%2B%3D%20p2.y%3B%0A%20%20return%20p1%3B%0A%7D%0A
Om vi vill skriva om translate() så att den punkt som skickas in
förändras (en så-kallad sido-effekt) kan vi göra det med hjälp av
pekare:
void translate(point_t *p1, point_t *p2) { p1->x += p2->x; p1->y += p2->y; }
void%20translate%28point_t%20%2Ap1%2C%20point_t%20%2Ap2%29%0A%7B%0A%20%20p1-%3Ex%20%2B%3D%20p2-%3Ex%3B%0A%20%20p1-%3Ey%20%2B%3D%20p2-%3Ey%3B%0A%7D%0A
Observera att .-notationen för att komma åt fält i en strukt
byts ut mot pilar -> när man gör åtkomst till fält i en pekare
till en strukt.
En anledning till pilnotationen är för att förtydliga att vi inte
vet så mycket om värdet vars fält vi läser och skriver. I den
sista implementationen av translate() är det t.ex. möjligt att
anropa translate med samma argument två gånger:
point_t p = { .x = 10, .y = 7 }; translate(&p, &p);
point_t%20p%20%3D%20%7B%20.x%20%3D%2010%2C%20.y%20%3D%207%20%7D%3B%0Atranslate%28%26p%2C%20%26p%29%3B%0A
(observera &p eftersom funktionen vill ha adressen till där
punkten finns, inte en kopia av själva punkten).
Om translate anropas med samma punkt som första och andra argument kommer även det andra argumentet att förändras. Det är förmodligen lite överraskande (varför skulle den det?) och detta illustrerar att pekare är kraftfulla men också knepiga att programmera med.
6.5 Punkter, rektanglar och cirklar
Börja med att skapa en ny fil geo.c med en tom main()-metod etc.
Kopiera dit struktdefinitionen för punkt, samt typaliaset och
den sista translate()-funktionen.
- Skriv en funktion
print_point()som tar enpoint_t *(pekare alltså!) som argument och skriver ut den på terminalen på formatet(x-värde,y-värde). Testa den genom att skriva ut en lämplig punkt. - Skriv funktionen
make_point()som tar in två heltal som x- och y-koordinater och returnerar enpoint_t. Testa den med hjälv avprint_point(). - Definiera en strukt för rektanglar. En
struct rectanglerepresenteras som två punkter, dvs. dess övre vänstra hörn och dess nedre högra hörn. - Definiera ett typalias
rectangle_ttillstruct rectangle - Skriv funktionen
print_rect()som tar in en pekare till en rektangel och skriver ut den på terminalen på formatetrectangle(upper_left=(x,y), lower_right=(x,y)). Användprint_point()för att implementera funktionen. Ändra sedanprint_point()till att skriva utpoint(x,y)istället och kompilera om programmet och se att förändringen också får genomslagskraft i definitionen avprint_rect(). - Skriv funktionen
make_rect()som tar in fyra heltal och utifrån dem skapar en rektangel. Testa den med hjälp avprint_rect(). - Skriv funktionen
area_rect()som tar in en pekare till en rektangel och räknar ut dess area (dvs. basen * höjden). Testa den på några enkla exempel vars areor du enkelt kan räkna ut själv. - Skriv funktionen
intersects_rect()som tar in två pekare till rektanglar och returnerartrueom det finns minst en punkt i planet som finns i båda rektanglarna, annarsfalse. Testa den med både negativa och positiva exempel, alltså både med rektanglar som överlappar och rektanglar som inte gör det. - Skriv funktionen
intersection_rect()som tar in två pekare till rektanglar R1 och R2 och returnerar en ny rektangel (med värdesemantik) som är den minsta rektangel som innefattar alla punkter som som finns i både R1 och R2. Testa den med de positiva exemplen från föregående fråga. - Frivillig Definiera en strukt för cirklar med en
point_tsom mittpunkt och ett heltal som radie. - Frivillig Definiera ett typalias
circle_tför cirklar. - Frivillig Definiera en
print_circle()som skriver utcircle(center=point(x,y), radius=r). - Frivillig Definiera en
make_circle(). - Frivillig Definiera en
area_circle()som räknar ut arean på en cirkel som \(\pi \cdot{} r^2\) (där \(r\) = radie). Du kan använda lämpliga funktioner och konstanter imath.hför att lösa uppgiften. Returtypen påarea_circle()skall vara ett flyttal.
6.6 Databas redovisas
Detta program skall skrivas i filen db.c. Du kommer att kunna återanvända
delar av detta program i en inlämningsuppgift senare på kursen!
En vara har ett namn, en beskrivning, ett pris och en lagerhylla som avser platsen där den är lagrad.
- Namn och beskrivning skall vara strängar (
char *) - Pris skall vara i ören och är därför ett heltal (
int) - Lagerhylla skall vara en bokstav åtföljd av en eller flera
siffror t.ex.
A25men inteA 25eller25A(en möjlig datatyp för detta är t.ex.char *– det tillåter lagerhyllor som inte följer formatet, så kontrollen att endast valida lagerhyllor finns i varor måste ske någon annanstans!)
6.6.1 Deluppgift 1: deklarationer
Deklarera en strukt item (för en vara) enligt ovan och ett typalias item_t.
6.6.2 Deluppgift 2: skriva ut varor
Definiera en funktion print_item som tar emot en pekare till en vara
och skriver ut en vara på följande format:
Name: XXXXX Desc: XXXXX Price: XX.XX SEK Shelf: XXX (t.ex. A25)
Tips: decimalkommat i Price går lätt att göra med
heltalsdivision, modulo och printf då vi vet att priset alltid är
i ören. T.ex. price / 100 blir alltid jämna kronor och .:en
kan vara en del av det som skrivs ut.
6.6.3 Deluppgift 3: skapa en vara
Skriv en funktion make_item() som tar som indata namn,
beskrivning, pris och lagerhylla. Funktionen make_item kan
förutsätta att lagerhyllans format är korrekt.
6.6.4 Deluppgift 4: läs in en vara från terminalen
Skriv en funktion input_item() som använder hjälpfunktionerna
ask_question_string() och ask_question_int() för att läsa in namn,
beskrivning och pris på en vara. Definiera ytterligare en
hjälpfunktion ask_question_shelf() för att läsa in en lagerhylla
och verfiera att formatet är korrekt enligt specifikationen ovan.
Du kommer att behöva en ny kontrollfunktion för lagerhyllor som är
ganska lik is_number() (men första teckenet får vara en
bokstav). Som konverteringsfunktion fungerar strdup() eftersom
representationen för lagerhyllan är en sträng.
6.6.5 Deluppgift 5: kaosmagi
Skriv en funktion magick() som genererar ett slumpnamn för
varor med hjälp av kaosmagi. För denna uppgift definieras kaosmagi
som tre slumpmässiga val från tre sträng-arrayer av samma längd som
skickas in till magick() och kombineras till ett namn.
Exempel:
char *array1[] = { "Laser", "Polka", "Extra" }; char *array2[] = { "förnicklad", "smakande", "ordinär" }; char *array3[] = { "skruvdragare", "kola", "uppgift" }; char *str = magick(array1, array2, array3, 3); // 3 = längden på arrayerna puts(str); // Polka-ordinär skruvdragare
char%20%2Aarray1%5B%5D%20%3D%20%7B%20%22Laser%22%2C%20%20%20%20%20%20%20%20%22Polka%22%2C%20%20%20%20%22Extra%22%20%7D%3B%0Achar%20%2Aarray2%5B%5D%20%3D%20%7B%20%22f%C3%B6rnicklad%22%2C%20%20%20%22smakande%22%2C%20%22ordin%C3%A4r%22%20%7D%3B%0Achar%20%2Aarray3%5B%5D%20%3D%20%7B%20%22skruvdragare%22%2C%20%22kola%22%2C%20%20%20%20%20%22uppgift%22%20%7D%3B%0A%0Achar%20%2Astr%20%3D%20magick%28array1%2C%20array2%2C%20array3%2C%203%29%3B%20%2F%2F%203%20%3D%20l%C3%A4ngden%20p%C3%A5%20arrayerna%0A%0Aputs%28str%29%3B%20%2F%2F%20Polka-ordin%C3%A4r%20skruvdragare%0A
Algoritmen fungerar som följer:
- Skapa en
char buf[255]att hålla det nya ordet i - Välj ett slumpmässigt ord från array1 och skriv in det i
buf - Skriv in ett
'-'sist ibuf - Välj ett slumpmässigt ord från array2 och skriv in det sist i
buf - Skriv in ett
' 'sist ibuf - Välj ett slumpmässigt ord från array3 och skriv in det sist i
buf - Skriv in ett
'\0'sist ibuf - returnera
strdup(buf);
Vi kommer att återkomma till den “magiska” strdup()-funktionen
senare i kursen: enkelt förklarat tillhör buf-bufferten
magick()- funktionen och för att få skicka tillbaka strängen
till den anropande funktionen måste vi duplicera den.
Du kan använda följande main()-funktion som läser in ett tal
från kommandoraden, anropar input_item() lika många gånger, och
sedan använder magick() för att skapa en databas med 16 varor
som sedan skrivs ut på skärmen. Du måste lägga till arrayerna
med ord själv, och deras längd – sök efter TODO: för att hitta
de platser som du måste ändra nedan.
int main(int argc, char *argv[]) { char *array1[] = { ... }; // TODO: Lägg till! char *array2[] = { ... }; // TODO: Lägg till! char *array3[] = { ... }; // TODO: Lägg till! if (argc < 2) { printf("Usage: %s number\n", argv[0]); } else { item_t db[16]; // Array med plats för 16 varor int db_siz = 0; // Antalet varor i arrayen just nu int items = atoi(argv[1]); // Antalet varor som skall skapas if (items > 0 && items <= 16) { for (int i = 0; i < items; ++i) { // Läs in en vara, lägg till den i arrayen, öka storleksräknaren item_t item = input_item(); db[db_siz] = item; ++db_siz; } } else { puts("Sorry, must have [1-16] items in database."); return 1; // Avslutar programmet! } for (int i = db_siz; i < 16; ++i) { char *name = magick(array1, array2, array3, ...); // TODO: Lägg till storlek char *desc = magick(array1, array2, array3, ...); // TODO: Lägg till storlek int price = random() % 200000; char shelf[] = { random() % ('Z'-'A') + 'A', random() % 10 + '0', random() % 10 + '0', '\0' }; item_t item = make_item(name, desc, price, shelf); db[db_siz] = item; ++db_siz; } // Skriv ut innehållet for (int i = 0; i < db_siz; ++i) { print_item(&db[i]); } } return 0; }
int%20main%28int%20argc%2C%20char%20%2Aargv%5B%5D%29%0A%7B%0A%20%20char%20%2Aarray1%5B%5D%20%3D%20%7B%20...%20%7D%3B%20%2F%2F%20TODO%3A%20L%C3%A4gg%20till%21%0A%20%20char%20%2Aarray2%5B%5D%20%3D%20%7B%20...%20%7D%3B%20%2F%2F%20TODO%3A%20L%C3%A4gg%20till%21%0A%20%20char%20%2Aarray3%5B%5D%20%3D%20%7B%20...%20%7D%3B%20%2F%2F%20TODO%3A%20L%C3%A4gg%20till%21%0A%0A%20%20if%20%28argc%20%3C%202%29%0A%20%20%7B%0A%20%20%20%20printf%28%22Usage%3A%20%25s%20number%5Cn%22%2C%20argv%5B0%5D%29%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20item_t%20db%5B16%5D%3B%20%2F%2F%20Array%20med%20plats%20f%C3%B6r%2016%20varor%0A%20%20%20%20int%20db_siz%20%3D%200%3B%20%2F%2F%20Antalet%20varor%20i%20arrayen%20just%20nu%0A%0A%20%20%20%20int%20items%20%3D%20atoi%28argv%5B1%5D%29%3B%20%2F%2F%20Antalet%20varor%20som%20skall%20skapas%0A%0A%20%20%20%20if%20%28items%20%3E%200%20%26%26%20items%20%3C%3D%2016%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20items%3B%20%2B%2Bi%29%0A%20%20%20%20%20%20%7B%0A%09%2F%2F%20L%C3%A4s%20in%20en%20vara%2C%20l%C3%A4gg%20till%20den%20i%20arrayen%2C%20%C3%B6ka%20storleksr%C3%A4knaren%0A%09item_t%20item%20%3D%20input_item%28%29%3B%0A%09db%5Bdb_siz%5D%20%3D%20item%3B%0A%09%2B%2Bdb_siz%3B%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%20%20else%0A%20%20%20%20%7B%0A%20%20%20%20%20%20puts%28%22Sorry%2C%20must%20have%20%5B1-16%5D%20items%20in%20database.%22%29%3B%0A%20%20%20%20%20%20return%201%3B%20%2F%2F%20Avslutar%20programmet%21%0A%20%20%20%20%7D%0A%0A%20%20%20%20for%20%28int%20i%20%3D%20db_siz%3B%20i%20%3C%2016%3B%20%2B%2Bi%29%0A%20%20%20%20%20%20%7B%0A%09char%20%2Aname%20%3D%20magick%28array1%2C%20array2%2C%20array3%2C%20...%29%3B%20%2F%2F%20TODO%3A%20L%C3%A4gg%20till%20storlek%0A%09char%20%2Adesc%20%3D%20magick%28array1%2C%20array2%2C%20array3%2C%20...%29%3B%20%2F%2F%20TODO%3A%20L%C3%A4gg%20till%20storlek%0A%09int%20price%20%3D%20random%28%29%20%25%20200000%3B%0A%09char%20shelf%5B%5D%20%3D%20%7B%20random%28%29%20%25%20%28%27Z%27-%27A%27%29%20%2B%20%27A%27%2C%0A%09%09%09%20random%28%29%20%25%2010%20%2B%20%270%27%2C%0A%09%09%09%20random%28%29%20%25%2010%20%2B%20%270%27%2C%0A%09%09%09%20%27%5C0%27%20%7D%3B%0A%09item_t%20item%20%3D%20make_item%28name%2C%20desc%2C%20price%2C%20shelf%29%3B%0A%0A%09db%5Bdb_siz%5D%20%3D%20item%3B%0A%09%2B%2Bdb_siz%3B%0A%20%20%20%20%20%20%7D%0A%0A%20%20%20%20%20%2F%2F%20Skriv%20ut%20inneh%C3%A5llet%0A%20%20%20%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20db_siz%3B%20%2B%2Bi%29%0A%20%20%20%20%20%7B%0A%20%20%20%20%20%20%20print_item%28%26db%5Bi%5D%29%3B%0A%20%20%20%20%20%7D%0A%0A%20%20%7D%0A%20%20return%200%3B%0A%7D%0A
6.6.6 Lista databasens innehåll
Skriv en funktion void list_db(item_t *items, int no_items) som
skriver ut namnen på alla varor i databasen, samt deras index i
arrayen + 1:
1. XXX 2. YYY ... 16. ZZZ
Ersätt utskriften av innehållet i databasen med ett anrop till
list_db() istället. Använd db_siz som storleken på databasen
(no_items i list_db()).
Observera att databasen är en variabel som är deklarerad i main().
6.6.7 Editera databasen
Skriv en funktion edit_db() som:
- Frågar efter vilken vara som skall editeras (ett heltal som
motsvarar heltalen i listningen ovan) med hjälp av
ask_question_int() - Skriver ut varan på skärmen med hjälp av
print_item() - Låter användaren ersätta varan med en annan som läses in med
input_item()
Fundera över:
- Vad behöver
edit_db()ta som inparametrar? - Hur sparar vi förändringarna som användaren matar in i databasen?
- Hur skall programmet bete sig om användaren matar in en siffra för vilken det inte finns en vara? (t.ex. -27 eller 42 när databasen bara har 16 varor)
6.6.8 Frivilliga utökningar
- Låt användaren välja vilken del av varan som skall ändras, t.ex. bara priset
- Bygg in stöd för att lägga in helt nya varor om det finns plats
(dvs.
db_sizär mindre än databasens faktiska storlek)
7 Labb 5: mer I/O och utökning av db.c
I slutet av den här labben ska du ladda upp dina resultat på GitHub. Glöm inte att göra det!
Hittills har vi talat om att läsa och skriva till och från terminalen. Lyckligtvis är en grundläggande abstraktion kring I/O i C baserad på filer – oavsett om vi skall läsa från tangentbordet eller från en plats på hårddisken.
Följande program läser tecken för tecken från s.k. stdin som är
en fil som normalt är knuten till terminalen i våra C-program.
stdin motsvarar helt enkelt inläsning från tangentbordet.
Skrivning sker analogt till stdout och allt som skrivs dit visas
i terminalen i våra program.
/// passthrough.c #include <stdio.h> int main(void) { int c = getchar(); int safety = 1024; while (c != EOF && --safety > 0) { putchar(c); c = getchar(); } return 0; }
%2F%2F%2F%20passthrough.c%0A%23include%20%3Cstdio.h%3E%0A%0Aint%20main%28void%29%0A%7B%0A%20%20int%20c%20%3D%20getchar%28%29%3B%0A%20%20int%20safety%20%3D%201024%3B%0A%0A%20%20while%20%28c%20%21%3D%20EOF%20%26%26%20--safety%20%3E%200%29%0A%20%20%7B%0A%20%20%20%20putchar%28c%29%3B%0A%20%20%20%20c%20%3D%20getchar%28%29%3B%0A%20%20%7D%0A%0A%20%20return%200%3B%0A%7D%0A
Detta program läser max 1024 gånger från stdin och skriver
det som lästes på stdout. Så här kan en körning se ut:
$ gcc passthrough.c $ ./a.out hej <-- input hej <-- skrivs ut hopp i galopp <-- input hopp i galopp <-- skrivs ut ^C <-- ctrl+c för att avbryta $ _
Med hjälp av | kan du tala om att output från ett program skall
skickas till ett annat (på Linux och OS X):
$ gcc passthrough.c $ head -n 3 passthrough.c # skriver ut första 3 raderna i passthrough.c /// passthrough.c #include <stdio.h> $ head -n 3 passthrough.c | wc -l # räkna antalet rader i input 3 $ head -n 3 passthrough.c | ./a.out /// passthrough.c #include <stdio.h>
Observera att när vi skickade output från head till a.out (vår
kompilerade passthrough.c) så skrevs den ut igen, precis som om vi
hade skrivit in den via terminalen.
Programmet vet alltså inte om om det läser från en fil eller från ett annat program.
Här är några hjälpfunktioner för att explicit läsa från en fil inifrån C (istället för att skicka in den utifrån som ovan):
- Funktionen
fopen()tar som input två strängar – den första är filnamnet och den andra beskriver hur filen skall öppnas. För läsning:"r", för skrivning"w", och"a"för append.fopen()returnerar enFILE *– dvs. en pekare till en fil som kan användas för att läsa från/skriva till beroende på hur filen öppnades ("r", etc.). fclose()stänger en öppen fil.fprintf()fungerar somprintf()men är inte låst tillstdout–printf(...)är ekvivalent medfprintf(stdout, ...). Alltså,fprintf(fil, ...)skriver ut på filenfil.fgetc(fil)läser ett tecken från filenfil.fscanf(fil, ...)läser somscanf()fast från filenfil.- etc.
7.1 Uppvärmning: Cat med radnumrering
Nedan följer en version av programmet cat som läser en fil och
skriver ut filen på terminalen (stdout). Programmet är väldigt
likt passthrough.c ovan – med skillnaden att vi vill öppna en
namngiven fil, inte stdin:
/// cat.c #include <stdio.h> void cat(char *filename) { FILE *f = fopen(filename, "r"); int c = fgetc(f); while (c != EOF) { fputc(c, stdout); c = fgetc(f); } fclose(f); } int main(int argc, char *argv[]) { if (argc < 2) { fprintf(stdout, "Usage: %s fil1 ...\n", argv[0]); } else { for (int i = 1; i < argc; ++i) { cat(argv[i]); } } return 0; }
%2F%2F%2F%20cat.c%0A%23include%20%3Cstdio.h%3E%0A%0Avoid%20cat%28char%20%2Afilename%29%0A%7B%0A%20%20FILE%20%2Af%20%3D%20fopen%28filename%2C%20%22r%22%29%3B%0A%20%20int%20c%20%3D%20fgetc%28f%29%3B%0A%0A%20%20while%20%28c%20%21%3D%20EOF%29%0A%20%20%7B%0A%20%20%20%20fputc%28c%2C%20stdout%29%3B%0A%20%20%20%20c%20%3D%20fgetc%28f%29%3B%0A%20%20%7D%0A%0A%20%20fclose%28f%29%3B%0A%7D%0A%0Aint%20main%28int%20argc%2C%20char%20%2Aargv%5B%5D%29%0A%7B%0A%20%20if%20%28argc%20%3C%202%29%0A%20%20%7B%0A%20%20%20%20fprintf%28stdout%2C%20%22Usage%3A%20%25s%20fil1%20...%5Cn%22%2C%20argv%5B0%5D%29%3B%0A%20%20%7D%0A%20%20else%0A%20%20%7B%0A%20%20%20%20for%20%28int%20i%20%3D%201%3B%20i%20%3C%20argc%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20cat%28argv%5Bi%5D%29%3B%0A%20%20%20%20%7D%0A%20%20%7D%0A%0A%20%20return%200%3B%0A%7D%0A
(observera att detta program inte fungerar så bra om vi anger filer som inte finns – men det är inget du behöver fixa.)
Titta på programmet ovan: i funktionen cat() läser vi infilen
tecken för tecken. Nu vill vi skriva ut filen så att varje rad
börjar med ett radnummer. Här är ett exempel från texten i labben:
1 Titta på programmet ovan: ... 2 tecken för tecken. Nu vill ... 3 börjar med ett radnummer ...
- Ha en räknare för antalet rader i
cat()som börjar på 1 - Skriv ut 1 innan vi går in i loopen i
cat() - Tecknet
'\n'är radslutsteckenet – efter varje sådant tecken kommer en ny rad- Inkrementera räknaren
- Skriv ut räknaren
Uppvärmning: Frivilliga utökningar av cat
- Utöka programmet så att när flera filer skrivs ut (stöds redan) börjar radräknaren inte om från 0 vid varje ny fil
- Innan varje fil skrivs ut, skriv ut
==== filnamn.ext ====i terminalen - Skriv om
cat.ctillcp.coch låt programmet kopiera från en fil till en annan, tecken för tecken, analogt med programmetcp
7.2 Slutprojektet på labbarna: Utökning av databasen
Nu skall vi avsluta vår implementation av databasprogrammet. I en senare inlämningsuppgift skall vi utöka databasen med stöd för att spara och ladda databasen på fil med hjälp av funktionerna ovan (och andra), men det är lite för tidigt ännu. Istället skall vi utöka programmet med en interaktiv meny, och stöd för insättning och borttagning.
7.2.1 Menyfunktionalitet 1/2
Vi skall utöka programmet med en meny med olika val:
[L]ägga till en vara [T]a bort en vara [R]edigera en vara Ån[g]ra senaste ändringen Lista [h]ela varukatalogen [A]vsluta
Skriv en funktion print_menu() som skriver ut ovanstående text
på stdout.
Guldstjärna för att göra utskriften med endast en enda puts()
eller printf() utan att göra utskriftssträngen oläslig.
7.2.2 Menyfunktionalitet 2/2
Skriv en funktion ask_question_menu() som skriver ut menyn
med print_menu() och sedan låter användaren mata in sitt val.
Funktionen skall kontrollera att resultatet som användaren matar
in är giltigt (följande tecken LlTtRrGgHhAa) och fråga om tills
ett giltigt val gjorts. Funktionen skall returnera valet som ett
enda tecken (en char) som skall vara en stor bokstav. Funktionen
toupper() i ctype.h kan användas för att konvertera en gemen
till en versal.
Om du vill kan du använda din generiska ask_question()-funktion.
Du måste skriva en ny kontrollfunktion from kontrollerar att input
är ett tecken i strängen "LlTtRrGgHhAa", och antingen utöka
answer_t eller låta tecknet vara ett heltal. Om du gör på detta
vis behövs inte print_menu()-funktionen längre, eller så kan du
använda denna funktion för att returnera strängen som skall
skrivas ut. (OBS! Inget strdup() i denna funktion i så fall!)
7.2.3 Tillägg i databasen
Skriv en funktion add_item_to_db() som lägger till en vara i
databasen med input_item() från föregående labb. Du kan
förutsätta att det finns plats i databasen.
- Vad skall funktionen ta som input?
- Vad skall funktionen returnera?
7.2.4 Borttag ur databasen
Skriv en funktion remove_item_from_db() som tar bort en vara
från databasen. Använd list_db() för att skriva ut databasen och
samma metod som vid edit_db() för att välja vilken vara som
skall tas bort.
När man tar bort något ur en array måste man “skriva över” det man
vill ta bort med elementen till höger. Dvs. ponera arrayen A med
elementen [1, 2, 3, 4]. Variabeln as håller reda på antalet
element i A och är just nu 4.
Om jag vill ta bort 1:an kan jag göra det genom att kopiera 2:an
till 1:ans plats, 3:an till 2:ans plats och så vidare. Det betyder
att det kommer att finnas två 4:or sist i arrayen –
[2, 3, 4, 4] – men om jag också minskar as till 3 och
respekterar detta kommer jag inte att läsa den andra fyran. Vid
insättning skrivs den över och as ökar till 4. Motsvarigheten
till A i vårt program är förstås db och as db_siz.
Kopieringen sker lämpligen från höger till vänster. Notera att om jag i ovanstående exempel ville ta bort 4:an räcker det med att bara miska as med 1. Om jag ville ta bort 3:an räcker det med att kopiera över 3:an med 4:an, lämna 1 och 2, och minska as med 1.
7.2.5 Integration redovisas
Skriv en funktion event_loop() som anropar ask_question_menu()
och baserat på svaret antingen add_item_to_db(),
remove_item_from_db(), edit_db(), list_db() för
motsvarande menyval. För ångra-valet skall ett meddelande Not yet
implemented! skrivas ut. Och vid avsluta skall event_loop()
funktionen terminera och programmet avslutas.
7.2.6 Frivilligt: Utökad vara
7.2.7 Frivilligt: stöd för ångra
Implementera stöd för att ångra. Detta omfattar:
- Vid borttagning, spara det som togs bort
- Vid redigering, spara originalet
- Vid insättning, spara vilken vara som lades till
- Spara alltid vilken som var den senaste handlingen som kan ångras – du kan t.ex. använda ett heltal för att hålla koll på vad det var för typ av handling (den mest eleganta lösningen involverar funktionspekare)
- När användaren väljer ångra, inspektera vilken handling som var den senaste, och ångra den
- Om du vill kan du implementera stöd för att ångra själva ångrandet
8 Ladda upp alla dina labbar på GitHub
Du bör ha fått ett GitHub-repo från oss på en adress som liknar
https://github.com/IOOPM-UU/fornamn.efternamn.1234, där
fornamn.efternamn.1234 är ditt student-ID (om du inte har fått
det, följ dessa instruktioner. Här ska du ladda upp alla uppgifter
som du har redovisat under de här veckorna. Det finns många sätt
att ladda upp filer till GitHub, och här går vi igenom ett sätt
att göra det via terminalen.
- Klona ditt repo (om du inte redan har gjort det):
git clone https://github.com/IOOPM-UU/fornamn.efternamn.1234Detta skapar en mapp som heterfornamn.efternamn.1234som du kan synka med online-versionen på GitHub. Du kan döpa mappen till vad som helst och lägga den var du vill. - Kopiera eller flytta över filerna som behövs för att kompilera
och köra dina labbar i respektive mapp. Till exempel bör
labbar/lab2innehållaguess.c,utils.csamtutils.h. Om du har sparat dina gamla labbar i en mapp som heterioopmsom ligger i samma mapp som ditt klonade repo kan du köra:
$ cp ioopm/lab2/guess.c fornamn.efternamn.1234/fas1/bootstrap/lab2/ $ cp ioopm/lab2/utils.c fornamn.efternamn.1234/fas1/bootstrap/lab2/ $ cp ioopm/lab2/utils.h fornamn.efternamn.1234/fas1/bootstrap/lab2/
- För varje labb, gå till respektive mapp och markera att du vill
synka dessa med kommandot
git add. Bunta sedan ihop ändringarna till en “commit” med commandotgit commit. Till exempel (flaggan-manvänds för att ge en beskrivande text till en commit):
$ cd fornamn.efternamn.1234/fas1/bootstrap/lab2 $ ls README.md utils.c guess.c utils.h $ git add guess.c $ git add utils.c $ git add utils.h $ git commit -m "Lade till labb 2"
- Slutligen, synka online-versionen med din egen version genom
att “knuffa upp” dina ändringar (alltså dina commits) med
kommandot
git push. Nu ska du kunna se ändringarna på GitHub!
Om du vill lära dig mer om Git och GitHub finns det många guider online. Du hittar några av dem i vårt länkbibliotek. Det finns också en kortare lathund med de vanligaste Git-kommandona. En gammal students anteckningar ligger till grund för ytterligare en GitHub-guide.
Nu är du klar med C-labbarna. Bra jobbat! Det är dags att pusta ut, kanske föra några anteckningar om saker som du tänkt på, frågor som du vill ställa, misstag som du verkar upprepa, etc.
När du har tagit en paus är det dags för inlämningsuppgift 1!
Questions about stuff on these pages? Use our Piazza forum.
Want to report a bug? Please place an issue here. Pull requests are graciously accepted (hint, hint).
Nerd fact: These pages are generated using org-mode in Emacs, a modified ReadTheOrg template, and a bunch of scripts.
Ended up here randomly? These are the pages for a one-semester course at 67% speed on imperative and object-oriented programming at the department of Information Technology at Uppsala University, created by Tobias Wrigstad.
Footnotes:
cp p1.c p2.c eller
använda C-x C-w p2.c om du står i p1.c i Emacs, dvs.
“spara som”.