Assignment 1 (Phase 1, Sprint 1)
Table of Contents
- 1. Introduction
- 2. Ticket #1: Implement a Basic Hash Table
- 3. Left: Test-Driven Approach
- 4. Right: Classical Approach
- 5. Ticket #2: Utility Functions
- 6. Ticket #3: More, More Basic, Data Structures
- 7. Ticket #4: Refactoring and Improvements
- 7.1. Step 12: Refactoring of Hash Table and Linked List
- 7.2. Step 13: Supporting Arbitrary Data as Elements, Keys and Values
- 7.2.1. Where Does
elem_tbelong? - 7.2.2. Pass Function Pointers to the List’s Constructor
- 7.2.3. Using Function Pointers to Operate on Elements
- 7.2.4. Update the Iterator
- 7.2.5. Update the Hash Table to Support Generic Data
- 7.2.6. Update
ioopm_hash_table_values()to Return a Linked List - 7.2.7. Finish This Step
- 7.2.1. Where Does
- 7.3. Step 14: Performance Testing
- 7.4. Step 15: Wrapping Up
Intended start: 2018-09-17
Soft deadline: 2018-10-05
Hard deadline: 2018-10-19
1 Introduction
This assignment serves several purposes:
- Demonstrate typical imperative programming idioms, and typical C idioms.
- Get you started in using programming tools – other than just
editors, compilers and debuggers. In particular, we will be
using a profiler (
gprof), a coverage tracker (gcov), and a memory leak detector (valgrind). And of course version control. - Create multiple opportunities to demonstrate mastery of achievements.
- Force you to code – reading and writing code are the only two techniques that work when learning how to program, and only if you do both.
Concretely, the assignment will have you develop a small library1 of data structures for C programs together with some minimal “driver programs” that use your data structures, and tests for your data structures.
Note that Assignment 2 will be built on-top of the data structures you develop now, and be a lot more free. Thus, it will pay off to do a good job now, as it will simplify the work of the next assignment.
By the end of this sprint you should have:
- Implemented a full-featured, generic hash table and linked list and an iterator for the latter.
- Demonstrated a suitable number of goals (make your own calculation based on your required velocity2).
- Started to get a feeling for what good code is, what bad code is, and where your code sits on that continuum.
- Have written about 1000 lines of code (LOC) plus another 1000 lines of test code. (This of course depends on your coding style. If you hit say 2000 LOC without counting tests, you probably need some help. Data point: Students on IOOPM who finished early wrote 1700–2500 LOC.)
1.1 Prerequisites to Start
- You should have finished the C boot-strapping exercises, which involves:
- Having familiarised yourself with the SIMPLE programming methodology, and understanding key concepts like dodging and cheating.
- Having familiarised yourself with Emacs, the editor we are using for at least the C part of the course.
- You should have found a partner to work with from your team.
- You should have gotten a GitHub repo from the course. Naturally, you are to place all files belonging to this assignment in the folder for Assignment 1.
- Make sure you have a working development environment for C.
Both 3. and 4. should trivially be the case if you are done with 1.
1.2 Organisation of this Document
Rather than simply giving you a list of things to do based on the
knowledge one has after having implemented similar things, the
assignment is going to have a story line. Thus, we will be making
judgment calls, backing out of decisions that turned out to be
sub-optimal, refactoring parts of the code as we develop better
ways of accomplishing tasks and want to back-port them to be used
everywhere, etc. etc. Because we are going to incrementally
evolve this code, make sure to use version control properly. At a
minimum, follow the instructions to check in at the end of each
step. That way, it will be much simpler to dig up old versions of
a function etc. if needed. If you find yourself making copies of
source files, like hash_table_step12.c, you are doing it
wrong. (Please ask for help if you don’t understand why!)
If you are already a good C programmer, you may be frustrated by the way this assignment progresses. In that case, I’d like to know when you are feedbacking to me at the end of this assignment. If you are a seasoned C programmer paired with a novice programmer, remember that the goal of the assignment is not to implement something – it is to learn something, and implementing is a means to this end.
Also, please – unless explicitly asked to – do not Google how to write X in C until you have read and tinkered with the explanations of this document. In general, please refrain from using Google and Stackoverflow (etc.) during this assignment – use Piazza instead.
The entire assignment is laid out as a series of steps with the intended velocity of 1-2 steps per weekday on average. Note that not all steps have equal length. Expect early steps to take longer (inverse proportional to your past coding experience perhaps?). If you want to plan ahead, read ahead and take notes of what is coming up. Early on, expect to be stuck on a compile error on a single line for an hour at times (ask for help if stuck on a compile error >20 minutes). Later on, expect to be mostly stuck debugging some behaviour in your program. Bottom-line: how long each step will take is hard to plan, and is going to be very individual.
1.3 Organisation of Files
If you are relatively new to programming, it may not be clear to you what the file structure could look like for this assignment. Here is an example of what your directory could look like when you are done with the entire assignment.
assig1/ # the directory containing all files ├── common.h # all common declarations ├── hash_table.c # hash table code ├── hash_table.h # hash table declarations ├── hash_table_tests.c # hash table tests ├── linked_list.c # linked list and iterator code ├── linked_list.h # linked list declarations ├── linked_list_tests.c # linked list tests ├── iterator.h # iterator declarations ├── Makefile # for compiling, testing, running └── README.md # report and build instructions (written by you)
2 Ticket #1: Implement a Basic Hash Table
The main work of this assignment will be done in the files
hash_table.h and hash_table.c. The former is the header file,
which declares functions and some necessary types. The latter
contains all struct definitions and function definitions. The .c
file will include the .h file using #include "hash_table.h".
To avoid multiple inclusion problems, the .h file will start
with #pragma once3.
#pragma once /** * @file hash_table.h * @author write both your names here * @date 1 Sep 2019 * @brief Simple hash table that maps integer keys to string values. * * Here typically goes a more extensive explanation of what the header * defines. Doxygens tags are words preceeded by either a backslash @\ * or by an at symbol @@. * * @see http://wrigstad.com/ioopm19/assignments/assignment1.html */ /// @brief Create a new hash table /// @return A new empty hash table ioopm_hash_table_t *ioopm_hash_table_create(); /// @brief Delete a hash table and free its memory /// param ht a hash table to be deleted void ioopm_hash_table_destroy(ioopm_hash_table_t *ht); /// @brief add key => value entry in hash table ht /// @param ht hash table operated upon /// @param key key to insert /// @param value value to insert void ioopm_hash_table_insert(ioopm_hash_table_t *ht, int key, char *value); /// @brief lookup value for key in hash table ht /// @param ht hash table operated upon /// @param key key to lookup /// @return the value mapped to by key (FIXME: incomplete) void *ioopm_hash_table_lookup(ioopm_hash_table_t *ht, int key); /// @brief remove any mapping from key to a value /// @param ht hash table operated upon /// @param key key to remove /// @return the value mapped to by key (FIXME: incomplete) char *ioopm_hash_table_remove(ioopm_hash_table_t *ht, int key);
%23pragma%20once%0A%0A%2F%2A%2A%0A%20%2A%20%40file%20hash_table.h%0A%20%2A%20%40author%20write%20both%20your%20names%20here%0A%20%2A%20%40date%201%20Sep%202019%0A%20%2A%20%40brief%20Simple%20hash%20table%20that%20maps%20integer%20keys%20to%20string%20values.%0A%20%2A%0A%20%2A%20Here%20typically%20goes%20a%20more%20extensive%20explanation%20of%20what%20the%20header%0A%20%2A%20defines.%20Doxygens%20tags%20are%20words%20preceeded%20by%20either%20a%20backslash%20%40%5C%0A%20%2A%20or%20by%20an%20at%20symbol%20%40%40.%0A%20%2A%0A%20%2A%20%40see%20http%3A%2F%2Fwrigstad.com%2Fioopm19%2Fassignments%2Fassignment1.html%0A%20%2A%2F%0A%0A%2F%2F%2F%20%40brief%20Create%20a%20new%20hash%20table%0A%2F%2F%2F%20%40return%20A%20new%20empty%20hash%20table%0Aioopm_hash_table_t%20%2Aioopm_hash_table_create%28%29%3B%0A%0A%2F%2F%2F%20%40brief%20Delete%20a%20hash%20table%20and%20free%20its%20memory%0A%2F%2F%2F%20param%20ht%20a%20hash%20table%20to%20be%20deleted%0Avoid%20ioopm_hash_table_destroy%28ioopm_hash_table_t%20%2Aht%29%3B%0A%0A%2F%2F%2F%20%40brief%20add%20key%20%3D%3E%20value%20entry%20in%20hash%20table%20ht%0A%2F%2F%2F%20%40param%20ht%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20key%20key%20to%20insert%0A%2F%2F%2F%20%40param%20value%20value%20to%20insert%0Avoid%20ioopm_hash_table_insert%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%2C%20char%20%2Avalue%29%3B%0A%0A%2F%2F%2F%20%40brief%20lookup%20value%20for%20key%20in%20hash%20table%20ht%0A%2F%2F%2F%20%40param%20ht%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20key%20key%20to%20lookup%0A%2F%2F%2F%20%40return%20the%20value%20mapped%20to%20by%20key%20%28FIXME%3A%20incomplete%29%0Avoid%20%2Aioopm_hash_table_lookup%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%29%3B%0A%0A%2F%2F%2F%20%40brief%20remove%20any%20mapping%20from%20key%20to%20a%20value%0A%2F%2F%2F%20%40param%20ht%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20key%20key%20to%20remove%0A%2F%2F%2F%20%40return%20the%20value%20mapped%20to%20by%20key%20%28FIXME%3A%20incomplete%29%0Achar%20%2Aioopm_hash_table_remove%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%29%3B%0A
2.1 Recap: Hash Tables
A hash table data structure is a map from keys to values that uses the concept of hashing internally for performance. Many programming languages have support for maps, either as a library or built into the language itself. It is quite common that standard maps (aka dictionaries) are hash maps.
As the hashing concept is not important for our purposes here, we will not devote much time to how to write good hash functions. (Please put this on your backlog for after the course.)
Consider the following Python program that uses a map to keep track of quantities of merchandise in a warehouse:
# Starting a python interpreter $ python # Program as entered into an interactive prompt >>> # Create an empty map >>> quantities = {} >>> quantities['answers'] = 42 >>> quantities['perfumes'] = 4711 >>> quantities['primes_under_10'] = 4 >>> >>> # Look up the value for a specific key >>> quantities['answers'] 42 >>> >>> # Dump the contents of quantities (note the order) >>> quantities {'perfumes': 4711, 'primes_under_10': 4, 'answers': 42} >>> >>> # Get the keys of the maps >>> quantities.keys() ['perfumes', 'primes_under_10', 'answers'] >>> >>> # Delete the entry for a specific key >>> del quantities['answers'] >>> >>> # Print the contents of quantities >>> for k in quantities.keys(): ... print(k, "maps to", quantities[k]) ... perfumes maps to 4711 primes_under_10 maps to 4 # ctrl+d to exit back to command line $
%23%20Starting%20a%20python%20interpreter%0A%24%20python%0A%23%20Program%20as%20entered%20into%20an%20interactive%20prompt%0A%3E%3E%3E%20%23%20Create%20an%20empty%20map%0A%3E%3E%3E%20quantities%20%3D%20%7B%7D%0A%3E%3E%3E%20quantities%5B%27answers%27%5D%20%3D%2042%0A%3E%3E%3E%20quantities%5B%27perfumes%27%5D%20%3D%204711%0A%3E%3E%3E%20quantities%5B%27primes_under_10%27%5D%20%3D%204%0A%3E%3E%3E%0A%3E%3E%3E%20%23%20Look%20up%20the%20value%20for%20a%20specific%20key%0A%3E%3E%3E%20quantities%5B%27answers%27%5D%0A42%0A%3E%3E%3E%0A%3E%3E%3E%20%23%20Dump%20the%20contents%20of%20quantities%20%28note%20the%20order%29%0A%3E%3E%3E%20quantities%0A%7B%27perfumes%27%3A%204711%2C%20%27primes_under_10%27%3A%204%2C%20%27answers%27%3A%2042%7D%0A%3E%3E%3E%0A%3E%3E%3E%20%23%20Get%20the%20keys%20of%20the%20maps%0A%3E%3E%3E%20quantities.keys%28%29%0A%5B%27perfumes%27%2C%20%27primes_under_10%27%2C%20%27answers%27%5D%0A%3E%3E%3E%0A%3E%3E%3E%20%23%20Delete%20the%20entry%20for%20a%20specific%20key%0A%3E%3E%3E%20del%20quantities%5B%27answers%27%5D%0A%3E%3E%3E%0A%3E%3E%3E%20%23%20Print%20the%20contents%20of%20quantities%0A%3E%3E%3E%20for%20k%20in%20quantities.keys%28%29%3A%0A...%20%20%20%20%20print%28k%2C%20%22maps%20to%22%2C%20quantities%5Bk%5D%29%0A...%0Aperfumes%20maps%20to%204711%0Aprimes_under_10%20maps%20to%204%0A%23%20ctrl%2Bd%20to%20exit%20back%20to%20command%20line%0A%24%0A
We are going to build a hash table with the above features (and more) in a number of discrete steps. These steps are structured to tell a story where we incrementally arrive at a final program. There is no complete concise specification – you will have to work through this document bit by bit, because it discusses pros and cons, gets philosophical, etc. The point of this assignment is carrying it out, not having carried it out.
2.2 The Above Code in C
Below is a rough translation of the code above into C. Note that since C has no built-in dictionary, we must roll our own. Indeed, that is what this assignment is about. If you compile and run the program below, this is the output you will get:
== Dump the map == key: answers => value: 42 key: perfumes => value: 4711 key: primes_under_10 => value: 4 == Dump the keys == key: answers key: perfumes key: primes_under_10 == Delete the first entry == == Dump the map == key: perfumes => value: 4711 key: primes_under_10 => value: 4
Note that the program that you are going to read is quite awful for many reasons:
- The number of entries in the map is static – chosen at compile-time4).
- Even though we only use 3 entries, we pay for 10 with respect to memory consumption.
- We don’t yet use a hash, meaning that time complexity of searching and sorting is terrible (what is it?).
- There is no order of the entries (other than the order in which they were stored).
#include <stdio.h> #include <stdlib.h> /// Define a data structure for holding a key and a value struct entry { char *key; /// A string int value; }; /// make entry_t an alias for struct entry typedef struct entry entry_t; /// make map_t an alias for an array of 10 entry_t's typedef entry_t map_t[10]; /// The starting point of any C program int main(void) { /// Create an array or 10 elements, of which we are going to use 3 map_t map; int map_size = 3; /// Populate array just like in the Python example map[0] = (entry_t) { .key = "answers", .value = 42 }; map[1] = (entry_t) { .key = "perfumes", .value = 4711 }; map[2] = (entry_t) { .key = "primes_under_10", .value = 4 }; /// Print the contents of the map puts("== Dump the map =="); for (int i = 0; i < map_size; ++i) /// ++i means i = i + 1 { printf("key: %s => value: %d\n", map[i].key, map[i].value); } /// Print the keys puts("\n== Dump the keys =="); for (int i = 0; i < map_size; ++i) { printf("key: %s\n", map[i].key); } /// Delete the entry with index 0 puts("\n== Delete the first entry =="); for (int i = 1; i < map_size; ++i) { map[i-1] = map[i]; } map_size -= 1; /// means map_size = map_size - 1; /// Print the contents of the map again to see effect of change puts("\n== Dump the map =="); for (int i = 0; i < map_size; ++i) { printf("key: %s => value: %d\n", map[i].key, map[i].value); } return 0; }
%23include%20%3Cstdio.h%3E%0A%23include%20%3Cstdlib.h%3E%0A%0A%2F%2F%2F%20Define%20a%20data%20structure%20for%20holding%20a%20key%20and%20a%20value%0Astruct%20entry%0A%7B%0A%20%20char%20%2Akey%3B%20%2F%2F%2F%20A%20string%0A%20%20int%20value%3B%0A%7D%3B%0A%0A%2F%2F%2F%20make%20entry_t%20an%20alias%20for%20struct%20entry%0Atypedef%20struct%20entry%20entry_t%3B%0A%0A%2F%2F%2F%20make%20map_t%20an%20alias%20for%20an%20array%20of%2010%20entry_t%27s%0Atypedef%20entry_t%20map_t%5B10%5D%3B%0A%0A%2F%2F%2F%20The%20starting%20point%20of%20any%20C%20program%0Aint%20main%28void%29%0A%7B%0A%20%20%2F%2F%2F%20Create%20an%20array%20or%2010%20elements%2C%20of%20which%20we%20are%20going%20to%20use%203%0A%20%20map_t%20map%3B%0A%20%20int%20map_size%20%3D%203%3B%0A%0A%20%20%2F%2F%2F%20Populate%20array%20just%20like%20in%20the%20Python%20example%0A%20%20map%5B0%5D%20%3D%20%28entry_t%29%20%7B%20.key%20%3D%20%22answers%22%2C%20.value%20%3D%2042%20%7D%3B%0A%20%20map%5B1%5D%20%3D%20%28entry_t%29%20%7B%20.key%20%3D%20%22perfumes%22%2C%20.value%20%3D%204711%20%7D%3B%0A%20%20map%5B2%5D%20%3D%20%28entry_t%29%20%7B%20.key%20%3D%20%22primes_under_10%22%2C%20.value%20%3D%204%20%7D%3B%0A%0A%20%20%2F%2F%2F%20Print%20the%20contents%20of%20the%20map%0A%20%20puts%28%22%3D%3D%20Dump%20the%20map%20%3D%3D%22%29%3B%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20map_size%3B%20%2B%2Bi%29%20%2F%2F%2F%20%2B%2Bi%20means%20i%20%3D%20i%20%2B%201%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22key%3A%20%25s%20%3D%3E%20value%3A%20%25d%5Cn%22%2C%20map%5Bi%5D.key%2C%20map%5Bi%5D.value%29%3B%0A%20%20%20%20%7D%0A%0A%20%20%2F%2F%2F%20Print%20the%20keys%0A%20%20puts%28%22%5Cn%3D%3D%20Dump%20the%20keys%20%3D%3D%22%29%3B%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20map_size%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22key%3A%20%25s%5Cn%22%2C%20map%5Bi%5D.key%29%3B%0A%20%20%20%20%7D%0A%0A%20%20%2F%2F%2F%20Delete%20the%20entry%20with%20index%200%0A%20%20puts%28%22%5Cn%3D%3D%20Delete%20the%20first%20entry%20%3D%3D%22%29%3B%0A%20%20for%20%28int%20i%20%3D%201%3B%20i%20%3C%20map_size%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20map%5Bi-1%5D%20%3D%20map%5Bi%5D%3B%0A%20%20%20%20%7D%0A%20%20map_size%20-%3D%201%3B%20%2F%2F%2F%20means%20map_size%20%3D%20map_size%20-%201%3B%0A%0A%20%20%2F%2F%2F%20Print%20the%20contents%20of%20the%20map%20again%20to%20see%20effect%20of%20change%0A%20%20puts%28%22%5Cn%3D%3D%20Dump%20the%20map%20%3D%3D%22%29%3B%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%20map_size%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20printf%28%22key%3A%20%25s%20%3D%3E%20value%3A%20%25d%5Cn%22%2C%20map%5Bi%5D.key%2C%20map%5Bi%5D.value%29%3B%0A%20%20%20%20%7D%0A%0A%20%20return%200%3B%0A%7D%0A
2.3 How Hash Tables Work Internally
There is a wealth of information on the Internet on how hash tables work. This is a good opportunity to use your “search fu”5. Below, I only include a minimal description.
As we saw above, a hash table maps a key to a value. In pseudo
code syntax, if M is a map, M[k] looks up the value for k in
M, and M[k] = v updates M so that subsequent lookup of k
returns v. Keys can be pretty much anything (we will look more
deeply into that in a bit). Here is an example where keys are
integers and values are strings:
#+ATTR_HTML: :copy-button t # Pseudo code (Python) M = {} # creates a new hash table M[0] = "foo" M[1] = "bar" M[2] = "baz" print(M[1]) # prints bar M[1] = "barbara" print(M[1]) # prints barbara
%23%2BATTR_HTML%3A%20%3Acopy-button%20t%0A%23%20Pseudo%20code%20%28Python%29%0AM%20%3D%20%7B%7D%20%23%20creates%20a%20new%20hash%20table%0AM%5B0%5D%20%3D%20%22foo%22%0AM%5B1%5D%20%3D%20%22bar%22%0AM%5B2%5D%20%3D%20%22baz%22%0Aprint%28M%5B1%5D%29%20%23%20prints%20bar%0AM%5B1%5D%20%3D%20%22barbara%22%0Aprint%28M%5B1%5D%29%20%23%20prints%20barbara%0A
We want to be able to support efficient insertion, lookup, and deletion of entries in the map (and eventually a bunch of other things). If we restrict ourselves to integer-values keys (like in the above example, i.e., 0, 1, 2, …) then we could easily represent the hash table as an array of values:
// C code char *M[3]; // array with three strings M[0] = "foo"; M[1] = "bar"; M[2] = "baz"; puts(M[1]); // prints bar M[1] = "barbara"; puts(M[1]); // prints barbara
%2F%2F%20C%20code%0Achar%20%2AM%5B3%5D%3B%20%2F%2F%20array%20with%20three%20strings%0AM%5B0%5D%20%3D%20%22foo%22%3B%0AM%5B1%5D%20%3D%20%22bar%22%3B%0AM%5B2%5D%20%3D%20%22baz%22%3B%0Aputs%28M%5B1%5D%29%3B%20%2F%2F%20prints%20bar%0AM%5B1%5D%20%3D%20%22barbara%22%3B%0Aputs%28M%5B1%5D%29%3B%20%2F%2F%20prints%20barbara%0A
Good news about this representation:
- It is very simple to understand and program for (this is great)
- Insertion and lookup are fast, and \(O(1)\)6
Bad news about this representation:
- Only handles integer keys (we knew that, but worth repeating, lest we forget!)
- Only works if we know the largest key value when the map is created
- Does not work well for a sparse representation (e.g., few keys of widely different values)
- Does not support deletion
The lack of support for deletion is actually rooted in a bigger problem – there is no way to represent an absence of a value in the array! Imagine for example that our values are integers too – then the array can only store integers, and unless we e.g., reserve a special number, say -42, to denote no value, a key will always map to something (some integer value). Whatever value we pick, we restrict the usage of our map in programs. In our (bad) hypothetical examples, a program that wants to store -42 as a value will not work with our map.
There are several ways around this. For example, we could store a
separate, equally sized array of booleans (true or false)
where the value true at index i means “there is an entry for
key i”, and false that there is no entry. Another example is
to change the array to hold both the value and a boolean that
controls whether the value is in the set or not. (Etc.) There are
pros and cons with either approach.
However, this points to another underlying problem, which is the same as the bad fit for sparse representation mentioned above. For example, imagine that we in addition to the keys 0, 1 and 2 above also ended up using the key 1.000. This requires an array that reserves space for storage of at least 1.001 elements (not 1.000 – can you see why?) but only uses 4 (less than 1%) of the storage. (While that is wasteful, it may be OK for a large class of programs if the greatest key is relatively small (like 1.000), and we only have a small number of maps. However, for reasons we will see later, as we lift the restriction that keys are integers, this may not be the case.)
The last problem is related to the fact that the array representation only works if we know the largest key value when the map is created. This problem can be solved by creating a larger array when keys are used that do not fit in the current array. A similar scheme can be used to (possibly) move to a smaller array on deletion.
It is possible to solve all of the problems above by changing the representation (meaning how the abstract notion of a hash table mapping keys to values is stored in memory) so that:
- Each index in the array covers a dynamic number of keys7 instead of a single key; and
- Each value in the array is a sequence of (key,value) pairs so that each entry in the map is represented by a corresponding (key,value) pair (that we will call an entry).
In that representation, then index 0 in the array could (for
example) cover all keys in the set {0, 15, 31, 47, ...}. Looking
up key 47 of the map M means reading M[0] to access a sequence
of (key,value) pairs in which we can search for a pair whose key
is 47. If no such pair exists, then there is no entry for the key
47 in the map. Adding an entry for key 47 means adding a
(key,value) pair to a sequence, possibly updating or replacing a
previous entry. In typical hash table parlance, we talk about an
array of buckets, each with zero or more entries.
To avoid having to know the range of keys in use for a particular
program, we use modulo (C syntax: %). So, when inserting a key
k in a hash table with b buckets, the new entry goes into
bucket k modulo b (k % b).
Let us quickly analyse how this representation fares with respect to the good and bad news from above:
- Still very simple to understand and program for
- Insertion and lookup are still fast – the array let’s us jump to the right bucket in \(O(1)\) time, after which we can search in the bucket (typically \(O(n)\)8, where \(n\) is the number of entries in the bucket – typically a quite small number)
- It handles sparse representations well because it only stores data (in the form of pairs) for the entries in the map (as opposed to all possible entries as before).
- For the same reason, it trivially handles deletion and the absence of an entry for a key.
- The same strategy for growing and shrinking the array to not need a priori knowledge about the possible keys can be applied. Additionally, we can also adapt by changing the number of buckets (this involves moving entries across buckets).
Now, what remains is to lift the restriction that only integers can be used as keys. This is where the hash function comes in, from which the hash table derives its name. Glossing over many details that you will have to look up (but feel free to do that after the course), a hash function is a function that given a datum returns an integer – a hash code. The hash code is usually some kind of semi-unique “fingerprint” of a datum, so that the hash code for similar data still have different hash codes. We use the hash code internally to select the bucket for a key (in \(O(1)\) time).
Development of hash functions is super interesting, quite subtle and out of scope for this course.
For concreteness, here is a very basic hash function for hashing a string which produces an integer from a string by calculating the sum of all ASCII values of all the characters.
unsigned long string_sum_hash(const char *str) { unsigned long result = 0; do { result += *str; /// *str is the ASCII value of } while (*++str != '\0'); return result; }
unsigned%20long%20string_sum_hash%28const%20char%20%2Astr%29%0A%7B%0A%20%20unsigned%20long%20result%20%3D%200%3B%0A%20%20do%0A%20%20%20%20%7B%0A%20%20%20%20%20%20result%20%2B%3D%20%2Astr%3B%20%2F%2F%2F%20%2Astr%20is%20the%20ASCII%20value%20of%0A%20%20%20%20%7D%0A%20%20while%20%28%2A%2B%2Bstr%20%21%3D%20%27%5C0%27%29%3B%0A%20%20return%20result%3B%0A%7D%0A
(Later in this document, we will see at least one better hash function implementation.)
Using non-integer keys in a hash table thus requires the existence of a function that for a given value in the key domain returns an integer (and always the same value for the same key). Typically, we hide this to the users, except for the fact that we ask them to provide such a function that we subsequently use internally.
For now, we will dodge and consider only lists that store integers. This seems like a good simplification, and innocuous too – we know how to undo it later by adding a hash function.
2.4 Hash Table Representation
From our above discussion, our hash table will be represented as an array of buckets, and each bucket will hold a sequence of entries. In addition to that, we will hold some auxiliary data like the size of the array, etc. The auxiliary data will grow as we make our hash table increasingly fancy. The sequence of entries will not be another array, but a linked structure, implemented by letting each entry know the location in memory of the next entry (using a pointer). Using an array is of course possible, and comes with all of the pros and cons from above9. For the rest of this assignment, we will stick with a linked structure.
Following the SIMPLE methodology, we are going to dodge and simplify the specification. Our first hash table implementation will only support integer keys and string values, and only support a fixed number of buckets (17). This is enough to write some useful tests, to weed out early bugs. Note that while the number of buckets is fixed, each bucket can have an “unbounded” number of entries.
Always make a note of dodges and cheats so that you can revisit
them and “fix them” later. Without such a log, it is easy to
forget to e.g. undo a simplification later. You can mark this in
your code e.g., /// DODGE: ..., /// CHEAT: ..., etc. like the
/// FIXME: ..., and /// TODO: ... that is used in code on
this page.
Tip: the fixmee Emacs package allows you to quickly jump
between FIXME, TODO etc. tags in code, or list all such tags
and navigate to them. If you use the course’s Emacs settings, it
also understands CHEAT and DODGE.
Below are the initial definitions of the structs we will be using.
We will be revising these several times as we go. Remember that
typedef creates a type alias. Also note that we prefix the
hash table type with ioopm_. This will be a naming convention
for all public types on this course, meaning, you will use this
naming scheme for things in your code! The entry_t type is only
used internally by the hash table, so it will not get a public
name.
typedef struct entry entry_t; typedef struct hash_table ioopm_hash_table_t; struct entry { int key; // holds the key char *value; // holds the value entry_t *next; // points to the next entry (possibly NULL) }; struct hash_table { entry_t *buckets[17]; };
typedef%20struct%20entry%20entry_t%3B%0Atypedef%20struct%20hash_table%20ioopm_hash_table_t%3B%0A%0Astruct%20entry%0A%7B%0A%20%20int%20key%3B%20%20%20%20%20%20%20%2F%2F%20holds%20the%20key%0A%20%20char%20%2Avalue%3B%20%20%20%2F%2F%20holds%20the%20value%0A%20%20entry_t%20%2Anext%3B%20%2F%2F%20points%20to%20the%20next%20entry%20%28possibly%20NULL%29%0A%7D%3B%0A%0Astruct%20hash_table%0A%7B%0A%20%20entry_t%20%2Abuckets%5B17%5D%3B%0A%7D%3B%0A
The figure 1 and Figure 2 show the hash table newly
initialised and with three entries respectively. ADDR means a
non-NULL pointer pointing to the datum on the right.

Figure 1: Newly initialised hash table.
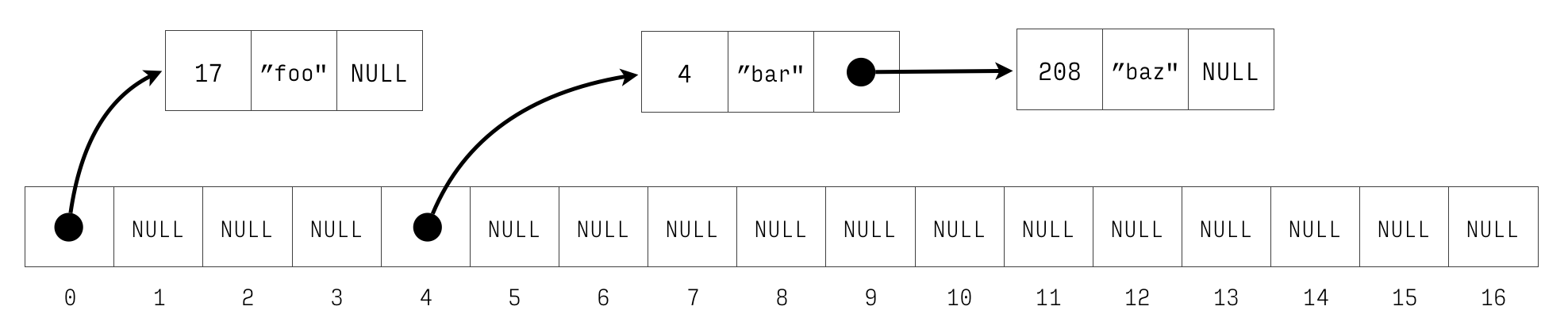
Figure 2: Hash table with keys 4 \(\mapsto\) bar, 17 \(\mapsto\) foo, and 208 \(\mapsto\) “baz”.
2.4.1 Placement of struct hash_table and struct entry etc.
The placement of structs is important. We want data structures to be opaque, meaning it should not be possible for a client to know how they are implemented. This preserves maximal freedom for us to change the implementation as we continue to improve our code, and also helps us protect the invariants of the data structure.
Structs such as struct hash_table and struct entry are
internal implementation details and as such should be in the
hash_table.c file, not the .h file. Structs like option (if
you implemented it) needs to go into the .h file, as a user
must be able to look inside the struct to search values.
Placement inside the .c file has impact on the testing instead
– how will tests be able to access the structs?
Place the structs in the right places, and know your motivation for what you chose.
This is a good time to start thinking about Achievement A3.
2.4.2 Using Debuggers
Once you are done with this bit, you know enough gdb to debug
your own problems in the subsequent steps. If and when you have
a tricky situation to debug, after you solved it, you should
definitely use that to demonstrate Achievement R52.
Debuggers like gdb and lldb are great tools for understanding
programs and fixing bugs. You need to familiarise yourself with a
debugger (say, gdb) as soon as possible so that you are never
afraid to use it later. You should learn the basics before
hitting a bug, so you don’t need to struggle both with learning
how to navigate gdb and using it to find the bug at the same
time.
So, in that spirit, let us spend a few minutes in gdb to explore
the hash table representation of above. Below is a program that
(on the stack for simplicity) creates a hash table. Compile this
program like so: gcc -pedantic -Wall -g gdb-test.c (read about
what the flags mean here). This produces a file a.out that you
can run through gdb. Note that compiling this program will
produce a warning that you’re declaring a variable ht that you
are not using. We can live with this warning for now – we are
going to use ht through the debugger.
#include <stdlib.h> /// the types from above typedef struct entry entry_t; typedef struct hash_table ioopm_hash_table_t; struct entry { int key; // holds the key char *value; // holds the value entry_t *next; // points to the next entry (possibly NULL) }; struct hash_table { entry_t *buckets[17]; }; int main(int argc, char *argv[]) { entry_t a = { .key = 1, .value = argv[1] }; entry_t b = { .key = 2, .value = argv[2], .next = &a }; entry_t c = { .key = 3, .value = argv[3], .next = &b }; entry_t d = { .key = 4, .value = argv[4] }; entry_t e = { .key = 5, .value = argv[5] }; entry_t f = { .key = 6, .value = argv[6], .next = &e }; ioopm_hash_table_t ht = { .buckets = { 0 } }; ht.buckets[3] = &c; ht.buckets[8] = &d; ht.buckets[15] = &f; return 0; }
%23include%20%3Cstdlib.h%3E%0A%0A%2F%2F%2F%20the%20types%20from%20above%0Atypedef%20struct%20entry%20entry_t%3B%0Atypedef%20struct%20hash_table%20ioopm_hash_table_t%3B%0A%0Astruct%20entry%0A%7B%0A%20%20int%20key%3B%20%20%20%20%20%20%20%2F%2F%20holds%20the%20key%0A%20%20char%20%2Avalue%3B%20%20%20%2F%2F%20holds%20the%20value%0A%20%20entry_t%20%2Anext%3B%20%2F%2F%20points%20to%20the%20next%20entry%20%28possibly%20NULL%29%0A%7D%3B%0A%0Astruct%20hash_table%0A%7B%0A%20%20entry_t%20%2Abuckets%5B17%5D%3B%0A%7D%3B%0A%0Aint%20main%28int%20argc%2C%20char%20%2Aargv%5B%5D%29%0A%7B%0A%20%20entry_t%20a%20%3D%20%7B%20.key%20%3D%201%2C%20.value%20%3D%20argv%5B1%5D%20%7D%3B%0A%20%20entry_t%20b%20%3D%20%7B%20.key%20%3D%202%2C%20.value%20%3D%20argv%5B2%5D%2C%20.next%20%3D%20%26a%20%7D%3B%0A%20%20entry_t%20c%20%3D%20%7B%20.key%20%3D%203%2C%20.value%20%3D%20argv%5B3%5D%2C%20.next%20%3D%20%26b%20%7D%3B%0A%20%20entry_t%20d%20%3D%20%7B%20.key%20%3D%204%2C%20.value%20%3D%20argv%5B4%5D%20%7D%3B%0A%20%20entry_t%20e%20%3D%20%7B%20.key%20%3D%205%2C%20.value%20%3D%20argv%5B5%5D%20%7D%3B%0A%20%20entry_t%20f%20%3D%20%7B%20.key%20%3D%206%2C%20.value%20%3D%20argv%5B6%5D%2C%20.next%20%3D%20%26e%20%7D%3B%0A%20%20ioopm_hash_table_t%20ht%20%3D%20%7B%20.buckets%20%3D%20%7B%200%20%7D%20%7D%3B%0A%20%20ht.buckets%5B3%5D%20%3D%20%26c%3B%0A%20%20ht.buckets%5B8%5D%20%3D%20%26d%3B%0A%20%20ht.buckets%5B15%5D%20%3D%20%26f%3B%0A%0A%20%20return%200%3B%0A%7D%0A
We are now going to run this program in gdb:
gdb ./a.outStartgdbwitha.outbeing the program we are running.r one two three four five sixRun the program. This will finish nicely and print something like “[Inferior 1 (process 17723) exited normally]”. The “one … six” are the command-line arguments to the program meaningargv[1]will be “one”, etc.b mainSet a breakpoint at the start of themain()function causing the program to stop and return control togdbwhen we hit this point in the program.r one two three four five sixStart the program again. This time, the program will be paused immediately at the start.listPrint the source code of the current line and surrounding lines.n(repeat this until you reach line 27, aka line 7 inmain()) Steps the program further, one step at the time. You can see what line is being executed.p aPrint the contents of theavariable.n(repeat until you reach line 30, aka line 10 inmain())p ht.buckets[3]->next->next->keyGo to the fourth element inbucketsinht, and follow thenextpointer, twice, and print the key in the corresponding entry.cGo back to executing the program until finish, or we hit another breakpoint. This will finish the program again.
In addition to n (next), there is also s (step), which steps
into an operation. For example, if the debugger is positioned on
the line x = foo(), n will run foo() and store the returned
value in x, whereas s will start foo() and immediately break
at its first line, allowing you to step through foo() as well.
The gdb (and lldb) debuggers are great! For example if you
run your program through gdb and you experience a crash, gdb
will allow you to print a backtrace (using the bt command)
that shows you the path in the program to the place where the
error occurred. Here is an example of what this might look like in
gdb.
Reading symbols from a.out...done.
(gdb) r
Starting program: /home/stw/t/ioopm/2018/hash/a.out
a.out: driver.c:74: main: Assertion `ioopm_hash_table_has_key(h, nev, str_equality) == true' failed.
Program received signal SIGABRT, Aborted.
__GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
51 ../sysdeps/unix/sysv/linux/raise.c: No such file or directory.
(gdb) bt
#0 __GI_raise (sig=sig@entry=6) at ../sysdeps/unix/sysv/linux/raise.c:51
#1 0x00007ffff7a2df5d in __GI_abort () at abort.c:90
#2 0x00007ffff7a23f17 in __assert_fail_base (fmt=<optimized out>,
assertion=assertion@entry=0x555555555f40 "ioopm_hash_table_has_key(h, nev, str_equality) == true", file=file@entry=0x555555555e89 "driver.c", line=line@entry=74,
function=function@entry=0x555555556076 <__PRETTY_FUNCTION__.3061> "main") at assert.c:92
#3 0x00007ffff7a23fc2 in __GI___assert_fail (
assertion=0x555555555f40 "ioopm_hash_table_has_key(h, nev, str_equality) == true",
file=0x555555555e89 "driver.c", line=74,
function=0x555555556076 <__PRETTY_FUNCTION__.3061> "main") at assert.c:101
#4 0x0000555555555739 in main (argc=1, argv=0x7fffffffda58) at driver.c:74
This is the very very bare minimum of gdb that you need to know,
but you should know that there is lots more. You can even travel
backwards in time and step your program backwards.
One trick that has worked very well for me is to
“secretly” run programs through gdb so that if they crash,
they produce a backtrace: gdb -batch -ex "run" -ex "bt" --args
./a.out one two three four five six.
(For lldb, you can use this which is almost the same: lldb -b -o "run" -k "bt" -k "quit".)
Because this is a bit dull to write, I have an alias set up for
this in my .bashrc file (actually .zshrc because I run zsh):
alias bt='gdb -batch -ex "run" -ex "bt" --args'. This allows me
to write bt ./a.out one two three four five six. and get a nice
backtrace10 in the event of a segfault.
2.5 A Fork in The Road
You are standing on a dirt road. A little further up ahead, there is a fork, that splits the road in two directions: one leading left and one leading right. To go left, scroll down to Section 3. To go right, scroll down to Section 4. (But not until you have read the next two paragraphs)
We are finally about to start implementing the hash table. These instructions offer you two ways forward. One is the test-driven approach in which we start by first defining a success criteria for the next step, write that down in the form of a test, and then proceed to write the actual implementation, using the test to check when we are done. The other approach is the classical approach, in which we first write the implementation, and then write the tests to verify that the implementation is correct.
Regardless of the approach, we will end up with an implementation of some feature and at least one test for the implementation. The amount of work is the same. Pick whatever approach you like, as long as you try both – seriously – during the course.
(Now you’ve read the two paragraphs! Go left or right?)
3 Left: Test-Driven Approach
Test-driven development is based on the idea that tests should be written before the code they are testing, and thus serve as a definition of correctness for that code. By starting with the tests, we are forced to decide what are valid behaviours and what is the semantics of the function before we start coding it up, which is very nice.
The test-driven approach will thus work very much like the classical approach, but change in two important ways:
- For each step, we start by defining the success criteria of that step, expressed as a test – and equate finishing the step with the passing of the test.
- Because we are test-driven, the order in which we implement things might sometimes change because in order to test something, we usually need ways of inspecting it, or at least getting some data for it.
A possible order of basic features for a hash table is this:
- Create a new, empty hash table
- Destroy a hash table and free its used memory
- Lookup the value for a given key
- Insert a new key–value mapping in a hash table
- Remove a key–value mapping from a hash table
3.1 Features 1 & 2: Create and Destroy
Start by writing a stub for the functions under test so we can compile and run a (failing) test:
ioopm_hash_table_t *ioopm_hash_table_create() void ioopm_hash_table_destroy(ioopm_hash_table_t *ht)
ioopm_hash_table_t%20%2Aioopm_hash_table_create%28%29%0Avoid%20ioopm_hash_table_destroy%28ioopm_hash_table_t%20%2Aht%29%0A
Note that for some functions, there are some design decisions left to you which may change the signature.
Creation and deletion could possibly be a single step, but we separate them here to simplify the discussion. Implementing lookup before insertion might seem strange, but it is totally fine even though our initial tests for lookup are going to be very boring because it will only be able to interact with empty hash tables.
Before we begin, read the page on the CUnit test framework which is the mandated framework to use for unit testing on this course. Those instructions will give you a minimal unit test file that you can populate with tests for the hash table.
How do we test creation and destruction of a data structure?
Future tests will test the correctness of the implementation of
the data representation, but for now creation and destruction can
be tested together. Our test will create an ioopm_hash_table_t,
destroy same hash table, and we will run this test under
valgrind, to make sure that we both allocate and free
appropriately.
Here is what such a test could look like:
void test_create_destroy() { ioopm_hash_table_t *ht = ioopm_hash_table_create(); CU_ASSERT_PTR_NULL(ht); ioopm_hash_table_destroy(ht); }
void%20test_create_destroy%28%29%0A%7B%0A%20%20%20ioopm_hash_table_t%20%2Aht%20%3D%20ioopm_hash_table_create%28%29%3B%0A%20%20%20CU_ASSERT_PTR_NULL%28ht%29%3B%0A%20%20%20ioopm_hash_table_destroy%28ht%29%3B%0A%7D%0A
OK, so from a external testing perspective, we now know that the
success criteria for the implementation of
ioopm_hash_table_create() and ioopm_hash_table_destroy() is
that whatever data was created by the first is removed by the
second. Note that as tests go, this is no super great – if we
leave the definition of both functions under test empty, the tests
will pass. However, as our feature sets grow, so will our tests,
which will take care of this.
Now that we have a test for both functions, now is the time to start thinking about how to implement them. Look at the discussion in Step 0 and Step 4 from the “Classical Approach”. Then return here.
Ideally, after writing the test, you want to execute it and see
that it fails. This is in line with the SIMPLE approach (always
have a running program), and requires that we start the actual
implementation of the features by defining stubs for the functions
under test, e.g., a one-line ioopm_hash_table_create() function
that returns NULL etc. This will cause our test to fail which is
good because our goal is to make it pass! Moreover, if we can get
the test to compile, run and fail before implementing the
feature we are testing, we do not need to fix bugs both in the
test and the feature under test at the same time!
3.2 Feature 3: Looking up Values
Start by writing a stub for the function under test so we can compile and run a (failing) test:
char *ioopm_hash_table_lookup(ioopm_hash_table_t *ht, int key)
char%20%2Aioopm_hash_table_lookup%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%29%0A
Note that there are some design decisions left to you which may change the signature.
Next step is to implement support for looking up values in a hash table. This is going to be a very useful feature, not in the least for testing many other features like insertion and removal. From a testing perspective, we could try to manually construct a hash table and use it for looking up, but this is brittle and will haunt us if we ever need to change the internal representation. Instead, for now, let us as a test simply verify that a newly created hash table is completely empty.
We can draw on our knowledge of the internal representation in our choice of lookup operations. If we know that the number of bucket lists is 17, then we can easily carve up a test where we are sure to hit all the buckets. However, tempting as it may be to draw on such internal information, constants such as the number of buckets may change in the future. Unless the test uses the same constant as the hash table11, it may be better to treat the object under test as a black box. Nevertheless, here is an initial test based on trying to hit all buckets, do one wrap-around (17 should wrap to bucket 0), and dealing with negative numbers. (Are they possible? Should they be possible? How should they be handled?)
void test_lookup() { ioopm_hash_table_t *ht = ioopm_hash_table_create(); for (int i = 0; i < 18; ++i) /// 18 is a bit magical { CU_ASSERT_PTR_NULL(ioopm_hash_table_lookup(ht, i)); } CU_ASSERT_PTR_NULL(ioopm_hash_table_lookup(ht, -1)); ioopm_hash_table_destroy(ht); }
void%20test_lookup%28%29%0A%7B%0A%20%20%20ioopm_hash_table_t%20%2Aht%20%3D%20ioopm_hash_table_create%28%29%3B%0A%20%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%2018%3B%20%2B%2Bi%29%20%2F%2F%2F%2018%20is%20a%20bit%20magical%0A%20%20%20%20%20%7B%0A%20%20%20%20%20%20%20CU_ASSERT_PTR_NULL%28ioopm_hash_table_lookup%28ht%2C%20i%29%29%3B%0A%20%20%20%20%20%7D%0A%20%20%20CU_ASSERT_PTR_NULL%28ioopm_hash_table_lookup%28ht%2C%20-1%29%29%3B%0A%20%20%20ioopm_hash_table_destroy%28ht%29%3B%0A%7D%0A
The code snippet above exemplifies a great case for using a comment. The number 18 is seemingly “magical” – it is likely not obvious to most casual readers of this code why it was chosen. A comment is a good way to explain why it was chosen, so that a future coder will know to change it if the number of buckets change (at least if they stumble across the code and read the comment).
Now that we have an initial (albeit fairly uninteresting) test for look-ups, now is the time to start thinking about how to implement the lookup function. Look at the discussion in Step 2 from the “Classical Approach”. Then return here.
3.3 Feature 4: Inserting Values
Start by writing a stub for the function under test so we can compile and run a (failing) test:
void ioopm_hash_table_insert(ioopm_hash_table_t *ht, int key, char *value)
void%20ioopm_hash_table_insert%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%2C%20char%20%2Avalue%29%0A
Note that there are some design decisions left to you which may change the signature.
Dijkstra’s classical quote about testing – that testing can only prove the presence of errors, not the absence – stems from the fact that we, in the general case, cannot (be sure to) test all possible cases. Thus, if all tests pass, we cannot claim correctness, just that “all tests pass”.
Testing is to a large extent about being clever and economic about what tests to execute. If we are going to test a linked list, for example, what length should we test? 1? 1.000? 1.000.000? Etc. The key insight is to test the cases that represent particular states in the object under test. For a linked list, for example, testing against the empty list is important, as is a list with a single element, and a list with “a couple of” elements. These typically represent the important states of a list. For example, in a list with a single element, there is no middle element, so we need one with “a couple of” elements to cover that case.
For inserting values, there are going to be two, possibly three important basic cases to test for:
- Testing with a fresh key that is not already in use
- Testing with a key that is already in use
- Testing with an invalid key (if at all possible)
When we test these cases, we test them in isolation. If we tested all together, it will be harder for us to pinpoint the location of errors. For example, maybe a bug in inserting with an existing key leaves the hash table in a corrupted state that triggers an error on the next lookup. When that error happens, we would like to be able to deduce that the error is in the implementation of insert with an existing key.
Thus, to reduce the search space for the root cause of a bug, we
test the cases 1-3 separately. After this, it makes sense to test
the interaction between the cases, e.g. testing the sequences
1;1, 1;2, 2;2, etc. And possibly longer sequences. Thus, if
the tests for 1, 2 and 1;1 passes, but the test 1;2 fails, we
know that it is the interaction between 1 and 2, and that the bug
is likely in 2 given that 1;1 worked fine.
In a nut shell, test design is about finding a small enough number of tests that they can be executed in short enough time for us to be able to run them constantly, yet large enough to cover all the important states and state transitions of the object under test, and structured in such a way that for each failing test, the search space for the root cause of the bug is as small as possible.
We can use lookup to observe the changes after insert. For example, a minimal test for case 1 above would be:
- Create a new empty hash table \(h\)
- Verify that key \(k\) is not in \(h\) using lookup
- Insert a value \(v\) with key \(k\) in \(h\)
- Use lookup to verify that \(k\) maps to \(v\)
- Destroy \(h\)
Go ahead and code up that test in this function skeleton:
void test_lookup1() { ... }
void%20test_lookup1%28%29%0A%7B%0A%20%20...%0A%7D%0A
Complement this test function with others following the logic of above. When you are done, you have defined the success criteria for the insert function. Time to write it! Look at the discussion in Step 3 from the “Classical Approach”. Then return here.
3.4 Feature 5: Removing Values
Start by writing a stub for the function under test so we can compile and run a (failing) test:
void ioopm_hash_table_remove(ioopm_hash_table_t *ht, int key)
void%20ioopm_hash_table_remove%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%29%0A
Note that there are some design decisions left to you which may change the signature.
For this test, you are on your own! You know what to do – it will be very similar to the tests above. When you are done, implement support for removal following Step 4 from the “Classical Approach”. Then jump to Step 5: Refactoring and apply that while using the tests to make sure that your refactorings do not accidentally break stuff!
3.5 Moving On…
Now you know basic test-driven development! Granted, details are still a bit sketchy, but we are only on Assignment 1. This diagram shows the process of test-driven development quite clearly, especially after having completed it once.
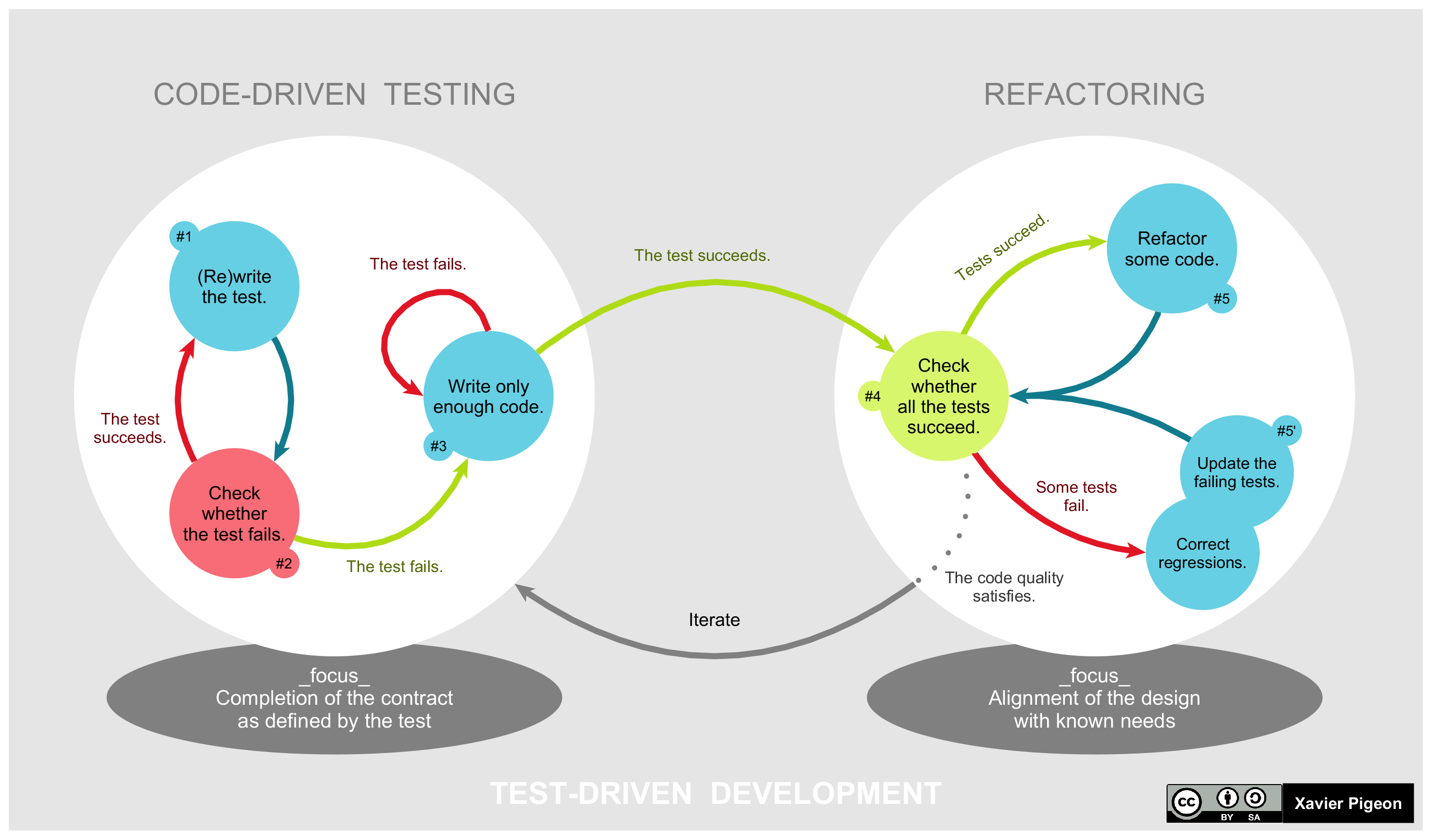
Figure 3: The life-cycle of test-driven design (from Wikipedia)
Continue using the test-driven approach now, by jumping to Ticket #2: Utility Functions which is not written especially for a test-driven approach. That should not be needed now that you know what you are doing.
4 Right: Classical Approach
In a top-down way (starting from the public functions that a user of the hash table will see), we will start our implementation by designing, coding and testing the following features:
- Create a new, empty hash table
- Insert a new key–value mapping in a hash table
- Lookup the value for a given key
- Remove a key–value mapping from a hash table
- Delete a hash table and free its used memory
This order makes sense from a testing perspective: the first feature is a prerequisite of the following three, the second is a prerequisite of the following two (at least for interesting cases), and the third lets us see the effects of the 2nd and 4th. (In all honesty, delete should probably be made the second – but we punt on that now, because it is slightly involved.)
If we wanted to proceed in another order, we would have had to create and populate a list by hand to be able to write a reasonable test. (There is nothing wrong with that. For a lot of things in programming, there is no inherent right or wrong – this may vary from case to case and also be strongly influenced by what you perceive as natural or intuitive.)
Words of Advice Before You Start
Compile often. Initially, perhaps once for every line of code you edit. It is better to capture errors immediately and to fix small errors all the time rather than face a mountain of errors to fix later. Along the same lines, try to have a working program at all times – so that you can run it and see where it crashes.
Remember that the C compiler reads files top-down. Thus, if
function f appears before function g in the source, C does not
yet know g when you want to call it. This is solved by adding
function prototypes for private functions topside of the .c
file, and by including the corresponding .h file.
When you are compiling a program that does not have a main()
function, you need to use separate compilation by adding the
-c flag when you compile. This produces object code (e.g.
file.o) rather than an executable, and thus does not need any
main function.
When you read the output from the compiler, don’t read it from the end, but scroll up and read from the start. It is very likely, especially when you are a beginner C programmer, that later errors are caused by earlier errors that confused the C compiler. That means the later errors may be addressed by fixing the earlier errors. If you compile in Emacs rather than in the terminal, Emacs will interpret the compilers output so that if you click on an error (or move the cursor over it and hit enter), it will take you to the right place in the code immediately.
If you come across a function that you don’t know, try man
that_function on the command line on Linux or macOS. Usually you
will get lots of very useful information. Try e.g., man strncpy
now. You can also do man man to get information about how the
man pages system works.
4.1 Step 0: Creating an Empty Hash Table
Recapping the structure of the hash table from above, a hash table (for now) is simply an array of (pointers) to entries. Since we know the number of buckets statically –it is hard coded as 17 – and do not allow the number of buckets to change, we do not need to store any meta data.
We are now ready to code up the function to create the hash table.
Note the naming convention that we follow. Each public function’s
name starts with ioopm, followed by some symbol that groups the
functions in a clear way, followed by some symbol, usually a verb,
that explains what the function does. Thus, we can see directly
that the function ioopm_hash_table_create() belongs to the code
written for the ioopm course, and that it concerns – creates –
hash tables.
We noted before that, except for the array of buckets, we only store data for entries in the hash table. As the hash table is empty, all we need is an empty array.
IMPORTANT C CAVEAT
When we allocate memory in C using malloc(), C will return a
pointer to memory whose contents are unknown. They will contain
whatever bytes that happened to be in that part of memory. Thus,
after using malloc() we need to explicitly initialise the
newly allocated data.
The steps to creating a new hash table is thus:
- Allocate memory to hold 17 buckets where each bucket is
represented as a pointer to an
entry_t. - Iterate over the buckets and initialise them to
NULL. - Return a pointer to the allocated and initialised memory.
Here is a first stab of the function:
ioopm_hash_table_t *ioopm_hash_table_create() { /// Allocate space for a ioopm_hash_table_t = 17 pointers to entry_t's ioopm_hash_table_t *result = malloc(sizeof(ioopm_hash_table_t)); /// Initialise the entry_t pointers to NULL for (int i = 0; i < 17; ++i) { result->buckets[i] = NULL; } return result; }
ioopm_hash_table_t%20%2Aioopm_hash_table_create%28%29%0A%7B%0A%20%20%2F%2F%2F%20Allocate%20space%20for%20a%20ioopm_hash_table_t%20%3D%2017%20pointers%20to%20entry_t%27s%0A%20%20ioopm_hash_table_t%20%2Aresult%20%3D%20malloc%28sizeof%28ioopm_hash_table_t%29%29%3B%0A%20%20%2F%2F%2F%20Initialise%20the%20entry_t%20pointers%20to%20NULL%0A%20%20for%20%28int%20i%20%3D%200%3B%20i%20%3C%2017%3B%20%2B%2Bi%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20result-%3Ebuckets%5Bi%5D%20%3D%20NULL%3B%0A%20%20%20%20%7D%0A%20%20return%20result%3B%0A%7D%0A
There is a companion function to malloc(), called calloc(),
that initialised allocated memory by setting all its bits to zero.
The calloc() function is intented to be used to allocate arrays,
but can always be used in place of malloc(). To avoid nasty bugs
due to use of uninitialised memory, always use calloc() and
never use malloc().
Using calloc() we can rewrite the create function thus:
ioopm_hash_table_t *ioopm_hash_table_create() { /// Allocate space for a ioopm_hash_table_t = 17 pointers to /// entry_t's, which will be set to NULL ioopm_hash_table_t *result = calloc(1, sizeof(ioopm_hash_table_t)); return result; }
ioopm_hash_table_t%20%2Aioopm_hash_table_create%28%29%0A%7B%0A%20%20%2F%2F%2F%20Allocate%20space%20for%20a%20ioopm_hash_table_t%20%3D%2017%20pointers%20to%0A%20%20%2F%2F%2F%20entry_t%27s%2C%20which%20will%20be%20set%20to%20NULL%0A%20%20ioopm_hash_table_t%20%2Aresult%20%3D%20calloc%281%2C%20sizeof%28ioopm_hash_table_t%29%29%3B%0A%20%20return%20result%3B%0A%7D%0A
Note that with calloc() we need to specify how many hash
tables we want to allocate. Unless we are allocating an array of
values, this number is likely going to be 1 (like now).
4.1.1 Finish This Step
We already have a working ioopm_hash_table_create(), so we are
almost done. To finish this step, you should:
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile. Once your makefile has grown a bit (and there are more files and more tests), you should use it to demonstrate Achievement U57.
- Check your code into the approprate GitHub repos. Tag your
commit with
assignment1_step0following the instructions in the previous link.
4.2 Step 1: Inserting a new (key, value) entry
This is a good time to start thinking about Achievement A1.
A first algorithm for inserting a new (key, value) entry into
our hash map could involve the following steps:
1. Find the right bucket for key 2. Insert the (key, value) into the bucket
This however fails to address the case when there is already
another entry, (key, other_value), in the hash map. A revised
algorithm could thus be:
1. (as before) 2. Search the entries in the bucket for an entry with key key 2.1 If found: replace the value of that entry with value 2.2 Otherwise: insert the (key, value) into the bucket
This seems like a working algorithm (right?), so let’s go ahead and code it up. Here:
void ioopm_hash_table_insert(ioopm_hash_table_t *ht, int key, char *value) { /// Calculate the bucket for this entry int bucket = key % 17; /// Get a pointer to the first entry in the bucket entry_t *first_entry = ht->buckets[bucket]; entry_t *cursor = first_entry; while (cursor != NULL) { if (cursor->key == key) { cursor->value = value; return; /// Ends the whole function! } cursor = cursor->next; /// Step forward to the next entry, and repeat loop } /// We only reach this point if we managed to search through the whole /// bucket without finding an entry with key as key /// Create an object for the new entry entry_t *new_entry = calloc(1, sizeof(entry_t)); /// Set the key and value fields to the key and value new_entry->key = key; new_entry->value = value /// Make the first entry the next entry of the new entry new_entry->next = first_entry; /// Make the new entry the first entry in the bucket ht->buckets[bucket] = new_entry; }
void%20ioopm_hash_table_insert%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%2C%20char%20%2Avalue%29%0A%7B%0A%20%20%2F%2F%2F%20Calculate%20the%20bucket%20for%20this%20entry%0A%20%20int%20bucket%20%3D%20key%20%25%2017%3B%0A%20%20%2F%2F%2F%20Get%20a%20pointer%20to%20the%20first%20entry%20in%20the%20bucket%0A%20%20entry_t%20%2Afirst_entry%20%3D%20ht-%3Ebuckets%5Bbucket%5D%3B%0A%0A%20%20entry_t%20%2Acursor%20%3D%20first_entry%3B%0A%20%20while%20%28cursor%20%21%3D%20NULL%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20if%20%28cursor-%3Ekey%20%3D%3D%20key%29%0A%20%20%20%20%20%20%20%20%7B%0A%20%20%20%20%20%20%20%20%20%20cursor-%3Evalue%20%3D%20value%3B%0A%20%20%20%20%20%20%20%20%20%20return%3B%20%2F%2F%2F%20Ends%20the%20whole%20function%21%0A%20%20%20%20%20%20%20%20%7D%0A%0A%20%20%20%20%20%20cursor%20%3D%20cursor-%3Enext%3B%20%2F%2F%2F%20Step%20forward%20to%20the%20next%20entry%2C%20and%20repeat%20loop%0A%20%20%20%20%7D%0A%0A%20%20%2F%2F%2F%20We%20only%20reach%20this%20point%20if%20we%20managed%20to%20search%20through%20the%20whole%0A%20%20%2F%2F%2F%20bucket%20without%20finding%20an%20entry%20with%20key%20as%20key%0A%0A%20%20%2F%2F%2F%20Create%20an%20object%20for%20the%20new%20entry%0A%20%20entry_t%20%2Anew_entry%20%3D%20calloc%281%2C%20sizeof%28entry_t%29%29%3B%0A%20%20%2F%2F%2F%20Set%20the%20key%20and%20value%20fields%20to%20the%20key%20and%20value%0A%20%20new_entry-%3Ekey%20%3D%20key%3B%0A%20%20new_entry-%3Evalue%20%3D%20value%0A%20%20%2F%2F%2F%20Make%20the%20first%20entry%20the%20next%20entry%20of%20the%20new%20entry%0A%20%20new_entry-%3Enext%20%3D%20first_entry%3B%0A%20%20%2F%2F%2F%20Make%20the%20new%20entry%20the%20first%20entry%20in%20the%20bucket%0A%20%20ht-%3Ebuckets%5Bbucket%5D%20%3D%20new_entry%3B%0A%7D%0A
Now, this solves the problem, and the code isn’t too bad. We could however refactor the code a little – for example, we could make a separate function for creating a new entry, and possibly also for searching through a bucket. Let’s pretend that we have written such functions (aka as cheating in the SIMPLE methodology), so that we can explore what such a refactored code could look like before we determine if it is worth the effort. Here:
void ioopm_hash_table_insert(ioopm_hash_table_t *ht, int key, char *value) { /// Calculate the bucket for this entry int bucket = key % 17; /// Search for an existing entry for a key entry_t *existing_entry = find_entry_for_key(ht->buckets[bucket], key); if (existing_entry != NULL) /// i.e., it exists { existing_entry->value = value; } else { /// Get a pointer to the first entry in the bucket entry_t *first_entry = ht->buckets[bucket]; /// Create a new entry entry_t *new_entry = entry_create(key, value, first_entry); /// Make the new entry the first entry in the bucket ht->buckets[bucket] = new_entry; } }
void%20ioopm_hash_table_insert%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%2C%20char%20%2Avalue%29%0A%7B%0A%20%20%2F%2F%2F%20Calculate%20the%20bucket%20for%20this%20entry%0A%20%20int%20bucket%20%3D%20key%20%25%2017%3B%0A%20%20%2F%2F%2F%20Search%20for%20an%20existing%20entry%20for%20a%20key%0A%20%20entry_t%20%2Aexisting_entry%20%3D%20find_entry_for_key%28ht-%3Ebuckets%5Bbucket%5D%2C%20key%29%3B%0A%0A%20%20if%20%28existing_entry%20%21%3D%20NULL%29%20%2F%2F%2F%20i.e.%2C%20it%20exists%0A%20%20%20%20%7B%0A%20%20%20%20%20%20existing_entry-%3Evalue%20%3D%20value%3B%0A%20%20%20%20%7D%0A%20%20else%0A%20%20%20%20%7B%0A%20%20%20%20%20%20%2F%2F%2F%20Get%20a%20pointer%20to%20the%20first%20entry%20in%20the%20bucket%0A%20%20%20%20%20%20entry_t%20%2Afirst_entry%20%3D%20ht-%3Ebuckets%5Bbucket%5D%3B%0A%20%20%20%20%20%20%2F%2F%2F%20Create%20a%20new%20entry%0A%20%20%20%20%20%20entry_t%20%2Anew_entry%20%3D%20entry_create%28key%2C%20value%2C%20first_entry%29%3B%0A%20%20%20%20%20%20%2F%2F%2F%20Make%20the%20new%20entry%20the%20first%20entry%20in%20the%20bucket%0A%20%20%20%20%20%20ht-%3Ebuckets%5Bbucket%5D%20%3D%20new_entry%3B%0A%20%20%20%20%7D%0A%7D%0A
The code above involves two functions I just made up:
find_entry_for_key() that takes a hash table and a key and
returns a pointer to an entry (or NULL if no such entry exists),
and entry_create() that creates a new entry with a given key,
value and next pointer.
Note how this lifts the abstraction of the code – someone that comes across this code can immediately understand what the code is doing, without having to understand exactly how it is done. Actually – the description above is pretty close to the bullet list description of the algorithm that we had just before we started coding. Strive for such clarity in your programs always!
Many times, it pays off to try to write the code top-down, i.e., by pretending that the key functions you need exist, and coding at decreasing level of abstraction. This causes you to initially specify the logic at a high-level, e.g., find an entry for a given key and create a new entry, and gradually drop down to a lower level (possibly applying the same strategy). This is a form of divide and conquer approach to problem solving, which is key to the possibility of solving big problems!
Before we code up the find_entry_for_key() and entry_create()
functions, let us consider one more aspect of the code. We always
insert new entries at the front of a bucket’s list (i.e., a
prepend). This means that entries in buckets are unsorted, which
in turn means that we must always search the whole list before we
can determine that it does not contain an entry with the key we
are looking for. If we tweaked our insertion so that the list was
ordered by keys, searching for a key \(k_1\) can terminate as soon as
we see a key \(k_2\) such that \(k_2 < k_1\). This seems like a good
choice if buckets have lots of entries.
This is an optimisation of the find operation. We can (and will) discuss later the case against premature optimisation (and whether or not this is an instance of it). For now, assuming that we want to implement this optimisation, it is important that we can do so without making it too costly to insert entries in a way that maintains the desired order. (Note that always inserting at the head of the list is very fast, and we will lose this now. Will losing the \(O(1)\) insertion to speed up search be an optimisation on the whole? If you have a moment to spare, this is an interesting question worth pondering. Also ask yourself if there is more information that we need to answer the question.)
Speaking of optimisation, we would like to also avoid e.g. using one search operation to find an existing entry with a given key, and failing to do so use another search to find the right place to insert the new entry.
After some thinking (and with experience, you’ll learn to see
these kinds of things immediately) we note that the two find
operations we have been discussing are strikingly similar. Let
(key, value) be the entry we are trying to add. If the first
search comes across an entry e such that e = (\(k_1\), \(v_1\))
such that \(k_1 > key\), then not only can we conclude that there is
no entry with key \(key\), but that (\(key\),\(value\)) should be added
right before e. Thus, with a little bit of cleverness, a single
find can serve both purposes with a single function and a single
function call. .
To this end, we can change the find_entry_for_key() function –
which is super cheap, as we haven’t written it yet! – to
find_previous_entry_for_key() which returns the entry before
the one we are looking for, or, in case such an entry does not
exist, the entry whose next pointer should be pointing to the
entry once we have inserted it. (Please read this paragraph
several times to make sure you get it.)
How can we distinguish between the two possible cases for
find_previous_entry_for_key()?
Here is a first (but buggy – do you see it!??) draft of the insert function:
void ioopm_hash_table_insert(ioopm_hash_table_t *ht, int key, char *value) { /// Calculate the bucket for this entry int bucket = key % 17; /// Search for an existing entry for a key entry_t *entry = find_previous_entry_for_key(ht->buckets[bucket], key); entry_t *next = entry->next; /// Check if the next entry should be updated or not if (next != NULL && next->key == key) { next->value = value; } else { entry->next = entry_create(key, value, next); } }
void%20ioopm_hash_table_insert%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%2C%20char%20%2Avalue%29%0A%7B%0A%20%20%2F%2F%2F%20Calculate%20the%20bucket%20for%20this%20entry%0A%20%20int%20bucket%20%3D%20key%20%25%2017%3B%0A%20%20%2F%2F%2F%20Search%20for%20an%20existing%20entry%20for%20a%20key%0A%20%20entry_t%20%2Aentry%20%3D%20find_previous_entry_for_key%28ht-%3Ebuckets%5Bbucket%5D%2C%20key%29%3B%0A%20%20entry_t%20%2Anext%20%3D%20entry-%3Enext%3B%0A%0A%20%20%2F%2F%2F%20Check%20if%20the%20next%20entry%20should%20be%20updated%20or%20not%0A%20%20if%20%28next%20%21%3D%20NULL%20%26%26%20next-%3Ekey%20%3D%3D%20key%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20next-%3Evalue%20%3D%20value%3B%0A%20%20%20%20%7D%0A%20%20else%0A%20%20%20%20%7B%0A%20%20%20%20%20%20entry-%3Enext%20%3D%20entry_create%28key%2C%20value%2C%20next%29%3B%0A%20%20%20%20%7D%0A%7D%0A
If you added this to hash_table.c and called the method in
main() (you should!) in the spirit of always making sure that
you have a runnable program, you would see it blow up! Why?
Because we have forgotten about an important edge case, namely
that the way we have coded up the insertion case requires that
there is always a preceding entry – which is not true for the
first entry in the bucket’s list. Doh! (Forgetting a case is a
typical programmer mistake, and you should expect to make it many
times more.)
Luckily, there is an easy fix to fix this error – which may not be intuitive unless you have seen it before: initialise each bucket’s list to start with an entry that we never use except as the previous node to the actual first entry. This trick is common and such an entry is commonly referred to as a “dummy” or the “sentinel”.
Here are two ways to add a dummy entry to the buckets’ lists:
- Add a
forloop toioopm_hash_table_create()that callsentry_create(0, NULL, NULL)and stores the result as the start of each bucket - Change the representation of
entry_t *buckets[17]inhash_table_ttoentry_t buckets[17].
I personally prefer the 2nd alternative (there is an even better
way which we will return to later). Figures 4 and 5
show the changes to the hash table structure in memory. For
clarity, the entry with key 4 is the previous entry of the entry with key 208.
Furthermore, its previous entry of the entry is the dummy (with
key 0, value NULL and next pointer pointing to it.)
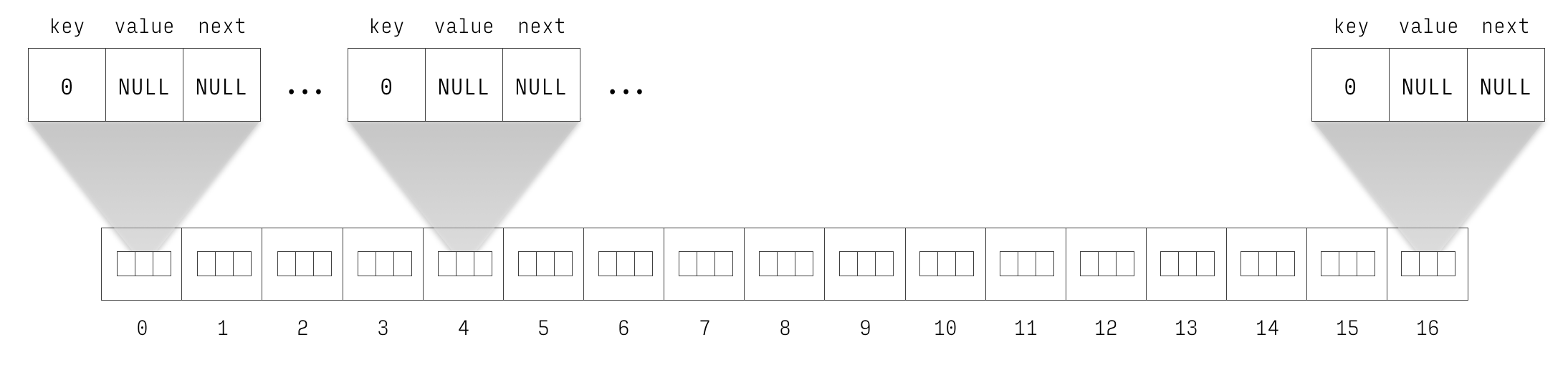
Figure 4: Newly initialised hash table with inlined dummy entries.
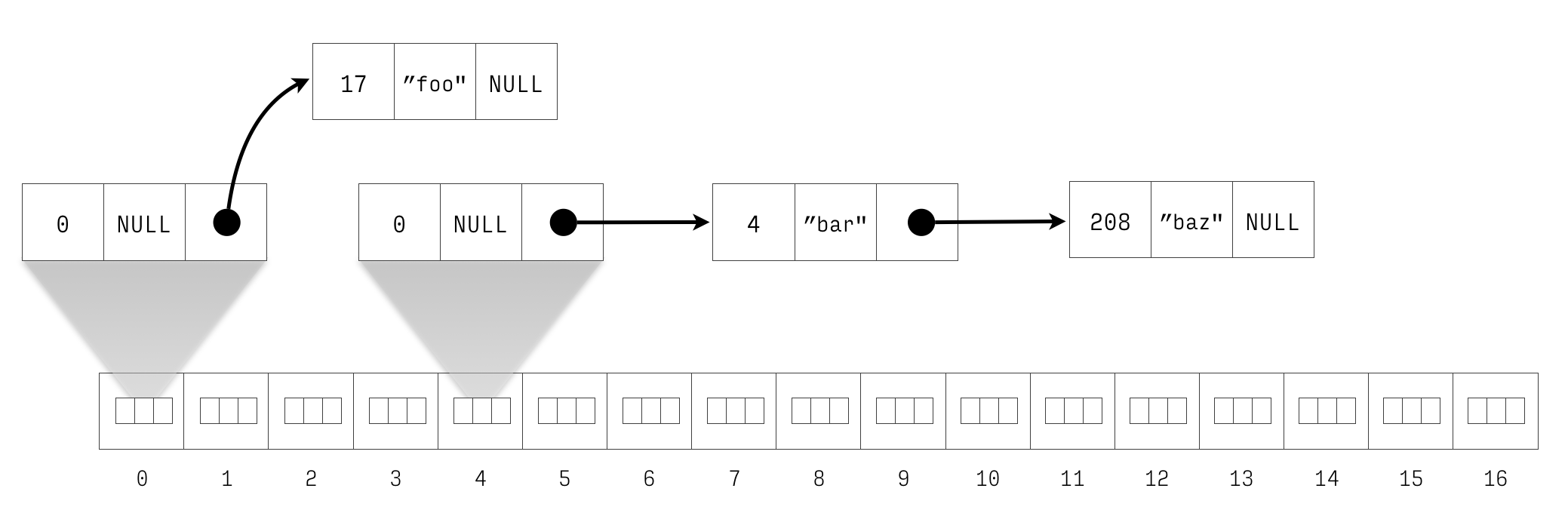
Figure 5: Newly initialised hash with inlined dummy entries with 4 \(\mapsto\) bar, 17 \(\mapsto\) foo and 208 \(\mapsto\) baz. The entry with key 4 is the previous entry of the entry with key 208.
To make this work, one more change is needed – which is subtle
but important. In the call to find_previous_entry_for_key(),
change ht->buckets[bucket] to &ht->buckets[bucket]. This
passes in the address to the entry in the bucket rather than
passes in a copy of the entire entry. This is a classic issue of
pointer semantics vs value semantics (aka pass by pointer vs. pass
by value).
This implementation represents a classic trade-off: we pay a few extra bytes of memory for a nicer and cleaner implementation. This is almost always worth it, so long as the costs are moderate. If we have a large number of buckets, and a small number of entries in each bucket, the ratio of dummies per entry will be high. As long as the number of buckets is fixed to 17, the overhead is 17 entries, which is negligible on a modern machine.
4.2.1 Finish This Step
Finishing this step means finishing the implementation of
ioopm_hash_table_insert(). That entails the following:
- Implement
find_previous_entry_for_key()following one of the two suggestions from above for how to add a dummy node. - Implement
entry_create(). - Implement a couple of tests for
ioopm_hash_table_insert()following the instructions in Feature 4: Inserting Values. - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step1.
Hints: For 1. and 2., you have plenty of help from the initial
stabs at implementing ioopm_hash_table_insert(). For 3., there
is plenty of good stuff in the section on test-driven approach to
implementation.
Note that (at least for now) both find_previous_entry_for_key()
and entry_create() are private functions which are only meant to
be used from inside the hash table. That means both should be
declared static, like so:
static entry_t *entry_create(...TODO...) { ...TODO... }
static%20entry_t%20%2Aentry_create%28...TODO...%29%0A%7B%0A%20%20...TODO...%0A%7D%0A
4.3 Step 2: Looking Up the Value for a Key
The code for insertion already required that
we write some code for finding an entry for a given key. We were
diligent enough to refactor our code to extract the
searching code as a function. That will immediately pay off
because we can reuse that function in the implementation of
ioopm_hash_table_lookup() that looks up the value for a given
key.
Before you look at the code below, take a few seconds to think of
how you would implement ioopm_hash_table_lookup() using the
find_previous_entry_for_key() function.
Here is one possible implementation:
char *ioopm_hash_table_lookup(ioopm_hash_table_t *ht, int key) { /// Find the previous entry for key entry_t *tmp = find_previous_entry_for_key(ht->buckets[key % 17], key); entry_t *next = tmp->next; if (next && next->key == key) { /// If entry was found, return its value... return next->value; } else { /// ... else return NULL return NULL; /// hmm... } }
char%20%2Aioopm_hash_table_lookup%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%29%0A%7B%0A%20%20%2F%2F%2F%20Find%20the%20previous%20entry%20for%20key%0A%20%20entry_t%20%2Atmp%20%3D%20find_previous_entry_for_key%28ht-%3Ebuckets%5Bkey%20%25%2017%5D%2C%20key%29%3B%0A%20%20entry_t%20%2Anext%20%3D%20tmp-%3Enext%3B%0A%0A%20%20if%20%28next%20%26%26%20next-%3Ekey%20%3D%3D%20key%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20%2F%2F%2F%20If%20entry%20was%20found%2C%20return%20its%20value...%0A%20%20%20%20%20%20return%20next-%3Evalue%3B%0A%20%20%20%20%7D%0A%20%20else%0A%20%20%20%20%7B%0A%20%20%20%20%20%20%2F%2F%2F%20...%20else%20return%20NULL%0A%20%20%20%20%20%20return%20NULL%3B%20%2F%2F%2F%20hmm...%0A%20%20%20%20%7D%0A%7D%0A
The reason for the hmm comment above is that next->value could
also legally be NULL – nothing restricts a user from using
NULL as a value for a key. Thus, using NULL as a marker
denoting failure isn’t a very good idea.
Thinking a bit more mathematically, lookup of a key in a hash table is a partial function because a hash table is not likely to contain every possible key (quite the opposite). C does not have support for partial functions, so we need to lift the function to a total function that simply maps all unmapped keys to some value. It is desirable that this value is not in the domain of the partial function, or we won’t always be able to tell whether we have successfully looked up the value for a key or not.
Someone could argue that NULL should not be a legal string
value, but that argument is going to fall over for say integer
values or float values. Granted, we aren’t supporting these yet,
but in the back of our minds, we know we conveniently forgot about
those to simplify the problem to make progress, in exchange to not
forget them indefinitely.
So, if we cannot use NULL (or any other special value), what are
our options? Here are some:
- Let the function return two values, adding one boolean value
that indicates success (accessing the other returned value is
only alloed if success is
true). - Add a separate public function for checking whether a key is mapped to a value, and only accept valid keys, and terminating the program using e.g., an assertion if an invalid key is detected.
- Use some other means of signalling an error to the user.
We now go through these approaches in more detail.
This aspect of the assignment is a good fit for Achievement I24.
4.3.1 Returning More than a Single Value from a Function
Many modern programming languages support the notion of tuples,
which allow collecting multiple values in a group. If we were
programming e.g., Haskell or Python, we could do something like
return (success, value). C, however, does not support tuples. It
we want to return multiple values using the return statement, we
must create a special struct for doing so. For example, we could
define a struct option for this very purpose:
typedef struct option option_t; struct option { bool success; char *value; };
typedef%20struct%20option%20option_t%3B%0Astruct%20option%0A%7B%0A%20%20bool%20success%3B%0A%20%20char%20%2Avalue%3B%0A%7D%3B%0A
Now we can change the return type of ioopm_hash_table_lookup()
to option_t, and update the return statements:
if (next && next->value) { option_t result = { .success = true, .value = next->value }; return result; } else { option_t result = { .success = false }; return result; }
if%20%28next%20%26%26%20next-%3Evalue%29%0A%20%20%7B%0A%20%20%20%20option_t%20result%20%3D%20%7B%20.success%20%3D%20true%2C%20.value%20%3D%20next-%3Evalue%20%7D%3B%0A%20%20%20%20return%20result%3B%0A%20%20%7D%0Aelse%0A%20%20%7B%0A%20%20%20%20option_t%20result%20%3D%20%7B%20.success%20%3D%20false%20%7D%3B%0A%20%20%20%20return%20result%3B%0A%20%20%7D%0A
Note the 2nd creation of the result value – it omits the
value field, having it implicitly initialised to NULL (one of
the few times C actually forces initialisation of something – all
bits that are not explicitly initialised are zeroed out). As
false is 0, the .success = false is actually redundant, but
leaving it out would lose a lot of clarity in the code so it makes
every bit of sense to leave it in.
However, if you are keen to trim the code a little, it is actually possible to write it more succinctly, by omitting the intermediate variable, like so:
if (next && next->value) { return (option_t) { .success = true, .value = next->value }; } else { return (option_t) { .success = false }; }
if%20%28next%20%26%26%20next-%3Evalue%29%0A%20%20%7B%0A%20%20%20%20return%20%28option_t%29%20%7B%20.success%20%3D%20true%2C%20.value%20%3D%20next-%3Evalue%20%7D%3B%0A%20%20%7D%0Aelse%0A%20%20%7B%0A%20%20%20%20return%20%28option_t%29%20%7B%20.success%20%3D%20false%20%7D%3B%0A%20%20%7D%0A
While we are at it, we can define some macros that raise the level
of abstraction for us. The code below defines four macros, two for
creating option values (Success and Failure) and two more for
inspecting option values (Successful and Unsuccessful).
#define Success(v) (option_t) { .success = true, .value = v }; #define Failure() (option_t) { .success = false }; #define Successful(o) (o.success == true) #define Unsuccessful(o) (o.success == false)
%23define%20Success%28v%29%20%20%20%20%20%20%28option_t%29%20%7B%20.success%20%3D%20true%2C%20.value%20%3D%20v%20%7D%3B%0A%23define%20Failure%28%29%20%20%20%20%20%20%20%28option_t%29%20%7B%20.success%20%3D%20false%20%7D%3B%0A%23define%20Successful%28o%29%20%20%20%28o.success%20%3D%3D%20true%29%0A%23define%20Unsuccessful%28o%29%20%28o.success%20%3D%3D%20false%29%0A
Now the code becomes a lot clearer:
if (next && next->value) { return Success(next->value); } else { return Failure(); }
if%20%28next%20%26%26%20next-%3Evalue%29%0A%20%20%7B%0A%20%20%20%20return%20Success%28next-%3Evalue%29%3B%0A%20%20%7D%0Aelse%0A%20%20%7B%0A%20%20%20%20return%20Failure%28%29%3B%0A%20%20%7D%0A
And likewise code for inspecting an option value:
if (Successful(result))
{
... result.value ...
}
if%20%28Successful%28result%29%29%0A%20%20%7B%0A%20%20%20%20...%20result.value%20...%0A%20%20%7D%0A
As C does not support parametric polymorphic structs, we cannot
(as we would in e.g. Haskell, Java, or Python) live with a single
option_t. We would end up creating lots of them. Luckily, there
is another way in C to return multiple values from a function, by
using pointer semantics. As an (unrelated) example, consider the
below swap() functions that takes the addresses of two
integers (e.g., the locations of where the contents of two
variables are stored) and swaps them (e.g., swaps the two
variables’ contents):
void swap(int *a, int *b) { int tmp = *a; *a = *b; *b = tmp; }
void%20swap%28int%20%2Aa%2C%20int%20%2Ab%29%0A%7B%0A%20%20int%20tmp%20%3D%20%2Aa%3B%0A%20%20%2Aa%20%3D%20%2Ab%3B%0A%20%20%2Ab%20%3D%20tmp%3B%0A%7D%0A
Because C allows taking the address of stack variables, any
function that takes a pointer can potentially be used to update a
stack variable of the caller. In this case, we call a and b
out parameters. Some programming languages distinguish these
from pointers by e.g., a keyword like out but in C they are just
simply pointers, and whether something is an out parameter or not
is only in the programmer’s head (and possibly also in the
documentation, if it exists).
void example() { int x = 42; int y = 4711; printf("x=%d, y=%d\n", x, y); /// prints x=42, y=4711 swap(&x, &y); printf("x=%d, y=%d\n", x, y); /// prints x=4711, y=42 }
void%20example%28%29%0A%7B%0A%20%20int%20x%20%3D%2042%3B%0A%20%20int%20y%20%3D%204711%3B%0A%20%20printf%28%22x%3D%25d%2C%20y%3D%25d%5Cn%22%2C%20x%2C%20y%29%3B%20%2F%2F%2F%20prints%20x%3D42%2C%20y%3D4711%0A%20%20swap%28%26x%2C%20%26y%29%3B%0A%20%20printf%28%22x%3D%25d%2C%20y%3D%25d%5Cn%22%2C%20x%2C%20y%29%3B%20%2F%2F%2F%20prints%20x%3D4711%2C%20y%3D42%0A%7D%0A
We can use out parameters to communicate success with a caller to
the lookup function, either by adding an additional parameter with
type bool *, or making the function return a bool (the
success/fail indicator), and take a pointer to a place in memory
storing a string (a pointer to a char *) which will be updated
upon success.
Let’s say we pick the second option. Here is how we would call the lookup function and inspect the result:
char *result = NULL; bool success = ioopm_hash_table_lookup(ht, key, &result); if (success) { // success => result was updated printf("key %d maps to %s!", key, result); } else { // !success => result == NULL printf("key %d does not map to anything!", key); }
char%20%2Aresult%20%3D%20NULL%3B%0Abool%20success%20%3D%20ioopm_hash_table_lookup%28ht%2C%20key%2C%20%26result%29%3B%0Aif%20%28success%29%0A%20%20%7B%0A%20%20%20%20%2F%2F%20success%20%3D%3E%20result%20was%20updated%0A%20%20%20%20printf%28%22key%20%25d%20maps%20to%20%25s%21%22%2C%20key%2C%20result%29%3B%0A%20%20%7D%0Aelse%0A%20%20%7B%0A%20%20%20%20%2F%2F%20%21success%20%3D%3E%20result%20%3D%3D%20NULL%0A%20%20%20%20printf%28%22key%20%25d%20does%20not%20map%20to%20anything%21%22%2C%20key%29%3B%0A%20%20%7D%0A
4.3.2 Failure is Not an Option
The strategy to use a separate function to let the user first check whether something is in the hash table before calling lookup is valid for a limited class of scenarios, where one can reliably expect that all keys are valid. Having a separate function to check whether a key is in the hash table or not isn’t a very good idea as every lookup will now have to search for the key twice – once for checking that it is in the hash table and one for returning its associated value. That seems wasteful!
Using failure is not an option often requires rethinking an
operation (and this is not always possible) so that it becomes a
total function. One way to do so for ioopm_hash_table_lookup()
is to change the behaviours of the function so that it returns, not
the value for the given key, but the location of that value.
Think about it: if there is an entry for the key, there is a
non-NULL location in the hash table data structure that holds
the corresponding value. If there is no entry, there is no such
location. In other words:
\[ lookup(h, k) = \left\{\begin{array}{ll} address\_of(v) & \text{if} ~ (k,v) \in h \\ \texttt{NULL} & \text{otherwise} \\ \end{array}\right. \]
This works even when \(v\) is NULL since the location of that
NULL value is guaranteed to be stored somewhere (i.e., the
location cannot be NULL).
With this design, the signature of ioopm_hash_table_lookup()
changes to return a char ** – a pointer to a pointer to a
character (if your mind boggles at the thought of a pointer to
another pointer, you can look here).
This design now very neatly supports both looking up and replacing an existing entry:
char **value_ptr = ioopm_hash_table_lookup(ht, key); char *value = NULL; // no value yet if (value_ptr != NULL) { // key was in ht value = *value_ptr; // Value now points to the string key maps to in ht *value_ptr = "Some other string"; // We just updated the value! } else { // key was not in ht }
char%20%2A%2Avalue_ptr%20%3D%20ioopm_hash_table_lookup%28ht%2C%20key%29%3B%0Achar%20%2Avalue%20%3D%20NULL%3B%20%2F%2F%20no%20value%20yet%0Aif%20%28value_ptr%20%21%3D%20NULL%29%0A%20%20%7B%0A%20%20%20%20%2F%2F%20key%20was%20in%20ht%0A%20%20%20%20value%20%3D%20%2Avalue_ptr%3B%20%2F%2F%20Value%20now%20points%20to%20the%20string%20key%20maps%20to%20in%20ht%0A%20%20%20%20%2Avalue_ptr%20%3D%20%22Some%20other%20string%22%3B%20%2F%2F%20We%20just%20updated%20the%20value%21%0A%20%20%7D%0Aelse%0A%20%20%7B%0A%20%20%20%20%2F%2F%20key%20was%20not%20in%20ht%0A%20%20%7D%0A
In this design, we only needed to lookup the value once – once we found the location, we could hold on to that location and use it to update the value in the hash table in constant time.
Caveats:
- This seems to work well for lookup, but not for remove since the remove function frees the entry that holds the value whose location we would return (read that sentence again until you get it). In other words, by definition, remove cannot return a pointer to a place in the hash table, because it needs to remove that very place. One possibility is to change remove to simply not return the value removed, but this may force situations where extra lookups must be inserted12. (It is also possible to hang on to the value even after the entry is free’d, e.g. by storing it in the dummy, so that it is possible to return it’s address.)
- Note that keeping a pointer to a value in a hash table can be dangerous if something causes the value to move while we are keeping this pointer around. This needs to be reflected in the documentation.
4.3.3 Using Built-in Mechanisms for Propagating Errors
C has a very crude mechanic for propagating errors called errno.
Open a terminal and type man errno and the system will
(hopefully, depending on what you are using) display the errno
manual pages. If you scan through them (you can scroll with space
bar, go up with u, quit with q and search using /), you will
find a nice error called EINVAL for invalid argument, which
captures the situation in point – the lookup function was called
with an invalid argument: a non-existing key.
In the case of errno you will have to include errno.h,
write EINVAL to the global errno variable in the else
branch, and return whatever value you want in case of a failed
lookup. On the receiver side, a user will have to inspect
the value of errno after each call.
You should document how your functions interact with errno –
what functions set it, to what, and under what circumstances.
4.3.4 Finishing This Step
To finish this step, finish the implementation of
ioopm_hash_table_lookup(). Feel free to base it on the initial
code above.
- Handle failing lookups by one of the alternatives above Note that your choice might force you to change the signature of the function (changing the return type and/or adding an additional parameter). Make sure to properly document your choice in the comments in the header-file.
- Implement a couple of tests for
ioopm_hash_table_lookup()following the instructions in Feature 3: Looking up Values. - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step2.
4.4 Step 3: Removing the Value for a Key
By now we can create new hash tables, add (key, value) entries to them, and look up the value for a given key. Next step is to add support for removing an entry for a given key.
Pause for a moment now and sketch your own implementation of how to remove an entry. It may be useful to start from a drawing of a hash table (e.g. Figure 5) and draw what the hash table should look like after removal, and from these two start and end points extrapolate an algorithm for removing an entry.
Summarising lessons from insertion, we had to deal with:
- Manipulating a linked sequence of entries somewhere in the middle
- Manipulating the last element of a linked sequence of entries
- Manipulating the first element of a linked sequence of entries
In the case of 1., there is both a previous and a next entry. In the case of 2., there is no next entry. In the case of 3., there is no previous entry.
Because we inserted a dummy which remains at the head of the list always, we were able to simplify the 3rd case so that it effectively becomes like the 1st. This made the code simpler because we could rely on the fact that there is always a previous entry, even when the list is “empty”.
The algorithm for removing is isomorphic to insertion, except that instead of creating a new entry, we must delete the entry. (As one would expect, removing an entry must deal with the same cases as insertion.)
Furthermore, the signature and comments for
ioopm_hash_table_remove() states that the function takes a hash
table argument and a integer key argument, and returns a string –
the value removed. Thus, there are also strong similarities with
ioopm_hash_table_lookup(). We must both return the value (if it
exists) and delete the entry for the key (if it exist). Just like
before, we need to consider what to do if the key argument does
not match a key in the hash table. You already solved this for
lookup. Make similar adjustments for remove – pick the same
solution strategy.
Finally, here is an algorithm for removing an element:
1. Find the previous entry to the one we would like to remove
1.1 If such an entry cannot be found, do nothing
1.2 Otherwise, unlink the entry by updating the previous
entry's next field so that it "skips over the entry" and
return the memory that the entry reserved to the system so
that it can be reused
4.4.1 A Note on Manual Memory Management in C
A call to malloc() or calloc() (and similar) returns a pointer
(an address) to a place in on the heap guaranteed to fit at
least the number of bytes asked for – or NULL if we have
exhausted computer memory (not likely to happen except if your
program is buggy). Unlike local variables that are stored on the
stack, memory allocated on the heap is not returned automatically
when we are done with it. Heap memory must be returned
explicitly through a call to free() with a pointer to the heap
memory that you want to free as argument. It is not possible to
partially free a memory block returned by calloc (malloc, etc.),
or use a single free to free more than one block. (See this slide
set for some pictures to go with that statement.)
Calling free() on some memory and subsequently accessing it is a
classic bug in C programs (and most systems where programmers
manually manage memory). In C, The semantics of accessing memory
that has been freed (or before it has been allocated) is
undefined, which morally means that anything can happen (say the
computer deleting all its files) but in practice generally means
that the program will (at best) crash or produce incorrect
results.
Although out of scope for this course, use-after-free bugs are classic security exploits of C programs.
Here are some good rules of thumb to use from now on:
- Pair allocation and deallocation. For every allocation (e.g.,
calloc())in your program, write a function that takes care of the deallocation (free()). In Step 4, we will writeioopm_hash_table_destroy()that contain the deallocations pairing with the allocations inioopm_hash_table_create(). It would have been more proper to make Step 4 into Step 1, but we chose to delay it to make more “interesting” progress faster. - Put allocation and deallocation in separate functions. We
already created a
entry_create()function to encapsulate the behaviour of creating entries and lift the abstraction of the code inioopm_hash_table_insert(). The deallocation pairing with this should go into a function of its own, e.g.,entry_destroy()(even if the latter only contains a call tofree()).
Memorise these terms for classical memory bugs (we will extend this list later):
- Dangling pointer: a pointer to some memory that we have already freed. The semantics of following this pointer (aka dereferencing it) is undefined.
- Memory leak: allocated memory that the program has no pointer to, and therefore is unable to free. Too many memory leaks will cause memory to fill up, which can make a program slow down or crash.
- Use after free: Following a dangling pointer (see 1.).
Note that dangling pointers are not dangerous in themselves – but
using them are. It is almost impossible to not temporarily
create dangling pointers when deallocating something, until the
variable holding the dangling pointer gets updated with a valid
pointer (or NULL!), or the variable gets popped from the stack,
etc.
4.4.2 Finish This Step
Finishing this step means finishing the implementation of
ioopm_hash_table_remove().
- Finish
ioopm_hash_table_remove(). Follow the algorithm above (or come up with a better one), and augment it to handle attempts to remove keys not in the hash table. - Implement
entry_destroy()to free a single entry. Use it in remove to free the memory for a successfully removed entry. - “Walk through your code” manually and check that it is free of use-after-free, dangling pointers (not including temporary ones!) and memory leaks. Later, we will learn how to use tools to help us identify and fix such bugs.
- Implement a couple of tests for
ioopm_hash_table_remove()following the instructions in Feature 5: Removing Values. - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step3.
Hints: For 2., what should be deallocated? Look at a drawing of the hash table representation in memory for guidance.
4.5 Step 4: Tearing Down a Hash Table
We have now arrived at Step 4, the final step of Ticket #1, and the last step needed to rightfully claim that we have implemented a basic hash table. What remains is “tearing down”, i.e., a function for destroying a hash table, and deallocating all its memory.
The semantics of destroying a hash table are not obvious. Like
most times, there are design decisions that must be made. In
particular, we must answer the question: “What belongs to the hash
table?” This is a crucial design decision, and an experienced
programmer will have thought long and hard about that in the
initial design. You may have asked yourself this question
(possibly phrased differently) as you implemented
ioopm_hash_table_remove() – should we also deallocate the
values of the entries?
The answer to that question is (probably) no. Unless you make an explicitly documented choice that the hash table takes ownership over all values it stores, it seems unreasonable to assume that the life time of a value is tied to the life time of the hash table. For example, imagine a value that is mapped to different keys in two different tables. That seems like a reasonable thing, but if we cannot destroy one hash table without destroying all its values, the life times of the two hash tables are now implicitly tied to each other. This seems brittle and easy to get wrong. (Not to mention increasingly hairy if we want to use the value in additional hash tables or other structures.)
We could imagine a design where the hash table makes a private copy of all the values, and takes ownership over the copies. This avoids the tying-of-lifetimes-together, but comes with additional problems, including:
- This design uses more memory.
- If and when we generalise hash tables to support arbitrary values, we either need to force the user to make copies (lots of extra work and easy to forget), or inform the hash table how to make copies of values (values can be arbitrarily complicated, for example another hash table!).
- If we make a change to a value, we need to chase down all its copies and update them accordingly if we want the change to be propagated.
This leaves us with the simplest design, and delegation of responsibilities: The hash table only owns (and thus needs to manage) the memory it has allocated itself (meaning only the buckets array and all entries). Thus, if destroying a hash table creates memory leaks it is the fault of the programmer. This is an important design decision and really needs to be reflected in the hash table’s documentation.
With that, here is an algorithm for destroying the hash table:
1. Iterate over the buckets in the buckets array
1.1 For each bucket, iterate over its entries and deallocate them
using entry_destroy().
2. Deallocate the hash table data structure using free().
Hints: For 1., be careful with the dummy entries – if they are
part of the array, and not explicitly created with
entry_create(), they cannot be destroyed with
entry_destroy().
Be wary of accidental use-after-free. With a very high probability
(with a typical Linux or macOS setup), destroying an entry and
subsequently accessing it’s next pointer to continue the
iteration will work just fine in most programs you will write in
this course, but if you run your program through a memory
profiling tool, it will scream. Either cache the next pointer
before destroying the entry, or write your program in a tail
recursive way so that deallocation effectively happens from the
end, not from the head. Since the latter will require an extra
function that must be maintained, that seems like too much work
(to me).
4.5.1 Memory Profiling with Valgrind
It is time to introduce a new tool: Valgrind. Valgrind is a suite of tools for debugging and profiling programs. For now, we will focus on its memory profiling capabilities. We can run a program “through Valgrind”, meaning that Valgrind will be sitting between the program and the machine, observing the program’s actions, and reporting bad behaviour. Things that Valgrind will help us spot are:
- Memory leaks: When the program exits, Valgrind will print the number of allocations and deallocations in our program, if there was memory allocated when the program exited, and if that memory was reachable or not (the latter means a memory leak).
- Use-after-free: Valgrind will report accesses to memory that is not properly allocated. This includes using data after it was freed or accessing data beyond its limit (e.g., accessing the 18th bucket in our hash table with only 17 buckets).
Valgrind is not a magic tool, so it will not be able to say “fix your program by adding a free(x) on line 19”. However, it will be able to say where the memory that is being misused was allocated, which is often the only hint you need to find the mistake in the code (and possibly in your line of thinking).
Do not forget to compile your code with the -g flag
so that it has proper debug information. Without it, Valgrind’s
output will be a lot less enjoyable (or helpful).
Feel free to purposely create memory errors (leaks, use-after-free or use of uninitialised memory) and check if Valgrind catches them (it will) as a way of learning to read Valgrind’s error messages.
For now, we will only use the leak checker of Valgrind which can
be run like this: valgrind --leak-check=full ./name-of-program.
Because Valgrind alters the way your program runs, you will likely encounter cases where a program crashes when run normally but not when run under Valgrind. Do not be tempted to interpret this as a sign of the bug not being in your code.
4.5.2 Finish This Step
Finishing this step means finishing the implementation of
ioopm_hash_table_destroy() and putting Valgrind to work to weed
out any possible memory errors we might have accidentally
introduced along the way.
- Finish
ioopm_hash_table_destroy(). - Add calls to
ioopm_hash_table_destroy()in all your tests so that all hash tables created during testing are properly destroyed. - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. There are no reasons to see
any warnings or errors and in addition, Valgrind should print
out “No leaks possible” at the end13. If you are using a Makefile, add an extra entry that
allows you to run your tests through Valgrind, e.g.,
make memtest. - Make sure that the code passes your tests. Fix all memory errors reported by Valgrind.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step4.
4.6 Step 5: Refactoring
Surprise! There is actually one more thing to do before we are done with Ticket #1 – refactoring. For the time being, we will only consider three important aspects:
- Are we using naming schemes consistently? Public functions
should start with
ioopmand end with a verb that describes what they do. Public type names should start withioopmand end with_t. Private functions should be declaredstatic. - Are names of functions, variables etc. descriptive?
- Is the code free from “magic numbers”, i.e., hard coded constants that must be maintained consistently?
With respect to 1., you must use the course’s naming scheme. Learn to distinguish public and private names.
With respect to 2., there are many important aspects of
readability, but naming is probably the most important. By giving
something a good name, you are doing service to future programmers
(including yourself, next week) that will be reading your code. In
the code above, I have consistently used ht as the variable name
for a hash table. I have done so based on the following reasoning:
the name appears a lot, and a longer name would just add “noise”;
short names are fine for small scopes and the longest function is
less than 20 lines; the frequent and consistent use of an
abbreviation is easy to spot and “decode”.
With respect to 3., the code above in this document uses the number 17 a lot – the size of the array in the hash table. If we wanted to change this to 31 (say), we would have to visit all places in the code that mention 17 and ocularly inspect them to see if they should be changed to 31 or not. This is bad!
For now, we can replace all these uses by a constant (a value
which will not change) implemented as a macro. Without going into
what macros are (yet), you can define a symbol No_Buckets to
have the value 17 thus (in hash_table.c):
... #include "hash_table.h" #define No_Buckets 17 ...
...%0A%23include%20%22hash_table.h%22%0A%0A%23define%20No_Buckets%2017%0A...%0A
With this in place, you can now write No_Buckets instead of 17
wherever the code needs to know how many buckets there are. For
now, you can think of C macros as a form of search-and-replace
happening at compile time. The compiler will replace all
occurrences of No_Buckets with 17 through an unintelligent
text substitution right before the compilation. You are
effectively compiling exactly the same program as before, but if
you want to change the number of buckets, you can do so by
changing a single line of code before recompiling.
4.6.1 Finish This Step
A key property of refactoring is that we are not changing what the code does. Thus, all our previous tests should still pass. Finish this step by verifying that you did not accidentally insert bugs by making sure that the tests compile and run as before.
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step5.
5 Ticket #2: Utility Functions
We now have a working basic hash table! That’s great. In a bit, we will get to work on generalising it to support non-integer keys and non-string values, but first, let us improve of the services our hash table offers to its clients.
Typical operations on a hash table include:
- Checking how many entries it has
- Checking if the hash table is empty
- Obtaining all the keys
- Obtaining all the values
- Resetting a hash table by clearing all its entries
- Checking for the presence of a given key
- Checking for the presence of a given value
- Checking whether some predicate holds for all entries
- Checking whether some predicate holds for any entry
- Applying a given function to all entries
- Tuning the performance by changing the number of buckets
Below is an extension to the hash_table.h header file with
function prototypes for above.
Ticket #2 will (hopefully) demonstrate that once the basic features are in place, it is often easy to build on-top of these features to quickly deliver a much richer interface. Thus, even though the list of features is a lot longer in Ticket #2 than in Ticket #1, the time to implement them is not proportional.
In steps 6–9, we are going to add:
- (Step 6)
ioopm_hash_table_size()for getting the size of hash table,ioopm_hash_table_empty()for checking if the hash table is empty, andioopm_hash_table_clear()for clearing all entries in a hash table without removing the table. - (Step 7)
ioopm_hash_table_keys(), andioopm_hash_table_values()for getting arrays of all keys and values in the hash table. - (Step 8)
ioopm_hash_table_has_key(), andioopm_hash_table_has_value()which uses the functions in Step 7 for checking if a hash table contains a specific key or value. - (Step 9)
ioopm_hash_table_all()andioopm_hash_table_any()– two utility functions for checking if all (any) entries (entry) satisfies a given predicate, andioopm_hash_table_apply_to_all()– a utility function for in-place bulk operation on entries.
/// @brief returns the number of key => value entries in the hash table /// @param h hash table operated upon /// @return the number of key => value entries in the hash table int ioopm_hash_table_size(ioopm_hash_table_t *h); /// @brief checks if the hash table is empty /// @param h hash table operated upon /// @return true is size == 0, else false bool ioopm_hash_table_is_empty(ioopm_hash_table_t *h); /// @brief clear all the entries in a hash table /// @param h hash table operated upon void ioopm_hash_table_clear(ioopm_hash_table_t *h); /// @brief return the keys for all entries in a hash map (in no particular order, but same as ioopm_hash_table_values) /// @param h hash table operated upon /// @return an array of keys for hash table h int *ioopm_hash_table_keys(ioopm_hash_table_t *h); /// @brief return the values for all entries in a hash map (in no particular order, but same as ioopm_hash_table_keys) /// @param h hash table operated upon /// @return an array of values for hash table h char **ioopm_hash_table_values(ioopm_hash_table_t *h); /// @brief check if a hash table has an entry with a given key /// @param h hash table operated upon /// @param key the key sought bool ioopm_hash_table_has_key(ioopm_hash_table_t *h, int key); /// @brief check if a hash table has an entry with a given value /// @param h hash table operated upon /// @param value the value sought bool ioopm_hash_table_has_value(ioopm_hash_table_t *h, char *value); /// @brief check if a predicate is satisfied by all entries in a hash table /// @param h hash table operated upon /// @param pred the predicate /// @param arg extra argument to pred bool ioopm_hash_table_all(ioopm_hash_table_t *h, ioopm_apply_function pred, void *arg); /// @brief check if a predicate is satisfied by any entry in a hash table /// @param h hash table operated upon /// @param pred the predicate /// @param arg extra argument to pred bool ioopm_hash_table_any(ioopm_hash_table_t *h, ioopm_apply_function pred, void *arg); /// @brief apply a function to all entries in a hash table /// @param h hash table operated upon /// @param apply_fun the function to be applied to all elements /// @param arg extra argument to apply_fun void ioopm_hash_table_apply_to_all(ioopm_hash_table_t *h, ioopm_apply_function apply_fun, void *arg);
%2F%2F%2F%20%40brief%20returns%20the%20number%20of%20key%20%3D%3E%20value%20entries%20in%20the%20hash%20table%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40return%20the%20number%20of%20key%20%3D%3E%20value%20entries%20in%20the%20hash%20table%0Aint%20ioopm_hash_table_size%28ioopm_hash_table_t%20%2Ah%29%3B%0A%0A%2F%2F%2F%20%40brief%20checks%20if%20the%20hash%20table%20is%20empty%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40return%20true%20is%20size%20%3D%3D%200%2C%20else%20false%0Abool%20ioopm_hash_table_is_empty%28ioopm_hash_table_t%20%2Ah%29%3B%0A%0A%2F%2F%2F%20%40brief%20clear%20all%20the%20entries%20in%20a%20hash%20table%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0Avoid%20ioopm_hash_table_clear%28ioopm_hash_table_t%20%2Ah%29%3B%0A%0A%2F%2F%2F%20%40brief%20return%20the%20keys%20for%20all%20entries%20in%20a%20hash%20map%20%28in%20no%20particular%20order%2C%20but%20same%20as%20ioopm_hash_table_values%29%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40return%20an%20array%20of%20keys%20for%20hash%20table%20h%0Aint%20%2Aioopm_hash_table_keys%28ioopm_hash_table_t%20%2Ah%29%3B%0A%0A%2F%2F%2F%20%40brief%20return%20the%20values%20for%20all%20entries%20in%20a%20hash%20map%20%28in%20no%20particular%20order%2C%20but%20same%20as%20ioopm_hash_table_keys%29%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40return%20an%20array%20of%20values%20for%20hash%20table%20h%0Achar%20%2A%2Aioopm_hash_table_values%28ioopm_hash_table_t%20%2Ah%29%3B%0A%0A%2F%2F%2F%20%40brief%20check%20if%20a%20hash%20table%20has%20an%20entry%20with%20a%20given%20key%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20key%20the%20key%20sought%0Abool%20ioopm_hash_table_has_key%28ioopm_hash_table_t%20%2Ah%2C%20int%20key%29%3B%0A%0A%2F%2F%2F%20%40brief%20check%20if%20a%20hash%20table%20has%20an%20entry%20with%20a%20given%20value%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20value%20the%20value%20sought%0Abool%20ioopm_hash_table_has_value%28ioopm_hash_table_t%20%2Ah%2C%20char%20%2Avalue%29%3B%0A%0A%2F%2F%2F%20%40brief%20check%20if%20a%20predicate%20is%20satisfied%20by%20all%20entries%20in%20a%20hash%20table%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20pred%20the%20predicate%0A%2F%2F%2F%20%40param%20arg%20extra%20argument%20to%20pred%0Abool%20ioopm_hash_table_all%28ioopm_hash_table_t%20%2Ah%2C%20ioopm_apply_function%20pred%2C%20void%20%2Aarg%29%3B%0A%0A%2F%2F%2F%20%40brief%20check%20if%20a%20predicate%20is%20satisfied%20by%20any%20entry%20in%20a%20hash%20table%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20pred%20the%20predicate%0A%2F%2F%2F%20%40param%20arg%20extra%20argument%20to%20pred%0Abool%20ioopm_hash_table_any%28ioopm_hash_table_t%20%2Ah%2C%20ioopm_apply_function%20pred%2C%20void%20%2Aarg%29%3B%0A%0A%2F%2F%2F%20%40brief%20apply%20a%20function%20to%20all%20entries%20in%20a%20hash%20table%0A%2F%2F%2F%20%40param%20h%20hash%20table%20operated%20upon%0A%2F%2F%2F%20%40param%20apply_fun%20the%20function%20to%20be%20applied%20to%20all%20elements%0A%2F%2F%2F%20%40param%20arg%20extra%20argument%20to%20apply_fun%0Avoid%20ioopm_hash_table_apply_to_all%28ioopm_hash_table_t%20%2Ah%2C%20ioopm_apply_function%20apply_fun%2C%20void%20%2Aarg%29%3B%0A
5.1 Step 6: size, is empty and clear
5.1.1 Count the Number of Entries
To get going, let us start with something easy: counting the number of entries in a hash table. An algorithm for this could look thus:
1. Set a counter to zero
2. Iterate over the buckets in the buckets array
2.1 For each bucket, iterate over its entries, incrementing the
counter by one for each step
3. Return the counter value
This should be straightforward. If you are following the test-driven approach, start by making a test that takes the size of an empty hash table, a hash table with one entry, and a hash table with several entries. If you are following the classical approach, make the same tests, but afterwards.
An alternative design is to let the hash table keep track of its
size and increment and decrement it on insertion and removal. This
amortises the cost of making size calculations over the entire
life-time of a hash table, allowing us to get the current size of
a hash table in \(O(1)\) time. This design is good if we query the
size often and otherwise less important or possibly even wasteful.
In this design, add a size field to struct hash_table_t, and
update insert and remove to do ht->size += 1 or ht->size -= 1.
Note that when removal fails, or insertion overwrites a
preexisting entry, no manipulation of size is needed.
5.1.2 Is the Hash Table Empty?
We are now ready to add the test for whether a hash table is
empty. The easiest way to do this is to build on the definition of
ioopm_hash_table_size() and simply do:
bool ioopm_hash_table_is_empty(ioopm_hash_table_t *ht) { return ioopm_hash_table_size(ht) == 0; }
bool%20ioopm_hash_table_is_empty%28ioopm_hash_table_t%20%2Aht%29%0A%7B%0A%20%20return%20ioopm_hash_table_size%28ht%29%20%3D%3D%200%3B%0A%7D%0A
This is a fine way to implement this, but unless we can lookup the
size of the hash table in \(O(1)\) time, it is not very efficient –
at least not if the hash table is large. When counting the size,
as soon as the count hits 1, we know that the hash table is not
empty, but by building on ioopm_hash_table_size(), we will keep
counting regardless.
A more efficient way is to iterate over the buckets in the bucket
array and check if there are any entries at all (not counting the
dummy entries). As soon as we find one, we can return false. If
we manage to complete the iteration, simply return true. If we
can get the size of the hash table in \(O(1)\), that is of course more
efficient.
5.1.3 Clearing a Hash Table
In many cases, it makes sense to be able to reset a hash table instead of destroying it and creating a fresh one. For example, it may be that the hash table is shared by multiple data structures in the program.
(Note that a test for ioopm_hash_table_clear() could make use of
ioopm_hash_table_is_empty().)
Clearing a hash table is similar to ioopm_hash_table_destroy(),
except that clearing should not destroy dummy nodes nor the array
of buckets. If you went with a hash table representation where the
elements of the buckets array are entry_t as opposed to entry_t
*, it makes sense to extract the code for
ioopm_hash_table_clear() from ioopm_hash_table_destroy(), and
then call ioopm_hash_table_clear() from
ioopm_hash_table_destroy().
5.1.4 Finish This Step
- Implement
ioopm_hash_table_size(),ioopm_hash_table_is_empty()andioopm_hash_table_clear(). Feel free to keep inefficient implementations for now, and put optimisations in your backlog. - Write tests for all functions, before or after implementing them, depending on your way of working.
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step6.
5.2 Step 7: Get all Keys and Values
Another typical operation on a hash table is getting all keys or
all values in the functions ioopm_hash_table_keys() and
ioopm_hash_table_values() respectively. For now, we will simply
return an array of keys or an array of values, but as a later
step, we will revisit this function and change it to use a more
“proper” data structure.
An interesting design decision for the implementation of these
functions are the order of the elements in the arrays. Luckily,
the documentation does not promise any particular order, except
that if one calls both ioopm_hash_table_keys() and
ioopm_hash_table_values(), keys and values for the same entry
should have the same index in the array.
Creating an array to return requires knowing the size of the hash
table – lucky we just implemented that function. Because
ioopm_hash_table_values() returns an array of pointers, we could
let the last pointer point to NULL and use that as an end
marker. (If you do so, edit the documentation for the function to
state the array is NULL terminated.) For the integer array, we
are not so lucky.
Coming up with an algorithm(s) for these functions is straightforward, and not that different from previous functions.
5.2.1 Finish This Step
- Implement
ioopm_hash_table_keys(), andioopm_hash_table_values(). - Write tests for both functions, before or after implementing
them, depending on your way of working. Don’t forget to use
free()in your tests to deallocate the arrays of keys and values. - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step7.
5.3 Step 8: Looking for Keys and Values
In our series of common operations on hash tables, we have arrived at asking whether a hash table contains a specific key or value.
The function ioopm_hash_table_has_key() can be implemented using
ioopm_hash_table_lookup() augmented with your chosen scheme for
error handling. Note that if you used errno, you probably want
to clear any error code from lookup in has key. In that case (or
possibly regardless), you can instead choose to piggy back on
find_previous_entry_for_key() which avoids the error handling
issue altogether.
Searching for a value in ioopm_hash_table_has_value() is
different than searching for a key since we do not know what
bucket to select. Consequently, we must search all values. Next,
we need to ponder what method we use to compare values. In the
current increment, our values are strings so we can use the
strcmp() function from string.h. (Do not forget to include
string.h in your hash_table.c file.)
This could be used as part of demonstrating Achievement H19.
An alternative way to search for a value is to use
ioopm_hash_table_values() to get an array of values and iterate
over the array. That approach can make the code a tiny bit
simpler, but – unless you managed to implement that at \(O(1)\) cost
– at the cost of iterating over the values twice, and having to
free the array in the end.
5.3.1 Finish This Step
- Implement
ioopm_hash_table_has_key(), andioopm_hash_table_has_value(). - Write tests for both functions, before or after implementing
them, depending on your way of working. When testing
ioopm_hash_table_has_value(), test using both the identical string (the same string) and the equivalent string (i.e., an unmodified copy of the original). Use a function likestrdup()to create a copy of a string. (Don’t forget to deallocate the copy or Valgrind will complain.) - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step8.
If you cannot get strdup() to work, either add #define
_XOPEN_SOURCE 700 to the source file, or add
-D_XOPEN_SOURCE=700 as a compiler flag. If all else fails, here
is an alternative implementation:
char *ioopm_strdup(char *str) { size_t len = strlen(str); char *result = calloc(len + 1, sizeof(char)); strncpy(result, str, len); return result; }
char%20%2Aioopm_strdup%28char%20%2Astr%29%0A%7B%0A%20%20size_t%20len%20%3D%20strlen%28str%29%3B%0A%20%20char%20%2Aresult%20%3D%20calloc%28len%20%2B%201%2C%20sizeof%28char%29%29%3B%0A%20%20strncpy%28result%2C%20str%2C%20len%29%3B%0A%20%20return%20result%3B%0A%7D%0A
5.4 Step 9: General Predicates and Function Application
C allows us to pass around a pointer to a function. This allows us to higher-order functions in a crude but working way.
In many cases, we might want to check if all or any of the entries in a hash table satisfy some property. To code this up in the current form, we will have to get all the keys (and or values) and iterate over them and check if the property holds. For example, the following code checks if P holds for all key and value pairs.
int size = ioopm_hash_table_size(ht); int *keys = ioopm_hash_table_keys(ht); char **values = ioopm_hash_table_values(ht); bool result = true; for (int i = 0; i < size && result; ++i) { result = result && P(keys[i], values[i], x); }
int%20size%20%3D%20ioopm_hash_table_size%28ht%29%3B%0Aint%20%2Akeys%20%3D%20ioopm_hash_table_keys%28ht%29%3B%0Achar%20%2A%2Avalues%20%3D%20ioopm_hash_table_values%28ht%29%3B%0Abool%20result%20%3D%20true%3B%0Afor%20%28int%20i%20%3D%200%3B%20i%20%3C%20size%20%26%26%20result%3B%20%2B%2Bi%29%0A%20%20%7B%0A%20%20%20%20result%20%3D%20result%20%26%26%20P%28keys%5Bi%5D%2C%20values%5Bi%5D%2C%20x%29%3B%0A%20%20%7D%0A
where P() is a function taking three arguments (int, char *
and void *) and returning a bool14. We will return to the x
argument shortly, and the type void * which more or less means
“pointer to data of unknown type”, but for now think of x as
giving us the ability to pass in any extra data that P() might
need internally to perform its job. For example, if we want P()
to produce an array of booleans so we can see what (key, value)
pair did (not) satisfy P(), we could pass this array to P()
via x.
We are going to implement functions that lets a programmer express the above code like so:
bool result = ioopm_hash_table_all(ht, P, x);
bool%20result%20%3D%20ioopm_hash_table_all%28ht%2C%20P%2C%20x%29%3B%0A
Again, the x argument is an extra argument chained through all
the calls to P() performed internally in the hash table.
Similarly, we are also going to add support for checking the
existence of at least one (key, value) entry in a hash table for
which P() holds:
bool result = ioopm_hash_table_any(ht, P, x);
bool%20result%20%3D%20ioopm_hash_table_any%28ht%2C%20P%2C%20x%29%3B%0A
Like before, the x argument is an extra argument chained through
all the calls to P() performed internally in the hash table.
Both cases (all, any) pass a pointer to the function P as
argument to the hash table function. The hash table function then
proceeds to call P internally. In the “all case”, it will call
P for all entries until P returns false, at which point the
function will immediately return false. If P never returns
false, the entire function returns true. The “any case” we
apply P until it returns true in which case the entire
function immediately returns true. If P never returns
true, the entire function returns false.
On a similar note, we are also going to support applying a
function to all entries in the hash table. The following function
will call f(key, value, x) for all (key, value) pairs in the
hash table.
ioopm_hash_table_apply_to_all(ht, f, x);
ioopm_hash_table_apply_to_all%28ht%2C%20f%2C%20x%29%3B%0A
5.4.1 Function Pointers (General Information, and a Good typedef for ioopm_apply_function)
To take a function pointer as argument, the corresponding
parameter of the function must be typed as a function pointer.
Types of function pointers are a bit convoluted. Here is a
function pointer parameter whose name is fun and points to a
function that takes two integers and returns an integer: int
(*fun)(int, int). The code snippet below defines a function
call_fun() that takes a pointer to such a function as
parameters, and two integers a and b and calls the function
with a and b as arguments:
int call_fun(int (*fun)(int, int), int a, int b) { return fun(a, b); }
int%20call_fun%28int%20%28%2Afun%29%28int%2C%20int%29%2C%20int%20a%2C%20int%20b%29%0A%7B%0A%20%20return%20fun%28a%2C%20b%29%3B%0A%7D%0A
Because these kinds of parameters are hard to read, it often makes
sense to define a type name for them. For example, we can define
fun_t as the name of a type that takes two integers and returns
an integer, and use this type in the normal way to define a
parameter. Note that the body of the function is unchanged. To
call call_fun(), simply use the name of the function (without
arguments or ()) as the argument.
typedef int (*fun_t)(int, int); int call_fun(fun_t fun, int a, int b) { return fun(a, b); }
typedef%20int%20%28%2Afun_t%29%28int%2C%20int%29%3B%0A%0Aint%20call_fun%28fun_t%20fun%2C%20int%20a%2C%20int%20b%29%0A%7B%0A%20%20return%20fun%28a%2C%20b%29%3B%0A%7D%0A
For the implementation of ioopm_hash_table_all() and
ioopm_hash_table_any(), you need to visit all buckets in
whatever order you prefer and use the function pointer to call the
function you have been passed, together with the key, value and
extra argument.
These functions are very useful to implement a wide variety of
behaviour. For example checking for the presence of a certain key.
This requires the definition of a function for comparing keys. We
can call it key_equiv():
static bool key_equiv(int key, char *value_ignored, void *x) { int *other_key_ptr = x; int other_key = *other_key_ptr; return key == other_key; }
static%20bool%20key_equiv%28int%20key%2C%20char%20%2Avalue_ignored%2C%20void%20%2Ax%29%0A%7B%0A%20%20int%20%2Aother_key_ptr%20%3D%20x%3B%0A%20%20int%20other_key%20%3D%20%2Aother_key_ptr%3B%0A%20%20return%20key%20%3D%3D%20other_key%3B%0A%7D%0A
Note the signature of this function – it takes an integer, a string and a “something” – and returns a boolean. Let’s make a typedef for this:
typedef bool(*ioopm_apply_function)(int key, char *value, void *extra);
typedef%20bool%28%2Aioopm_apply_function%29%28int%20key%2C%20char%20%2Avalue%2C%20void%20%2Aextra%29%3B%0A
Now, we can check the presence of a key in a very straightforward manner:
bool ioopm_hash_table_has_key(ioopm_hash_table_t *ht, int key) { return ioopm_hash_table_any(ht, key_equiv, &key); }
bool%20ioopm_hash_table_has_key%28ioopm_hash_table_t%20%2Aht%2C%20int%20key%29%0A%7B%0A%20%20return%20ioopm_hash_table_any%28ht%2C%20key_equiv%2C%20%26key%29%3B%0A%7D%0A
One drawback of this signature is that it does not allow
exchanging the value for a different pointer. We may use e.g.
strcpy() to change value (strcpy(value, other_string)) but we
cannot make the value point to another string. One possible
solution to this problem is to add an extra pointer indirection to
value: char **. This however allows dangerous behaviour in
ioopm_hash_table_any() and ioopm_hash_table_all(). One possible
solution is to use two different function pointer types – one of
supposedly pure functions, and one where side-effects are intended.
This also let’s us drop the return type in the latter case.
This would work, for example:
typedef bool(*ioopm_predicate)(int key, char *value, void *extra); typedef void(*ioopm_apply_function)(int key, char **value, void *extra);
typedef%20bool%28%2Aioopm_predicate%29%28int%20key%2C%20char%20%2Avalue%2C%20void%20%2Aextra%29%3B%0Atypedef%20void%28%2Aioopm_apply_function%29%28int%20key%2C%20char%20%2A%2Avalue%2C%20void%20%2Aextra%29%3B%0A
Note that we do not want to give the ability to change key as
that could destroy the integrity of the hash table. For example,
if we increment a key’s value by 1, the containing entry should
also be moved to the next bucket!
The key_equiv() function shows how C allows us to go from a
pointer to something of unknown type (void *) to the actual
value pointed to. For clarity of explanation, this code was
written in three steps. Step 1 stores the address x in a
variable other_key_ptr whose type is “pointer to integer”. C will not
allow us to do *x because x does not know what it points to
(and hence not how many bytes to load on *x). Since other_key_ptr
points to an integer, we are allowed to dereference it (i.e.,
*other_key_ptr). Note if x happened to point to something else,
this code is very unlikely to crash – instead it will silently
fail by reading bits from memory and interpreting this bit
sequence as an integer. Thus, when you program with void
pointers, you have to be very careful, or things may go wrong in
bad ways. In, Step 2 we dereference other_key_ptr and store the
results in a normal integer variable. Step 3 finally compares
the two values and returns the result.
We can write this more succinctly as a single line of code using
an explicit type cast: return key == *((int *)x);. This line
temporarily changes the type of x to int * so we are allowed
to dereference it. It is just as brittle as the step-wise
solution and just as efficient.
The second, more succinct version, is the idiomatic C version. Likely a beginner C programmer might find the first version more easy to grasp but someone with a couple of months of C programming would probably find the second version more readable.
5.4.2 Finish This Step
- Implement
ioopm_hash_table_all(),ioopm_hash_table_any(), andioopm_hash_table_apply_to_all()including giving a type forioopm_apply_function. - Update your implementations of
ioopm_hash_table_has_key(), andioopm_hash_table_has_value()to useioopm_hash_table_any(). - The tests for
ioopm_hash_table_has_key()andioopm_hash_table_has_value()should work nicely as tests forioopm_hash_table_any(), but does not testioopm_hash_table_all(). Thus, write tests for the latter function, before or after implementing it, depending on your way of working. Also write a test forioopm_hash_table_apply_to_all(). - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step9.
6 Ticket #3: More, More Basic, Data Structures
The main work of this part of the assignment will be done in the
files list_linked.h, linked_list.c, iterator.h and (possibly)
list_iterator.c. We are going to build a linked list (Step 10)
and an iterator (Step 11).
6.1 Step 10: Linked Lists
The linked entries in each bucket amounts to a basic linked list. Because we do not need more than a few operations on the linked entries, we chose to give each entry a next pointer and code up the algorithms we needed from scratch. It also happens to be relatively efficient to conflate the entry and the link. Therefore, we are not going to bother refactoring the code to use the linked list instead of what we already have, in the hash table. However, because the linked list is a fundamental data structure, it pays off to have implemented one from the ground up. So that’s what we are going to do next.
Note: The linked list instructions are given in a separate document, which was not written specifically for this assignment. Thus, they are not divided into steps etc. The “Finish This Step” summary is below in this document. You may want to read about linke lists first and then go here and implement the linked list – or whatever works for you.
Following the linked list instructions in combination withe the points above, we will now switch tasks for a second, to implement a linked list. Although the instructions in the link above mention pointers to pointers, sticking with the dummy node is a fine choice. For now, we will dodge and consider only lists that store integers. (Feel free to tackle storing generic elements now if you feel up to it, but if you are new to C, better to wait.) We will undo this simplification later, but it a good initial simplification that makes things easy to test.
Here are the functions you should implement. They are reminiscent of the functions in the hash table. Stick with the same approach (test-driven, classical) as before. The kinds of reasoning that we did for the hash table works here too, e.g., there are internal functions that can serve as the building blocks of public functions, and more specific public functions can (sometimes) delegate to more general public functions.
Here are some questions to ponder:
- What is a good order to implement the functions in?
- Can some functions be used to implement the others?
- Are there some recurring operations that could be broken out into private functions?
- How should failure be handled (e.g., inserting at an invalid index)? (You may alter signatures to deal with failure in the same way we did for the hash table.) The linked list overview implements a defensive approach that lets all indexes be valid by e.g. interpreting negative indexes in some way, etc.
- How do we meet the non-functional requirements on prepend, append, and size in constant time?
Depending on your background and C proficiency, it may not be a good idea to design complete algorithms from the start. Use dodging to avoid having to deal with difficult cases from the start, etc. You can use cheating or stacking (or both), depending on whether you program in a top-down or bottom-up fashion.
#pragma once #include <stdbool.h> typedef struct list ioopm_list_t; /// Meta: struct definition goes in C file /// FIXME: better comments here /// @brief Creates a new empty list /// @return an empty linked list ioopm_list_t *ioopm_linked_list_create() /// @brief Tear down the linked list and return all its memory (but not the memory of the elements) /// @param list the list to be destroyed void ioopm_linked_list_destroy(ioopm_list_t *list); /// @brief Insert at the end of a linked list in O(1) time /// @param list the linked list that will be appended /// @param value the value to be appended void ioopm_linked_list_append(ioopm_list_t *list, int value); /// @brief Insert at the front of a linked list in O(1) time /// @param list the linked list that will be prepended /// @param value the value to be appended void ioopm_linked_list_prepend(ioopm_list_t *list, int value); /// @brief Insert an element into a linked list in O(n) time. /// The valid values of index are [0,n] for a list of n elements, /// where 0 means before the first element and n means after /// the last element. /// @param list the linked list that will be extended /// @param index the position in the list /// @param value the value to be appended void ioopm_linked_list_insert(ioopm_list_t *list, int index, int value); /// @brief Remove an element from a linked list in O(n) time. /// The valid values of index are [0,n-1] for a list of n elements, /// where 0 means the first element and n-1 means the last element. /// @param list the linked list that will be extended /// @param index the position in the list /// @param value the value to be appended /// @return the value returned (*) int ioopm_linked_list_remove(ioopm_list_t *list, int index); /// @brief Retrieve an element from a linked list in O(n) time. /// The valid values of index are [0,n-1] for a list of n elements, /// where 0 means the first element and n-1 means the last element. /// @param list the linked list that will be extended /// @param index the position in the list /// @return the value at the given position int ioopm_linked_list_get(ioopm_list_t *list, int index); /// @brief Test if an element is in the list /// @param list the linked list /// @param element the element sought /// @return true if element is in the list, else false bool ioopm_linked_list_contains(ioopm_list_t *list, int element); /// @brief Lookup the number of elements in the linked list in O(1) time /// @param list the linked list /// @return the number of elements in the list int ioopm_linked_list_size(ioopm_list_t *list); /// @brief Test whether a list is empty or not /// @param list the linked list /// @return true if the number of elements int the list is 0, else false bool ioopm_linked_list_is_empty(ioopm_list_t *list); /// @brief Remove all elements from a linked list /// @param list the linked list void ioopm_linked_list_clear(ioopm_list_t *list); /// @brief Test if a supplied property holds for all elements in a list. /// The function returns as soon as the return value can be determined. /// @param list the linked list /// @param prop the property to be tested /// @param x an additional argument (may be NULL) that will be passed to all internal calls of prop /// @return true if prop holds for all elements in the list, else false bool ioopm_linked_list_all(ioopm_list_t *list, bool (*prop)(int, void *), void *x); /// @brief Test if a supplied property holds for any element in a list. /// The function returns as soon as the return value can be determined. /// @param list the linked list /// @param prop the property to be tested /// @param x an additional argument (may be NULL) that will be passed to all internal calls of prop /// @return true if prop holds for any elements in the list, else false bool ioopm_linked_list_any(ioopm_list_t *list, bool (*prop)(int, void *), void *x); /// @brief Apply a supplied function to all elements in a list. /// @param list the linked list /// @param fun the function to be applied /// @param x an additional argument (may be NULL) that will be passed to all internal calls of fun void ioopm_linked_apply_to_all(ioopm_list_t *list, void (*fun)(int *, void *), void *x);
%23pragma%20once%0A%23include%20%3Cstdbool.h%3E%0A%0Atypedef%20struct%20list%20ioopm_list_t%3B%20%2F%2F%2F%20Meta%3A%20struct%20definition%20goes%20in%20C%20file%0A%2F%2F%2F%20FIXME%3A%20better%20comments%20here%0A%2F%2F%2F%20%40brief%20Creates%20a%20new%20empty%20list%0A%2F%2F%2F%20%40return%20an%20empty%20linked%20list%0Aioopm_list_t%20%2Aioopm_linked_list_create%28%29%0A%0A%2F%2F%2F%20%40brief%20Tear%20down%20the%20linked%20list%20and%20return%20all%20its%20memory%20%28but%20not%20the%20memory%20of%20the%20elements%29%0A%2F%2F%2F%20%40param%20list%20the%20list%20to%20be%20destroyed%0Avoid%20ioopm_linked_list_destroy%28ioopm_list_t%20%2Alist%29%3B%0A%0A%2F%2F%2F%20%40brief%20Insert%20at%20the%20end%20of%20a%20linked%20list%20in%20O%281%29%20time%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%20that%20will%20be%20appended%0A%2F%2F%2F%20%40param%20value%20the%20value%20to%20be%20appended%0Avoid%20ioopm_linked_list_append%28ioopm_list_t%20%2Alist%2C%20int%20value%29%3B%0A%0A%2F%2F%2F%20%40brief%20Insert%20at%20the%20front%20of%20a%20linked%20list%20in%20O%281%29%20time%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%20that%20will%20be%20prepended%0A%2F%2F%2F%20%40param%20value%20the%20value%20to%20be%20appended%0Avoid%20ioopm_linked_list_prepend%28ioopm_list_t%20%2Alist%2C%20int%20value%29%3B%0A%0A%2F%2F%2F%20%40brief%20Insert%20an%20element%20into%20a%20linked%20list%20in%20O%28n%29%20time.%0A%2F%2F%2F%20The%20valid%20values%20of%20index%20are%20%5B0%2Cn%5D%20for%20a%20list%20of%20n%20elements%2C%0A%2F%2F%2F%20where%200%20means%20before%20the%20first%20element%20and%20n%20means%20after%0A%2F%2F%2F%20the%20last%20element.%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%20that%20will%20be%20extended%0A%2F%2F%2F%20%40param%20index%20the%20position%20in%20the%20list%0A%2F%2F%2F%20%40param%20value%20the%20value%20to%20be%20appended%0Avoid%20ioopm_linked_list_insert%28ioopm_list_t%20%2Alist%2C%20int%20index%2C%20int%20value%29%3B%0A%0A%2F%2F%2F%20%40brief%20Remove%20an%20element%20from%20a%20linked%20list%20in%20O%28n%29%20time.%0A%2F%2F%2F%20The%20valid%20values%20of%20index%20are%20%5B0%2Cn-1%5D%20for%20a%20list%20of%20n%20elements%2C%0A%2F%2F%2F%20where%200%20means%20the%20first%20element%20and%20n-1%20means%20the%20last%20element.%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%20that%20will%20be%20extended%0A%2F%2F%2F%20%40param%20index%20the%20position%20in%20the%20list%0A%2F%2F%2F%20%40param%20value%20the%20value%20to%20be%20appended%0A%2F%2F%2F%20%40return%20the%20value%20returned%20%28%2A%29%0Aint%20ioopm_linked_list_remove%28ioopm_list_t%20%2Alist%2C%20int%20index%29%3B%0A%0A%2F%2F%2F%20%40brief%20Retrieve%20an%20element%20from%20a%20linked%20list%20in%20O%28n%29%20time.%0A%2F%2F%2F%20The%20valid%20values%20of%20index%20are%20%5B0%2Cn-1%5D%20for%20a%20list%20of%20n%20elements%2C%0A%2F%2F%2F%20where%200%20means%20the%20first%20element%20and%20n-1%20means%20the%20last%20element.%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%20that%20will%20be%20extended%0A%2F%2F%2F%20%40param%20index%20the%20position%20in%20the%20list%0A%2F%2F%2F%20%40return%20the%20value%20at%20the%20given%20position%0Aint%20ioopm_linked_list_get%28ioopm_list_t%20%2Alist%2C%20int%20index%29%3B%0A%0A%2F%2F%2F%20%40brief%20Test%20if%20an%20element%20is%20in%20the%20list%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0A%2F%2F%2F%20%40param%20element%20the%20element%20sought%0A%2F%2F%2F%20%40return%20true%20if%20element%20is%20in%20the%20list%2C%20else%20false%0Abool%20ioopm_linked_list_contains%28ioopm_list_t%20%2Alist%2C%20int%20element%29%3B%0A%0A%2F%2F%2F%20%40brief%20Lookup%20the%20number%20of%20elements%20in%20the%20linked%20list%20in%20O%281%29%20time%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0A%2F%2F%2F%20%40return%20the%20number%20of%20elements%20in%20the%20list%0Aint%20ioopm_linked_list_size%28ioopm_list_t%20%2Alist%29%3B%0A%0A%2F%2F%2F%20%40brief%20Test%20whether%20a%20list%20is%20empty%20or%20not%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0A%2F%2F%2F%20%40return%20true%20if%20the%20number%20of%20elements%20int%20the%20list%20is%200%2C%20else%20false%0Abool%20ioopm_linked_list_is_empty%28ioopm_list_t%20%2Alist%29%3B%0A%0A%2F%2F%2F%20%40brief%20Remove%20all%20elements%20from%20a%20linked%20list%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0Avoid%20ioopm_linked_list_clear%28ioopm_list_t%20%2Alist%29%3B%0A%0A%2F%2F%2F%20%40brief%20Test%20if%20a%20supplied%20property%20holds%20for%20all%20elements%20in%20a%20list.%0A%2F%2F%2F%20The%20function%20returns%20as%20soon%20as%20the%20return%20value%20can%20be%20determined.%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0A%2F%2F%2F%20%40param%20prop%20the%20property%20to%20be%20tested%0A%2F%2F%2F%20%40param%20x%20an%20additional%20argument%20%28may%20be%20NULL%29%20that%20will%20be%20passed%20to%20all%20internal%20calls%20of%20prop%0A%2F%2F%2F%20%40return%20true%20if%20prop%20holds%20for%20all%20elements%20in%20the%20list%2C%20else%20false%0Abool%20ioopm_linked_list_all%28ioopm_list_t%20%2Alist%2C%20bool%20%28%2Aprop%29%28int%2C%20void%20%2A%29%2C%20void%20%2Ax%29%3B%0A%0A%2F%2F%2F%20%40brief%20Test%20if%20a%20supplied%20property%20holds%20for%20any%20element%20in%20a%20list.%0A%2F%2F%2F%20The%20function%20returns%20as%20soon%20as%20the%20return%20value%20can%20be%20determined.%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0A%2F%2F%2F%20%40param%20prop%20the%20property%20to%20be%20tested%0A%2F%2F%2F%20%40param%20x%20an%20additional%20argument%20%28may%20be%20NULL%29%20that%20will%20be%20passed%20to%20all%20internal%20calls%20of%20prop%0A%2F%2F%2F%20%40return%20true%20if%20prop%20holds%20for%20any%20elements%20in%20the%20list%2C%20else%20false%0Abool%20ioopm_linked_list_any%28ioopm_list_t%20%2Alist%2C%20bool%20%28%2Aprop%29%28int%2C%20void%20%2A%29%2C%20void%20%2Ax%29%3B%0A%0A%2F%2F%2F%20%40brief%20Apply%20a%20supplied%20function%20to%20all%20elements%20in%20a%20list.%0A%2F%2F%2F%20%40param%20list%20the%20linked%20list%0A%2F%2F%2F%20%40param%20fun%20the%20function%20to%20be%20applied%0A%2F%2F%2F%20%40param%20x%20an%20additional%20argument%20%28may%20be%20NULL%29%20that%20will%20be%20passed%20to%20all%20internal%20calls%20of%20fun%0Avoid%20ioopm_linked_apply_to_all%28ioopm_list_t%20%2Alist%2C%20void%20%28%2Afun%29%28int%20%2A%2C%20void%20%2A%29%2C%20void%20%2Ax%29%3B%0A
The initial steps were very small in comparison with this step, but this step does not really include anything we have not done before. See it as exercising the exact same elements as before, but on a slightly simpler data structure. A few more words before you get going:
- Avoid copy-pasting code! (Do you know why?)
- Following good naming principles, including naming public
function
ioopm_, etc. - Format your code nicely. You could even use a tool like
astyleorindent15, or, in Emacs’C-x hto mark the entire buffer followed byM-x indent-region.
6.1.1 Finish This Step
- Implement all the functions listed in the header file.
- Extend the documentation with how you deal with failures and all other assumptions or caveats. You are allowed to change function signatures when needed for failure handling (and support for storing elements of any type).
- Write at least basic tests, before or after implementing it, depending on your way of working.
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step10.
6.2 Step 11: Iterators
An iterator is an important concept that reifies the action of visiting all elements in a structure in some predefined order. An iterator typically allows visiting all elements and removing elements. An introduction to iterators that builds on the linked list page can be found here.
To support iterators, we want to extend the list with the ability to create an iterator. Thus, such a function must be added to the public list interface:
/// @brief Create an iterator for a given list /// @param the list to be iterated over /// @return an iteration positioned at the start of list ioopm_list_iterator_t *ioopm_list_iterator(ioopm_list_t *list);
%2F%2F%2F%20%40brief%20Create%20an%20iterator%20for%20a%20given%20list%0A%2F%2F%2F%20%40param%20the%20list%20to%20be%20iterated%20over%0A%2F%2F%2F%20%40return%20an%20iteration%20positioned%20at%20the%20start%20of%20list%0Aioopm_list_iterator_t%20%2Aioopm_list_iterator%28ioopm_list_t%20%2Alist%29%3B%0A
The implementation of the iterator should follow the header file
iterator.h. Note that if you have implemented a generic list
(that can store elements of any type), you will need to change the
below interface accordingly.
Like with the hash table and list, you will need to adapt the
header file below to handle errors. What happens if
ioopm_iterator_current() is called before the first call to
ioopm_iterator_next()? How do we handle too many calls to
ioopm_iterator_next()? How are changes to the list’s size
triggered through ioopm_iterator_remove() tracked in the list?
What happens with the list’s last pointer if
ioopm_iterator_remove() is used to remove the last link of the
list with respect to the lists’s last pointer? Lots of
interesting cases to ponder!
/// @brief Checks if there are more elements to iterate over /// @param iter the iterator /// @return true if bool ioopm_iterator_has_next(ioopm_list_iterator_t *iter); /// @brief Step the iterator forward one ste /// @param iter the iterator /// @return the next element int ioopm_iterator_next(ioopm_list_iterator_t *iter); /// @brief Remove the current element from the underlying list /// @param iter the iterator /// @return the removed element int ioopm_iterator_remove(ioopm_list_iterator_t *iter); /// @brief Insert a new element into the underlying list making the current element it's next /// @param iter the iterator /// @param element the element to be inserted void ioopm_iterator_insert(ioopm_list_iterator_t *iter, int element); /// @brief Reposition the iterator at the start of the underlying list /// @param iter the iterator void ioopm_iterator_reset(ioopm_list_iterator_t *iter); /// @brief Return the current element from the underlying list /// @param iter the iterator /// @return the current element int ioopm_iterator_current(ioopm_list_iterator_t *iter); /// @brief Destroy the iterator and return its resources /// @param iter the iterator void ioopm_iterator_destroy(ioopm_list_iterator_t *iter);
%2F%2F%2F%20%40brief%20Checks%20if%20there%20are%20more%20elements%20to%20iterate%20over%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0A%2F%2F%2F%20%40return%20true%20if%0Abool%20ioopm_iterator_has_next%28ioopm_list_iterator_t%20%2Aiter%29%3B%0A%0A%2F%2F%2F%20%40brief%20Step%20the%20iterator%20forward%20one%20ste%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0A%2F%2F%2F%20%40return%20the%20next%20element%0Aint%20ioopm_iterator_next%28ioopm_list_iterator_t%20%2Aiter%29%3B%0A%0A%2F%2F%2F%20%40brief%20Remove%20the%20current%20element%20from%20the%20underlying%20list%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0A%2F%2F%2F%20%40return%20the%20removed%20element%0Aint%20ioopm_iterator_remove%28ioopm_list_iterator_t%20%2Aiter%29%3B%0A%0A%2F%2F%2F%20%40brief%20Insert%20a%20new%20element%20into%20the%20underlying%20list%20making%20the%20current%20element%20it%27s%20next%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0A%2F%2F%2F%20%40param%20element%20the%20element%20to%20be%20inserted%0Avoid%20ioopm_iterator_insert%28ioopm_list_iterator_t%20%2Aiter%2C%20int%20element%29%3B%0A%0A%2F%2F%2F%20%40brief%20Reposition%20the%20iterator%20at%20the%20start%20of%20the%20underlying%20list%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0Avoid%20ioopm_iterator_reset%28ioopm_list_iterator_t%20%2Aiter%29%3B%0A%0A%2F%2F%2F%20%40brief%20Return%20the%20current%20element%20from%20the%20underlying%20list%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0A%2F%2F%2F%20%40return%20the%20current%20element%0Aint%20ioopm_iterator_current%28ioopm_list_iterator_t%20%2Aiter%29%3B%0A%0A%2F%2F%2F%20%40brief%20Destroy%20the%20iterator%20and%20return%20its%20resources%0A%2F%2F%2F%20%40param%20iter%20the%20iterator%0Avoid%20ioopm_iterator_destroy%28ioopm_list_iterator_t%20%2Aiter%29%3B%0A
It is important to ponder where should the code for the iterator live. If we put it in a file of its own, that is good for keeping files smaller and easier to navigate, etc. – but given that the list’s structure is internal to the list, we must somehow break encapsulation to allow an iterator to navigate the list freely. You can solve this by moving the iterator’s code into the list, to make a copy of the link struct in the iterator file, move the shared parts into a non-public header file shared by the list and the iterator, etc. Pick a solution that works and think about how this relates to (or even demonstrates) key concepts in the course like modularity, encapsulation, coupling and cohesion.
6.2.1 Finish This Step
- Implement all the functions listed in the header file.
- If needed – extend the documentation with how you deal with failures and all other assumptions or caveats. You are allowed to change function signatures when needed for failure handling (and support for storing elements of any type).
- Write at least basic tests, before or after implementing it, depending on your way of working. One crude but working way to tests the implementation is to reimplement existing functions in the list using the iterator in a way that exercises all the functions in the iterator interface.
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step11.
7 Ticket #4: Refactoring and Improvements
In this step, we are going to polish the hash table and the linked list and make a few changes and general improvements:
- Make small changes that moves us closer to typical C code (Step 12)
- Use the linked lists in the utility functions of the (Step 12)
- Allow storing arbitrary data in the linked list and in the hash table (Step 13)
- Add a hash function to the hash table (Step 13)
- Run basic performance tests (Step 14)
- Check in the final code and write the final documentation (Step 15)
Note: some of these changes will be optional.
7.1 Step 12: Refactoring of Hash Table and Linked List
7.1.1 Use the size_t Data Type Instead of int in the Right Places
So far, we have used the int data type to store integers. For
various reason, this data type has different sizes on different
platforms. Quoting the Wikipedia article on C data types:
[An int is a basic] signed integer type. Capable of containing at least the \([−32,768, +32,767]\) range; thus, it is at least 16 bits in size.
The current C standard defines multiple integer data types (for
example), which have invariant size across all platforms. For
example, an int32_t is always 32 bits and is therefore capable
of containing the \([−2,147,483,648, +2,147,483,647]\) range. On the
computer on which I am editing this document right now, int32_t
is a type alias of int, i.e., it is defined using typedef as
int (because int is 32 bits on this machine). It is perfectly
fine to use int etc. types in your programs, but beware that
they might mean different things. If you know you are not going
to iterate over more than 32 thousand elements, int is a fine
choice. When in doubt, use int32_t, int64_t etc.
The size_t type is an unsigned integer (i.e., only contains
positive numbers) and is used in many places in the standard libraries, for example to represent the size of C object
(including arrays). The sizeof() macro that we have used several
times already, for example, returns value of type a size_t.
Your task is to change usages of integer types in our
programs where the int refers to a size. Keys for example,
should stay int (those are not sizes, and moreover are only a
placeholder). However, the return from ioopm_hash_table_size()
clearly reflects a size, and so we should change that to a
size_t. Carefully inspect the functions and change your types
accordingly16.
7.1.2 Use the Linked List to Return the Keys for a Hash Table
The ioopm_hash_table_keys() function returns an array of keys.
Change the function so that it returns a linked list instead,
using your linked list from before.
One could argue that the returning an array is more performant, but the linked list offers a richer interface, not to mention support for both internal and external iterators. Since the internal representation of the list is not visible externally, it would not be hard to offer an alternate list implementation backed by an array (generally referred to as an array list). (This would be an ambitious way to demonstrate e.g., modularity and encapsulation.)
Your task is to change the return type of ioopm_hash_table_keys() to
ioopm_list_t * and update the function’s implementation
accordingly. Updating the function to use the list
interface instead of the array should be straightforward. Spend a
few minutes (not more) thinking about the time complexity, and
what order the keys should be in the list according to the
specification (or more correctly – documentation).
7.1.3 Optional: Const Annotations
Note that this bit is optional. The C const qualifier provides a
way to indicate that a value will not (or shall not) change. For
example, the strncpy(dst, src, n) function that copies n bytes
from the string src to the string dst has the signature char
*strncpy(char *dest, const char *src, size_t n). The const
qualifier here means that strncmp() only needs read capabilities
for src, in other words, it rescinds the rights the write src,
meaning that an attempt inside strncpy() to do e.g., src[42] =
'!' will not compile because that violates constness. So, not
only does const communicate something to the a client to
strncmp(), it helps the implementer capture their intention
with respect to not writing to src, and then helps enforcing
that intention.
Your (optional) task is to add the const qualifier to all
functions. Do it piece by piece. You can start bottom-up (e.g.,
change in internal functions and have it propagate) or top-down
(e.g., start from the interface, using an understanding of how
functions should behave).
const qualifiers could be used to demonstrate Achievement G15.
7.1.4 Finish This Step
- Make the required (and, optionally, optional) changes above:
refactor to use
size_tand return a list of keys instead of an array (and optionally addconstqualifiers). Don’t forget to update header files too. - Extend the documentation to match changes.
- Update the tests to adapt to the changes, before or after the changes are implemented, depending on your way of working.
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step12.
7.2 Step 13: Supporting Arbitrary Data as Elements, Keys and Values
Achievement E10 is related to this step.
As you were looking at the text on linked lists, you may have
scrolled all the way down to the section Adding Genericity that
deals with how to support lists that can hold arbitrary data. Now,
time has come to change both the list and the hash table to store
arbitrary data. We will follow the trick in the text on linked
lists and have each element (in the case of the list), key and
value (in the case of the hash table) be a union of the possible
element types, henceforth referred to as elem_t. (This union
is very similar to answer_t in the C bootstrap labs.) There is
a definition of elem_t you can use here.
Function pointers are going to be stored inside the list and hash table structs and be passed in as arguments to the constructors, which will be discussed shortly.
Since C does not have run-time type information, we cannot query a union for its type. This means that the list cannot compare to unions for equality, because it does not know what to compare (and thus not how). This means that the user needs to supply one or more function pointers to the data structures for operations on unions. For example, if a list contains strings (i.e., the union holds a string pointer), a function pointer that compares strings is needed to implement the contains function.
If we are sticking with the two function pointer types from before,
here is how to update them to work with elem_t instead of int and
char * (or char **).
typedef bool (*ioopm_predicate)(elem_t key, elem_t value, void *extra); typedef void (*ioopm_apply_function)(elem_t key, elem_t *value, void *extra);
Note that when we change the list to support generic types, we are going to break the code of the hash table – because it uses the linked list to return all keys. Leave this for now, since we are going to update the hash table too.
As you move through this fairly invasive (although not so big) change in the code base, it is interesting to ponder how the compiler can be of help! We have dependencies, e.g. the hash table depends on the linked list as we have seen, and if you have used the iterator in any of your implementations, you have a dependency on the iterator. When we make changes to types and signatures, the compiler is going to complain. If we “compile all the things”, then we are not going to be able to get a clean compile until all the things have been updated to a stable state. If we instead identify the leaves of the dependency tree, we can fix isolated things and have them compile, so that the list of errors the compiler tells us to fix stays manageable throughout. (For example, you can begin with updating the iterator to support generic data, or simply update its header file when you work on the list.)
It is important to learn how to use the compiler to weed out bugs! Compiler errors are meant to be helpful (and are – as soon as you learn how to understand the compiler’s way of expressing itself). However, if make a habit out of living with warnings17 etc. when you compile, it will be hard to spot the real errors.
Please read or skim all subsections below before you get to work.
7.2.1 Where Does elem_t belong?
It is interesting to ask the question where the definition of elem_t
should be placed. If both iterator.h and hash_table.h includes
linked_list.h, it would seem that it would suffice to define elem_t
in linked_list.h. However, there seems to be a number of recurring
definitions across several data structures, and it would be good
from a modularisation standpoint (why!?) to break the dependency
chain. To this end, define a header file common.h for all common
and basic definition that we can reuse. This file should contain
at least elem_t, but it also makes sense to place function
pointer types here as well. It makes sense to have uniformly named
function pointer types for e.g., comparing two elem_t’s and
returning a bool etc., any, all, etc.
For example, stdlib.h defines the type __compare_fn_t thus:
typedef int (*__compar_fn_t) (const void *, const void *);
This type is thus defined everywhere where stdlib.h is included.
Soon we will be adding a hash function type. Then you will have to think in similar ways: where does it’s function type belong?
7.2.2 Pass Function Pointers to the List’s Constructor
Rather than forcing the programmer to pass in function pointers, we will store the necessary function pointers in the list at creation time. Look through the list and see what operations that requires operating on (e.g., comparing, but not storing or returning, elements) – and define function pointer types for these, e.g.,
/// Compares two elements and returns true if they are equal typedef bool(*ioopm_eq_function)(elem_t a, elem_t b);
%2F%2F%2F%20Compares%20two%20elements%20and%20returns%20true%20if%20they%20are%20equal%0Atypedef%20bool%28%2Aioopm_eq_function%29%28elem_t%20a%2C%20elem_t%20b%29%3B%0A
Put this type definition in the linked_list.h header file and extend
ioopm_linked_list_create() to take an extra argument of type
ioopm_eq_function and store that in the ioopm_list_t object, beside first, last, etc..
Note that this requires a change to the constructor signature,
both in the header file and in the .c file. Alternatively, we
could rely on the aforementioned __compare_fn_t (and not use or
define ioopm_eq_function) noting that this will lose what little
type information we have.
7.2.3 Using Function Pointers to Operate on Elements
With the above change(s) in place, we can update
ioopm_link_list_contains() to use the function stored in the
list to compare its elements.
Follow the same procedure for all other functions – if any that needs to change in a similar way for the list to support generic elements. This may require further updates to the constructor, etc.
Note that functions that already take function pointer arguments (before this step) should stay that way.
7.2.4 Update the Iterator
As we update the list, we are going to need to update the iterator accordingly. This is a very quick fix! Do it now so we can forget it.
7.2.5 Update the Hash Table to Support Generic Data
We can now update the hash table to support generic data following
exactly the same procedure as for the list, but with one
difference – we also need to add a hash function. The hash
function is the function that takes a key, and returns an integer
hash code for the key that allows us to map the key to a bucket.
So far, we dodged this bullet, and pretended that all keys were
integers. To support generic keys, the key type changes from int
to elem_t, and bucket selection uses the hash function (passed
in as argument to the constructor and stored
in the hash_table_t). Note that we do not need to store a key’s
hash code in the hash table – since we can always compute it
using the key and the hash function if we were to need the hash
code again. Some example hash functions are further down in this
document. (You can look at those to extract a good function
pointer type to use in the constructor.)
You can allow a user of the hash table to not supply a hash
function for example if all keys are integers (i.e., the elem_t
values passed as keys contain integers). This can be implemented
either by using an if-statement, e.g., something like this:
if (ht->hash_function == NULL) { // treat keys as integers int_key = key.i; // .i reads the integer part of the elem_t } else { int_key = ht->hash_function(key); }
if%20%28ht-%3Ehash_function%20%3D%3D%20NULL%29%0A%20%20%7B%0A%20%20%20%20%2F%2F%20treat%20keys%20as%20integers%0A%20%20%20%20int_key%20%3D%20key.i%3B%20%2F%2F%20.i%20reads%20the%20integer%20part%20of%20the%20elem_t%0A%20%20%7D%0Aelse%0A%20%20%7B%0A%20%20%20%20int_key%20%3D%20ht-%3Ehash_function%28key%29%3B%0A%20%20%7D%0A
Alternatively, you can define a function that simply returns the
integer value from a elem_t and store that function in the hash
table unless the user provides another. (This happens only once,
per constructor.) That way you can always rely on the existance of
a hash function in ht->hash_function in subsequent functions,
which simplifies the code above greatly – especially good if it
is repeated many times:
int_key = ht->hash_function(key);
int_key%20%3D%20ht-%3Ehash_function%28key%29%3B%0A
An bonus of this trick is that your existing tests should more of less keep working as-is, since they are all written with integers as hash table keys.
int extract_int_hash_key(elem_t key) { return key.i; // following a very terse naming scheme -- improve? }
int%20extract_int_hash_key%28elem_t%20key%29%0A%7B%0A%20%20return%20key.i%3B%20%2F%2F%20following%20a%20very%20terse%20naming%20scheme%20--%20improve%3F%0A%7D%0A
7.2.6 Update ioopm_hash_table_values() to Return a Linked List
Before, we were able to use the linked list to return all the keys
in the linked list but not the values. This was because the values
were not integers and the list only supported integer elements.
This is no longer a problem, so go ahead and update
ioopm_hash_table_values() to return a list just like
ioopm_hash_table_keys().
7.2.7 Finish This Step
- Change the type of elements, keys and values to
elem_tin the signature of functions (including constructors) and in structs. - Create
common.hand populate it with suitable type definitions and declarations (including a typedef for the hash function). - Extend the appropriate constructors to take in the necessary function pointers. In particular, add a hash function argument to the hash table constructor.
- Change the
ioopm_hash_table_values()function to return a list. - Update all tests to pass in the proper functions and to handle
elem_t’s instead of e.g., integers or strings. - Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code into the appropriate GitHub repos. Tag your
commit with
assignment1_step13.
7.3 Step 14: Performance Testing
Let’s put our hash table to use!
We are going to write a simple program that reads zero or more files, and counts the frequencies of the words in these files. A typical output of such a program will be in the form of:
$ ./freq-count file1 file2 word1: frequency1 word2: frequency2 ... word3: frequency
where output is lexicographic order on the keys.
We are going to use a hash table to store the data, such that words (string) will be our keys, mapping to integer values that represent the number of times the key word has appeared in the file.
If you are feeling stressed to finish, you can grab a copy of
this almost finished freq-count.c to start you off! (Otherwise,
it is good to write the code yourself. Read the section below to
understand what the code does.)
7.3.1 A Top-Down Approach
Imagine that we already have all the words that we want to count. In this case, a central function is going to be the one that adds words to the hash table. Here is some Python pseudo code for this function – if there is an entry for word, increment its value by one. If there is no entry for word, add an entry and give it an initial count of one. Like so:
def add_or_increment(ht, word): if word in ht.keys(): ht[word] += 1 else: ht[word] = 1
def%20add_or_increment%28ht%2C%20word%29%3A%0A%20%20if%20word%20in%20ht.keys%28%29%3A%0A%20%20%20%20ht%5Bword%5D%20%2B%3D%201%0A%20%20else%3A%0A%20%20%20%20ht%5Bword%5D%20%3D%201%0A
Python hides the application of the hash function and provides a hash function for strings. In C, we are less lucky. However, see below for a discussion of string hash functions.
A good way to test your program is to write this function and call it with a bunch of known words and then simply write a test that asserts that the words you passed to the hash table were counted properly, e.g., something like this (adapted to your way of error handling).
elem_t key = (elem_t) { .key = "Captain Beefheart" }; bool success; elem_t result = ioopm_hash_table_lookup(ht, key, &success); assert(success); /// assuming we have put the good captain 3 times into the hash table assert(result.i == 3);
elem_t%20key%20%3D%20%28elem_t%29%20%7B%20.key%20%3D%20%22Captain%20Beefheart%22%20%7D%3B%0Abool%20success%3B%0Aelem_t%20result%20%3D%20ioopm_hash_table_lookup%28ht%2C%20key%2C%20%26success%29%3B%0Aassert%28success%29%3B%0A%2F%2F%2F%20assuming%20we%20have%20put%20the%20good%20captain%203%20times%20into%20the%20hash%20table%0Aassert%28result.i%20%3D%3D%203%29%3B%0A
We are going to have to print our results. Given that we are printing keys in lexicographic order, this will require some thought. Note that neither keys nor values are ordered in the hash table, but that we can get a list of all the keys and a list of all the values such that they are ordered in the same way. Solving this problem is left to you!
So, if we know how to add words, and how to print words, the
question remains how to get words. It turns out that C has a
very nice library function for this called strtok(), that
operates on a string in memory. A careful reading of man strtok
should give you what you need. Note that strtok() will destroy
the string you are operating on! Further, note that each call to
strtok() will return a pointer into the string it is tokenizing,
meaning that once you have a word that you want to store as a key
in the hash table, you will want to make a copy of the word (e.g.,
using strdup() from before).
In the man page for strtok(), delimiters are all characters that
can appear as delimiters to words, like “,.?!\n” etc. So, if we
have the text in a string, we can use strtok(). The remaining
question is how to get a file into a string.
Opening a file for reading happens like so: FILE *in =
fopen("/path/to/file", "r");. To read a string from a ~FILE *, we
can use getline(): char *result = NULL; result =
getline(&result, 0, in);. This reads one line in the file in.
To close a file when you are done, simply do fclose(in).
Now we can construct a nice high-level algorithm for this program:
1. Create an empty hash table
2. For each file argument, read each word in the file
2.1 If the word is not in the hash table
2.1.1 Put it there, and give it the value 1
2.2 Otherwise
2.2.1 Increments its current value by 1
3. Print the outputs in lexicographic order on the keys
4. Tear down the hash table, free all resources, close all files
(Note that step 3 will require a separate algorithm for the order to be correct, which will add complexity.)
Hints: C provides a fast way to sort all keys in lexicographic
order if they are stored in an array of pointers to strings
through the qsort() function. Another simple way is to code up a
quick and dirty binary tree.
7.3.2 Profiling our Program
This step is closely related to Achievement O42 and Achievement O43 (at least).
Start by thinking a bit about where your program spends the most time. What would you guess? Let’s find out!
Profiling is a technique for understanding how programs behave at
run-time by looking at what a program does. There are different
kinds of profiling tools. Some are based on sampling and
interrupts the program at regular intervals (typically in the
microsecond range) and records information such as what function
was executed at that point, etc. Tracing is an alternative
approach where a program is extended by additional instructions
that report its activities. Feel free to explore profiling
in-depth (after the course)! For now, we are going to be content
with one of gprof, perf or valgrind (please use the links as
starting points to learning about these tools). (Other OS’s have
other tools, like Instruments.app on macOS.)
To develop an execution profile, we are going to run the program on some files of various shapes and sizes. To save you some time cooking those up, you can get such files here.
Run your program on each input file and inspect the result. Answer the following questions.
- For each input, what are the top 3 functions?
- For each input, what are the top 3 functions in your code18, or is it library functions?
- Are the top 3 functions in your code consistent across the inputs? Why? Why not?
- Is there some kind of trend? (Possibly several.)
- Do the results correspond with your expectations?
- Based on these results, do you see a way to make your program go faster?
Write down the answers as a note in the README.md file in the
directory parallel to the files and check it into your GitHub
repository. Use # Initial Profiling Results as the heading. Feel
free to be very brief but make sure you can come back to these
notes in 10 weeks and still understand them as well as you
understand them now. Also note down how the numbers were obtained.
You can use the tool time to test your program’s performance
thus: time ./prog input. That produces output like so:
./freq_count 10k-words.txt 0,65s user 0,01s system 98% cpu 0,670
total This means that it took 0.67 seconds to run the program
from start to finish, out of which 0.65 seconds were spend in the
program’s code and 0.01 seconds in calls to operating system
functions. That the program got 98% of a CPU means that one CPU
was running the program almost all the time in that 0.67 seconds
– if that number had been 50%, the total time would have been
doubled, because the program only ran half of the time.
When you run time to test if an optimisation paid of, you should
ideally run the program many times and pick e.g. the 5 best out of
10 to avoid measuring jitter in the system. Also think about the
input you are using – more input means longer run-time which
is more resilient to jitter. Also think about what input to use
that exercises the functions you are interested in. Ideally, the
input should also be representative for the program so we are
optimising under as real conditions as possible.
Example, using the --verbose flag to also see e.g., memory
consumption:
stw:inlupp1/ (master✗) $ /usr/bin/time --verbose ./freq_count freq-count-files/10k-words.txt
Command being timed: "./freq_count freq-count-files/10k-words.txt"
User time (seconds): 0.86
System time (seconds): 0.00
Percent of CPU this job got: 98%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.87
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 1812
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 90
Voluntary context switches: 1
Involuntary context switches: 18
Swaps: 0
File system inputs: 0
File system outputs: 16
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
7.3.3 Adapting the Number of Buckets
The performance of a hash table is highly dependent on the size of the buckets. For example, if a hash table has 17 buckets and 1700 elements, then – under uniform distribution – we are going to have on average 100 entries per bucket, meaning that each lookup will have to search 100 entries (worst-case).
Ideally, from a performance (speed, not memory) standpoint, a hash table should have no more than a single entry per bucket. To keep a hash table performant in a program with dynamic load, it is common to construct hash tables so that they have an initial capacity (i.e., number of buckets from the start) and a load factor which is a threshold for when to grow the number of buckets. A load factor of 0.5 means that when we reach 9 elements in a hash table with 17 buckets, we grow the number of buckets to reduce the risk of having more than one entry per bucket. A common heuristic for growing capacities is to double them when they are exhausted (or a threshold reached). Because we rely on modulo to map keys to buckets, it is often recommended to use a prime number as the number of buckets. Imagine if we have numbers 1, 11, 21, … up to 1491. This will give us the following distributions with 16 respective 17 buckets:
| bucket | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| entries | 0 | 18 | 0 | 18 | 0 | 18 | 0 | 17 | 0 | 18 | 0 | 18 | 0 | 17 | 0 | 18 |
| bucket | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| entries | 8 | 8 | 8 | 8 | 8 | 7 | 8 | 8 | 7 | 8 | 8 | 8 | 8 | 8 | 8 | 7 | 8 |
Create a second constructor for hash tables that allows
constructing a hash table with a specified initial capacity and
load factor. The normal constructor for hash tables (i.e.,
ioopm_hash_table_create()) can simply delegate to the second
constructor with a load factor of 0.75 and an initial capacity
of 17. For simplicity, we don’t support shrinking the number of
buckets. Note that C does not support overloading, so the two
constructors must have different names.
Operations that may grow the hash table in size must check if the
load factor is reached. In that case, we increase the capacity
of the hash table. This means that No_buckets must be demoted
from the static capacity to the initial capacity and that the hash
table must hold its capacity in a field. Changing the number of
buckets includes rehashing, which means that we must recalculate
the hash value for each element and take it modulo the new
capacity. The complexity involved in rehashing means that it is a
good idea that the size roughly doubles (i.e., increases
exponentially rather than linearly) so we do not need to repeat
this costly operation so often.
It is a good idea to factor out the growth check and the actual growth and rehashing in a single function that gets called early in operations that may grow the hash table, so that they can always proceed with that already taken care of.
Feel free to look at e.g., the Dynamic Resizing section in
Wikipedia’s Hash table article for other ideas. A good way to grow
the capacity of an array allocated using calloc() is through the
realloc() (or reallocarray() if you turn on _GNU_SOURCE)
function.
It is not uncommon that a hash table implementation includes some kind of precomputed table of prime number sizes to quickly find the next size to grow. The below figure provides such a table (for small sizes) that you can use if you want.
size_t primes[] = {17, 31, 67, 127, 257, 509, 1021, 2053, 4099, 8191, 16381};
size_t%20primes%5B%5D%20%3D%20%7B17%2C%2031%2C%2067%2C%20127%2C%20257%2C%20509%2C%201021%2C%202053%2C%204099%2C%208191%2C%2016381%7D%3B%0A
OPTIONAL – BUT READ THIS!
Note that with a design like this, that makes each bucket only hold a few entries, the overhead of having one dummy node per bucket gets pretty big.
We can remove the dummy nodes by using the double pointer trick
used for the linked list: rewrite find_previous_entry_for_key()
to return a entry_t ** – a pointer to the pointer to the
entry we are looking for (which may be NULL or another entry,
just like with find_previous_entry_for_key()). This requires
a name change to the function, which is cheap because it is
not public.
With this change, the buckets array becomes the type entry_t
*buckets[], and each pointer in buckets[] gets initialised to
NULL.
Fixing this is a great opportunity to do the memory optimisation achievement.
7.3.4 Hash Function for Strings and Other Objects
As we have discussed previously – a hash function gives a stable interpretation of a datum as an integer. There is no single best-fit, and the same hash function may perform differently in different cases. Wikipedia’s article on hash functions is a good starting place to explore this concept further than what we do on this course.
A very simple way of hashing a string is to simply summarise the values of its characters:
unsigned long string_sum_hash(const char *str) { unsigned long result = 0; do { result += *str; } while (*++str != '\0'); return result; }
unsigned%20long%20string_sum_hash%28const%20char%20%2Astr%29%0A%7B%0A%20%20unsigned%20long%20result%20%3D%200%3B%0A%20%20do%0A%20%20%20%20%7B%0A%20%20%20%20%20%20result%20%2B%3D%20%2Astr%3B%0A%20%20%20%20%7D%0A%20%20while%20%28%2A%2B%2Bstr%20%21%3D%20%27%5C0%27%29%3B%0A%20%20return%20result%3B%0A%7D%0A
This is simple enough but will assign equal codes to strings built from the same characters in different order. More importantly, if key strings are not very long, they are likely to have a fairly small range.
A better approach is to compute a polynomial whose coefficients are the ASCII values of the individual chars.
The implementation of the hash function for strings in Java is a good and fast solution that produces larger numbers (note that overflow is not a problem) and uses prime numbers to decrease the likelihood of collisions:
unsigned long string_knr_hash(const char *str) { unsigned long result = 0; do { result = result * 31 + *str; } while (*++str != '\0'); return result; }
unsigned%20long%20string_knr_hash%28const%20char%20%2Astr%29%0A%7B%0A%20%20unsigned%20long%20result%20%3D%200%3B%0A%20%20do%0A%20%20%20%20%7B%0A%20%20%20%20%20%20result%20%3D%20result%20%2A%2031%20%2B%20%2Astr%3B%0A%20%20%20%20%7D%0A%20%20while%20%28%2A%2B%2Bstr%20%21%3D%20%27%5C0%27%29%3B%0A%20%20return%20result%3B%0A%7D%0A
Note that the integer keys that we used for the hash table initially could also need hashing if the ranges of the integers is very small, or there are predicable gaps in the data. As we are looking to populate hash tables, we want hashcodes of datums to be fairly uniformly distributed.
To produce a hash code for say a person with a name, age, and
gender, we can simply consider these things together. For example,
we could take the sum of the hash for the name and the age and
gender values interpreted as integers. The same reasoning for sums
as above apply. Moreover – consider the effect of using mutable
data as keys! If object o is used as a key and subsequently
changes, will we be able to find it again if we look it up? (Here
the optional const annotations from before could be handy –
still optional though.)
7.3.5 Optional: Optimising the Hash Table
Note that this bit is optional. You may have noted that getting the keys in the hash table includes iterating over a number of buckets, and iterating over a linked structure in each bucket, to create one big linked list of keys. In the words of Brian Wilson, wouldn’t it be nice if we could somehow “just” stitch together the separate bucket lists into a single list, and return that.
Actually, instead of NULL terminating each bucket, we could have
a single linked list serving all the buckets, where, logically,
a subsequence of all the links belongs to a specific bucket. There
are several schemes to make this work. Ideally, we would be able
to use the existing linked list implementation. If each bucket
holds its starting index in the linked list, inserting into a
bucket would e.g. create an iterator, then move the necessary
number of steps forward, and then step and check the key value
until we reach the end of the bucket, or an entry with a larger
key and use the insert function of the iterator. While simple –
this is a terrible idea because it slows down all insert and
lookup operations, which are common, to optimise a less used
operation. A more interesting idea is to have each bucket point to
the previous bucket’s last entry – this works nicely, but this
breaks the encapsulation of the linked list. Also, inserting a new
last entry of a bucket will become a bit more convoluted. Yet
another approach is to have several dummy entries in the linked
list, one for each bucket, and have each bucket point to these,
plus a special iterator (etc.) that knows how to skip over the
buckets correctly.
Try drawing your optimised representation and use insert and remove in the hash table to drive the implementation.
Furthermore (or alternatively), now that we are growing the size of the hash table dynamically to keep buckets small, does it make sense to keep entries in a bucket ordered? How we do find out? (By measuring of course – but on what data set?) If we could retire some complexity in the insert function (or any function), we have simplified maintenance of this code which is great for the future.
This step should give you what you need to do the two first profiling and optimisation achievements.
7.3.6 Finish This Step
- Implement the program that uses the hash table according to its (loose) specification.
- Run the program with input of varying sizes, and produce execution profiles for the program runs. What are the 10 most time-consuming functions? Are they consistently the same? Or are there functions that e.g. seem to run a lot slower if there is a little more data?
- Implement the self-adapting logic that tunes the number of buckets.
- Experiment with various load factors – how does that impact the profiling results in 2.?
- Think about how you can test the self-tuning logic! What does that require us to do or know in our test programs? Implement a test for the growing of the number of buckets.
- Make sure that your code compiles with the appropriate flags turned on. Preferably using a Makefile.
- Run your tests through Valgrind. Preferably using a Makefile.
- Make sure that the code passes your tests.
- Check your code and the profiling results into the appropriate
GitHub repos. Tag your commit with
assignment1_step14.
7.4 Step 15: Wrapping Up
This concludes the first assignment. WELL DONE!
The following header files show what you should have implemented – with some slight modification e.g. to handle errors and other design decisions or optional tasks. Note that the header files only show the public functions not any internal functions and structs described in the text above.
By now you should have demonstrated a few achievements, or at least have accumulated enough insights to be able to demonstrate. For example, in addition to the one’s hinted above, you likely grasp and have evidence for demonstrating Achievement J26 and Achievement J27, possibly also Achievement D9 – as long as you’ve gone above and beyond what’s been handed out. You probably have code related to Achievement M36. Some error handling options are related to Achievement M38. Your unittests – regardless of what approach you followed – should get you at least one of the Q achievements. If you used Emacs diligently, then you’re likely good to demonstrate Achievement T55 (if not more).
Experience shows that different students approach the achievement system in different ways: some like to interleave working and demonstrating, and some like to first finishing an assignment and then extracting the achievements to demonstrate from the finished program. What way of working that works best for you is up to you.
As part of your way of getting here, you have written some tests. To measure how much of your code your tests actually execute, we can use a coverage tool, like gov. A coverage tool will tell you, in varying ways depending on how it is implemented, tell you what lines of code your tests run, and/or what paths in the control flow that are covered. For example, imagine that you have a complex nested conditional – it is easy to miss executing all combinations of branching, e.g., true followed by false, false followed by false, etc. (or more complicated). As part of this final step, run a code coverage tool (hint, gcov is installed already, but feel free to try something more fancy) and construct a code coverage report for your files. If you use gov, you can easily add Lcov to your tool chain (alternative guide) to produce a much more appealing visual code coverage report.
Knowing the code coverage of your test is important – it gives us some high-level knowledge about the quality of the tests. Since code and tests will evolve, we are likely going to want to generate these numbers time and again. To that end, automate the procedure and stick it in your Makefile.
7.4.1 Finishing the Assignment
- Go over your backlog of cheats and dodges and see which ones need taking care of. Ideally this stack should be empty.
- Write up the documentation of your program, documenting e.g.
how failure is handled, any assumptions you are making about
how your data structures are used, etc. Put this in a
README.mdin the top-level directory for this assignment. - As the first section of
README.md, add instructions for how to build and run the tests for the program in Step 14. Ideally, this should be as easy asmake test. In this section, also state the line coverage and branch coverage per.cfile and what tool you used to obtain these numbers. - Prepare a demonstration of z100 to give at the next lab. In addition to z100, pick another 2-3 achievements to tick off, and include these in your demonstration preparation. To back up your presentation, present evidence like places in your code where relevant things show up, documentation, paper drawings, etc. – things that support your demonstration. Think carefully about what things fit together (ask for help if you feel uncertain after trying) and what achievements tell a good story together. Make sure that not one person dominates the demonstration or answers all questions to avoid someone failing the demonstration because there was no evidence of achievements mastery.
- Send an email to z100@wrigstad.com with your names and usernames, a link to the GitHub repository where the code can be checked out.
- Create a final commit for the assignment and check it into
GitHub. Tag the commit with
assignment1_done. - Optional Please take time to feedback on the assignment.
Note: Don’t expect any feedback on your program over what you have got from the oral presentations. If you want more feedback on specific things, ask questions in conjunction with your presentations, or add your name to the help list.
Questions about stuff on these pages? Use our Piazza forum.
Want to report a bug? Please place an issue here. Pull requests are graciously accepted (hint, hint).
Nerd fact: These pages are generated using org-mode in Emacs, a modified ReadTheOrg template, and a bunch of scripts.
Ended up here randomly? These are the pages for a one-semester course at 67% speed on imperative and object-oriented programming at the department of Information Technology at Uppsala University, ran by Tobias Wrigstad.
Footnotes:
string.h that provide a
battery of functions for string manipulation, or stdio.h which
provide standard functions for I/O – input and output – from a
program.# are
preprocessor macros, which are handled automatically before
compilation. The macro #pragma once prevents a header file from
being included more than once in a program, which usually leads to
the compiler complaining about identically named things being
defined more than once.valgrind on
a very recent release of macOS, you are not likely to see this.
Instead, you will see warnings and errors listed in things
outside of your program. Solution: run valgrind on the
department’s Linux machines, or run valgrind through
Vagrant.indent -nut -gnu -npsl -i2 file.c to
get the same code format as Tobias.size_t to only talk
about byte sizes of objects, you can use e.g. unsigned int, or
why not something like uint32_t for e.g., the number of objects
in a list