Linked Lists
Table of Contents
1 Introduction
Structs and arrays are allocated in consecutive memory – the
array int[16] occupies 16 * sizeof(int) bytes of memory.
Arrays are efficient because lookup can be performed in constant
time for any given element, but the cost to insert or remove is
much higher, as it involves shifting elements “left” or “right” in
memory to make space for a new element or to remove the space
occupied by an element.
In contrast to arrays, linked structures are constructed by many smaller elements connected by pointers, very much like a graph. Construction of a linked structure therefore (typically) requires several discrete memory allocations and pointer manipulations.
In this text, we are going to construct one of the simplest linked structures – a linked list. We will approach this task incrementally, first solving simple problems (sometimes under assumptions that simplify the current task), and slowly arrive at something solid. There is no single listing that you can copy-paste and run with – instead you should follow along with the design, and make some contributions of your own.
Inserting an element into an array (typically) means calculating where to store the element in a preallocated space. In contrast, inserting an element into a linked list (typically) means creating a new place (a new link) where the element can be stored and searching for the right place in the linked structure where the new place (link) should be added.
Here are the public functions from the header file list.h.
We will add more further down in this document.
/// Creates a new list list_t *list_new(); /// Deletes a list. void list_delete(list_t *list); /// Inserts a new element at the beginning of the list void list_prepend(list_t *list, elem_t element); /// Inserts a new element at the end of the list void list_append(list_t *list, elem_t element); /// Inserts a new element at a given index. void list_insert(list_t *list, int index, elem_t element); /// Returns the element at a given index elem_t list_get(list_t *list, int index); /// Removes an element from a list. bool list_remove(list_t *list, int index); /// Returns the length of the list. int list_length(list_t *list);
2 Approach
A first stab at a linked list could look like this. For good
reasons, we define a type elem_t to be the element type,
and for now, make the element type an int.
/// An element typedef int elem_t; /// A link in the linked structure typedef struct link link_t; struct link { elem_t element; link_t *next; };
Note that link_t is a recursive data type. A link_t may hold a
pointer to another link_t in next, or next may point to
NULL.
Creating a linked structure with the above definitions is as
simple as allocating several link_t’s and linking them
together, meaning having them point to each other through their
next fields1.
link_t *link1 = malloc(sizeof(struct link)); link_t *link2 = malloc(sizeof(struct link)); link_t *link3 = malloc(sizeof(struct link)); link1->next = link2; link2->next = link3; link3->next = NULL;
This creates the structure shown in Figure 1.
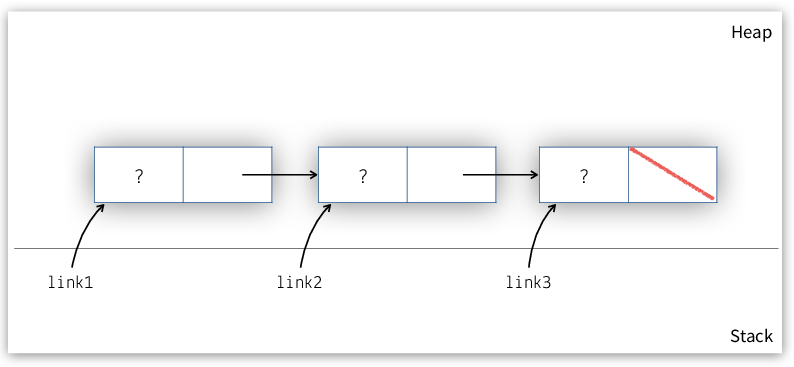
Figure 1: Vanilla-style linked list with three links.
The auxiliary variables link2 and link3 are not strictly
necessary – we could create the same structure like
this:2
link_t *link1 = malloc(sizeof(struct link)); link1->next = malloc(sizeof(struct link)); link1->next->next = malloc(sizeof(struct link)); link1->next->next->next = NULL;
However, as is clearly visible above, this gives us no direct way
to get to the last next field, forcing us to build chains of
next->next->....
3 Constructor for Links
A link_t currently holds an element field and a next field.
The above code examples left the element fields undefined, which
is (almost) never a good idea. Let’s define a constructor for
links to make sure that links are fully initialised.
link_t *link_new(elem_t element, link_t *next) { link_t *result = malloc(sizeof(struct link)); if (result) { result->element = element; result->next = next; } return result; }
By using link_new() instead of simply using malloc() like
before, the C compiler will force us to supply values for
element and next. This means that we can rely on these fields
having reasonable values3.
3.1 Aside: Coding Conventions
On the course, we use a coding convention where constructors for a
type t are named t_new. Furthermore, our constructors will
always initialise all fields of the objects – either by taking
an argument, like in the case for link_new(), or defaulting to
0, 0.0, false or NULL4.
This is a nice convention, because it allows us to talk about
t_new for any given t with an immediate clear semantics.
Furthermore, we will (unless there are good reasons not to do so) order the arguments to the constructor in the same order as the fields in the struct we are creating. This rule of thumb can be questioned, but is meant to encourage smart grouping of both fields and constructor arguments.
3.2 Aside: Functional Abstraction
With the constructor in place, it is possible to create instances
of structures – in this case links – without knowing how the
links are specified internally. Essentially, the constructor
promises this: “If you give me an element, and a pointer to
another link, I’ll give you back a pointer to a link”. Naturally,
we cannot know from just looking at the signature link_t
*link_new(elem_t, link_t *) that we get back a fresh link (but
the name of the method certainly hints at that), nor do we know
that the new link will have the supplied element and link pointer
as element and next. In the cases where it makes sense, such
details should be added as documentation, preferably where the
function prototype for the function in question is placed,
which is commonly in a header file (for a public function).
Rewriting the code above using the new constructor results in
much cleaner code. Here is the first code example, now with
integer elements. Note that the line setting link3->next to
NULL is gone, because we can rely on this by construction.
link_t *link1 = link_new(1, NULL); link_t *link2 = link_new(2, NULL); link_t *link3 = link_new(3, NULL); link1->next = link2; link2->next = link3;
We can even rewrite the code like this, which may not be more
readable (except possibly in the case for a very small number of
links). Remember that C evaluates arguments from the inside out,
meaning link_new(3, NULL) will be executed first and the result
passed to link_new(2, _) in the place of the _.
link_t *link1 = link_new(1, link_new(2, link_new(3, NULL)));
4 A First Stab at Prepending
Inserting elements at the head of a list is simple, as can be illustrated by the following code:
link_t *my_list = ...; /// Some list my_list = link_new(42, my_list); /// Prepend 42 to the list
What is scary about this code is that the identity5 of the list gets lost in the process, forcing us to
update my_list with the result. If we forget to store the result
in my_list, the update to the list is lost, and the compiler
will not warn us. Programming like this in an imperative language
often leads to aliasing problems and forces propagating changes
in the system. For example, imagine a function that takes a list
and wants to prepend to it:
bool some_function(list_t *list) { list = link_new(42, list); /// Prepend 42 to the list return ...; /// return something } link_t *my_list = ...; /// Some list some_function(my_list);
The code above suffers from the same problem as before! Inside
some_function() the list gets updated through the list
variable, but the change is not visible through my_list which
still points to the same link, which is the second link in the
list according to list but first according to my_list.
This can be solved by returning list:
list_t *some_function(list_t *list) { list = link_new(42, list); /// Prepend 42 to the list return list; } link_t *my_list = ...; /// Some list my_list = some_function(my_list);
Sadly, this forces us to remove the bool return value from
before. What is even more sad – if we forget to store the result
of some_function() to my_list, we have a bug which might prove
tricky to find.
Another solution to the problem is to share the variable at the call-site, instead of its contents:
/// Take a pointer to the variable holding the list bool some_function(list_t **list) { *list = link_new(42, *list); /// Prepend 42 to the list return ...; /// return something } link_t *my_list = ...; /// Some list some_function(&my_list); /// Note -- value of my_list /// changes as a side-effect
Now, my_list is updated as a side-effect of calling
some_function(), but if we had two variables pointing to
the same list, we are back with the same problem again.
The solution lies is changing how we represent lists, and will
introduce another type in the list data structure, which we will
call “the list head” – list_t:
typedef struct list list_t; struct list { link_t *first; };
For now, the list head contains a pointer to the first link in the list. This pointer may change, but there is never a need to create more than one list head for the same list. The resulting structure is shown in Figure 2.
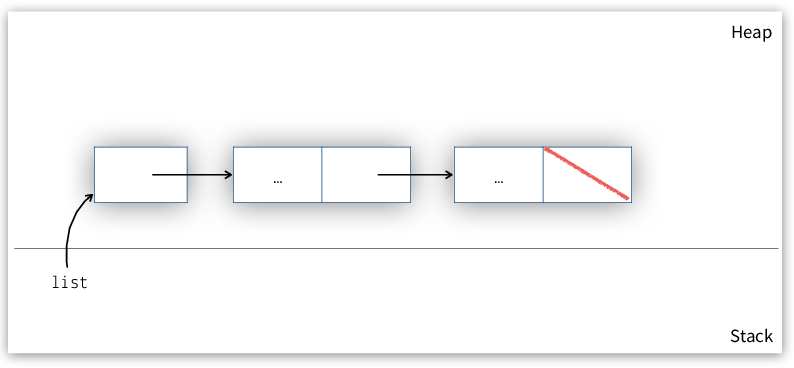
Figure 2: Linked list with separate list head.
We are now ready to write a first working list_prepend():
void list_prepend(list_t *list, elem_t element) { list->first = link_new(element, list->first); }
The beauty of this function is that it operates on the list head
– and the list head is always the same, regardless of how the
list changes. As is visible from the above, prepending to a list
list changes the value of list->first, but list stays the
same. We can now write the code for creating a list much nicer
than before, using a combination of functions whose names give us
a good idea of what they do, but hide how they do it.
list_t *list = list_new(); /// Constructor for the list list_prepend(list, 3); list_prepend(list, 2); list_prepend(list, 1);
To highlight that the identity of the list is preserved, let us
create an alias6 to list and use both to call list_prepend(). This
code creates the equivalent list as in the code block just above.
list_t *list = list_new(); /// Constructor for the list list_t *same_list = list; /// Create an alias for list called same_list list_prepend(list, 3); list_prepend(same_list, 2); list_prepend(list, 1);
Since prepend always inserts elements first in the list, we must
add the elements in reverse order. Note how this matches the
evaluation order of the calls to link_new() in Listing 2.
4.1 Aside: Making Lists Opaque
Notice how the list operations above all work on an object of type
list_t – there is no longer a mention of link_t. This is
excellent, because it allows us to hide the implementation
details of the list. Whether a list is implemented with a chain
of links (like in our case here), an array, or something else
should not matter to a user of the list7. Later in the implementation of the
list, we will specify the list’s public interface – essentially
what goes into the header file list.h. Private parts of the
list, will only be visible in list.c, including both the link
struct and the link_t type.
We will mark private functions with the static keyword to make
sure they cannot be linked against by external code.
5 A First Stab at Appending
Prepending, as we have seen, is simple and straightforward –
especially after introducing a new list_t struct to act as a
front-end to the chain of links. Appending – insertion at the
back of a list – is a tiny bit more complicated in the current
setup, because we must first search for the last element before
we can update its next field to point to a new link.
Here is a first attempt8
at writing an append function for lists. We introduce a local
variable cursor that points to a link_t and “swing this
pointer forward” through the chain of links until it reaches a
link whose next field is NULL. Once we have a pointer to this,
last, link, we can simply update its next field to point to a
new link whose next field is NULL.
void list_append(list_t *list, elem_t element) { link_t *cursor = list->first; while (cursor->next != NULL) { cursor = cursor->next; } cursor->next = link_new(element, NULL); }
SPOILER The reason why this code is faulty is because it does not handle the case when the list is empty. When the list is empty,
cursorwill beNULL, and testingcursor->next != NULLwillSEGFAULT. A straightforward way to handle this case is to test for this condition specially and, for example, call prepend which handles this perfectly.
A perhaps less obvious aspect of the code above is the linear time
complexity. In order to find the last link, we must follow all
but the last next pointers in the list.
Luckily, aliasing – the same concept that brought us trouble when
we took an initial stab at writing list_prepend() – can help us
here. To allow constant time append operations, we extend list_t
with a last pointer in addition to the first pointer. Here is
the new list_append() which also deals with appending to an
empty list.
void list_append(list_t *list, elem_t element) { /// Check if the list is empty if (list->last == NULL) { /// Append on an empty list is same as prepend list_prepend(list, element); } else { /// Insert element at the end of the list link_t *link = link_new(element, NULL); list->last->next = link; /// Update the last pointer to point to the new last element list->last = link; } }
Note that list_prepend() must change to update the last pointer
when inserting into an empty list.
void list_prepend(list_t *list, elem_t element) { link_t *link = link_new(element, list->first); /// If list is empty, make the new element the last element if (list->first == NULL) { list->last = link; } list->first = link; }
Getting rid of the loop not only makes the code faster, it also made the code much simpler.
6 Removing Elements
Removing elements from a list requires unlinking them from the chain. Consider unlinking the second element from the list in Figure 3.
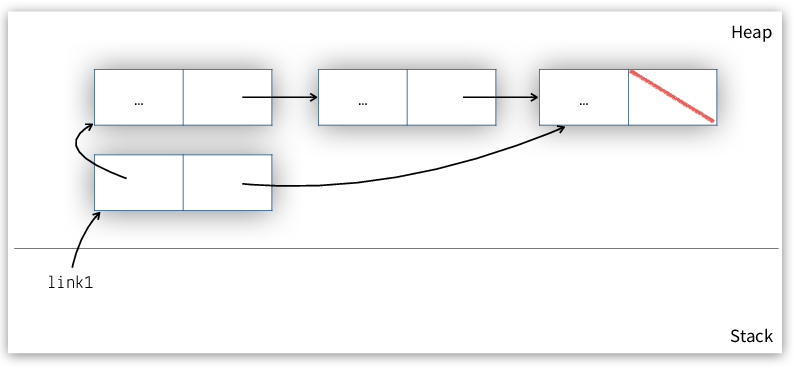
Figure 3: Linked list with three elements.
After unlinking, link1->next points to link3, as shown in Figure 4.
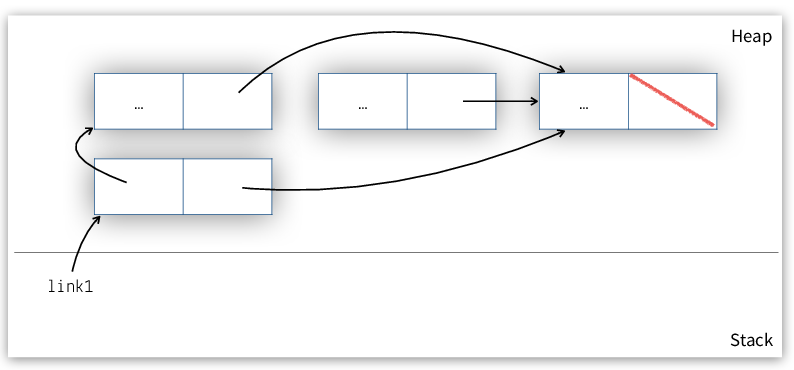
Figure 4: Linked list with two elements, after unlinking the second element.
As is visible above, unless we explicitly nullify link2->next,
it too will point to link3, making link1->next and
link2->next aliases. However, since our plan is to get rid of
link2, we do not really care about the value of link2->next.
Subsequent to the unlinking we will return the memory for link2
to be reused, as indicated by the gree tag in Figure 5.
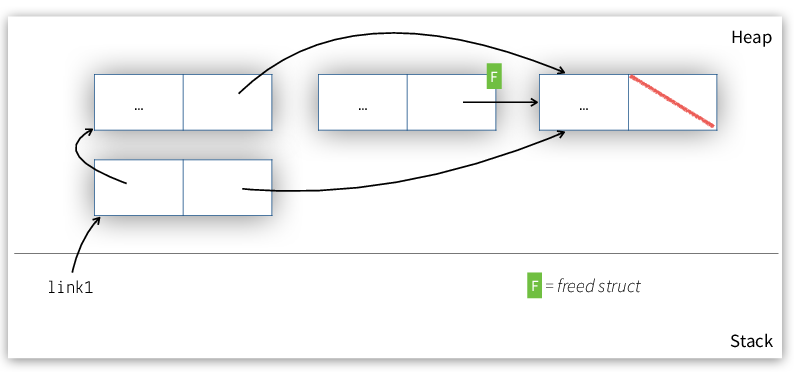
Figure 5: After freeing the unlinked link.
Consider a function void list_remove(list_t *list, int index),
which, given a valid9 index into a list, will remove the element
associated with that index from the list. As per usual with C, the
first element’s index will be 0. Thus, list_remove(list, 1)
would unlink the second element, like in the sketches above.
The implementation of list_remove() will resemble the first
sketch of list_append() – as usual in a linked structure, we
must search for the n:th link to be deleted. As we noted above,
unlinking a link means changing the preceeding link’s next.
Thus, as we search for the link to remove, we want to stop on
the link just before.
Simplifying a little further, let us assume that the function is
never called with index == 0. In that case, the following will
do the trick:
void list_remove(list_t *list, int index) { link_t *cursor = list->first; /// Note index - 1 to stop on the preceeding node for (int i = 0; i < index - 1; ++i) { cursor = cursor->next; } link_t *to_remove = cursor->next; /// Save pointer to link cursor->next = to_remove->next; /// unlink link free(to_remove); /// return memory for link }
The reason why the function above does not handle index == 0 is
similar to why our first list_append() did not work on an empty
list. Concretely, there is no way to get a pointer to the link
preceeding the first link. Thus, the algorithm above is not
general enough to cover all cases.
Instead of solving this by adding a special case for when index is
0, let’s consider another way of solving the problem – by
adapting the data structure to match the algorithm. This is a
time-honoured tradition, and serves to make code cleaner and
simpler at the cost of some memory overhead10. Instead of defining an empty list like a list whose
first and last are both NULL, we can add a special “sentinel
object” (aka “dummy link”) and define an empty list as one whose
first and last both point to this object. Figure 6
shows an empty list with a sentinel.
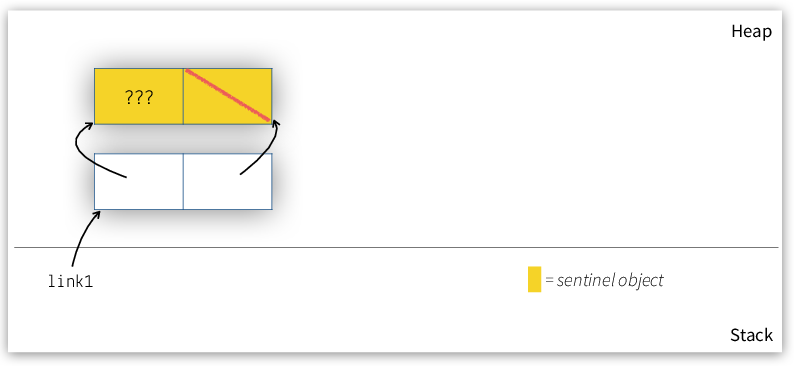
Figure 6: Empty list with a sentinel.
With this definition of the empty list, the list_remove()
that we wrote above, works perfectly also when index == 0!
Figure 7 shows what a list with two elements look like when using a sentinel.
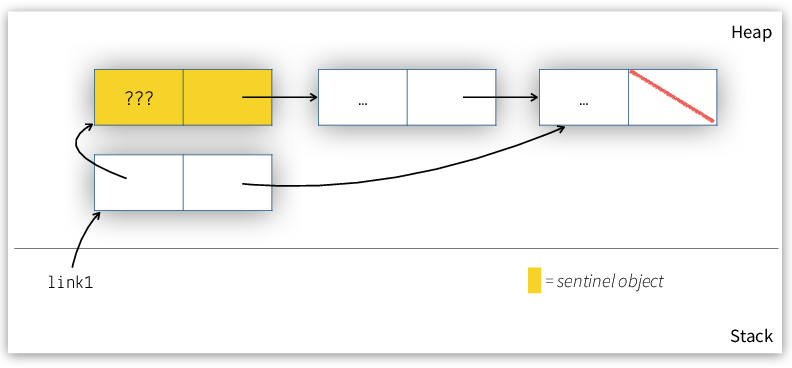
Figure 7: List with a sentinel and two elements.
Of course, this change also requires us to update the other functions that we have written:
list_new()must create the sentinel objectlist_prepend()must skip over the sentinel objectlist_append()can be simplified thanks to the sentinel object
We now perform those changes in order and list the resulting code.
list_t *list_new() { list_t *result = malloc(sizeof(struct list)); if (result) { /// Use of calloc will ensure result->first->next == NULL result->first = result->last = calloc(1, sizeof(struct link)); } return result; }
void list_prepend(list_t *list, elem_t element) { link_t *link = link_new(element, NULL); /// If list is empty, make the new element the last element if (list->first == list->last) /// CHANGE: new way to check for empty list { list->last = link; } list->first->next = link; /// CHANGE: skip over sentinel }
void list_append(list_t *list, elem_t element) { list->last->next = link_new(element, NULL); }
Note that the last three changes do not constitute a refactoring step – they are not improving how already correct code performs a task. Without these changes, the code would not be correct. If we had started with a working list remove, we could consider the addition of the sentinel (and the corresponding changes to remove, append, prepend and new) a refactoring step.
As a last exercise in dealing with sentinels, we can build
list_size(), which calculates the size of the list by counting
the number of links skipping the sentinel:
int list_size(list_t *list) { int size = 0; for (link_t *cursor = list->first->next; cursor; cursor = cursor->next) { ++size; } return size; }
Later, we shall revisit this function to see how it can be written in a way that amortises the cost of checking size over several functions.
7 Accessing Elements
So far, we have functions for creating a new list, inserting
elements at the end and at the back, and removing elements at a
given index. Now it is time to add functions for accessing
elements with list_get().
Getting the elements at index i is similar to removing elements
– we must get a pointer to the i:th link (not counting the
sentinel) and use this pointer to read the element field. As a
first stab, we can write a function that assumes the index
argument is valid.
elem_t list_get(list_t *list, int index) { link_t *cursor = list->first->next; /// Skipping over the sentinel for (int i = 0; i < index; ++i) { cursor = cursor->next; } return cursor->element; }
Note that index logic is non-trivial – we allow negative
indexing, and reinterpret indexes which are too small or too big.
Furthermore, index adjustment comes up in several places in the
code. These two reasons suggest that it is sensible to build a
single function to handle this logic that can be called from many
places. It also serves to make the code easier to read. For now,
let us cheat and assume the existance of a function
list_inner_adjust_index(a, b) that is able to (somehow)
translate an index a to a valid index in the range [0-b).
To adhere to the principle of always having a running program,
we define a stub which simply echoes back the given index,
but with a /// TODO marker in the source, which will prompt
us to go back and fix it later.
int list_inner_adjust_index(int index, int upper_bound) { return index; /// TODO! }
With this function in place, list_get() no longer needs to
dodge index handling:
elem_t list_get(list_t *list, int index) { link_t *cursor = list->first->next; /// Skipping over the sentinel int valid_index = list_inner_adjust_index(index, list_size(list)); for (int i = 0; i < valid_index; ++i) { cursor = cursor->next; } return cursor->element; }
8 Inserting Elements at Any Valid Index
Appending and prepending elements is useful, but given that lists
are ordered sequences, it makes sense to support insertion of
elements at any valid index. For this purpose, list’s interface
contains the function list_insert(list_t *list, int index, elem_t
element). Notably, prepending is inserting at index 0. Likewise,
appending to a list of size n is insertion at index n. Thus,
with list_insert() in place, we should be able to rewrite
list_prepend() and list_append() thus:
void list_prepend(list_t *list, elem_t element) { list_insert(list, 0, element); } void list_append(list_t *list, elem_t element) { list_insert(list, list_size(list), element); }
This list_append(), while simple, suffers from a regression –
the cost of appending suddenly went from O(1) to O(elements).
We mark this with a /// TODO <appropriate explanation> and keep
going for now. After all, the list still works.
Implementing list_insert() is reminiscent of list_remove() and
list_get() – we must iterate over the list to find the place of
insertion. Given that we are coming up on the third time of
implementing this logic, surely there must be some way to extract
it into a function of its own?
Let us define the function list_inner_find_previous() that,
given a pointer to the first link in a chain of links and an index
i, traverses the chain to get to link i-1. A function that
finds the previous link is more generally useful as it supports
both unlinking and getting the i:th link by simply taking one
more step in the chain. Note that this function is possible to
write because of the sentinel. Without it, we would not have been
able to get a pointer to the link preceeding the first
link11.
link_t *list_inner_find_previous(link_t *link, int index) { link_t *cursor = link; for (int i = 0; i < index; ++i) { cursor = cursor->next; } return cursor; }
With this function in place, it is possible to define list_insert()
in a straightforward manner. Again, we make use of list_inner_adjust_index(),
but note how we add 1 to the upper bound, so that we are able to position
ourselves on the last link, so that the result of writing the next field
is an append.
void list_insert(list_t *list, int index, elem_t element) { int valid_index = list_inner_adjust_index(index, list_size(list) + 1); link_t *prev = list_inner_find_previous(list->first, valid_index); prev->next = link_new(element, prev->next); }
This code is wondefully straightline and operates at a high-level, making
it almost as readable as natural language. From the index supplied as
argument, create a valid index upper-bounded by the list’s size plus one.
Then, find the node before this new index, and replace its next node
with a new node, whose next field points to the old next.
9 Refactoring Step
Let us now back up and update list_remove() and list_get() to
use the helper function list_inner_find_previous(). Like insert,
they will be simplified by removing the iteration step.
void list_remove(list_t *list, int index) { int valid_index = list_inner_adjust_index(index, list_size(list)); link_t *prev = list_inner_find_previous(list->first, valid_index); link_t *to_remove = prev->next; prev->next = to_remove->next; free(to_remove); } elem_t list_get(list_t *list, int index) { int valid_index = list_inner_adjust_index(index, list_size(list)); link_t *prev = list_inner_find_previous(list->first, valid_index); return prev->next->element; }
Even though the refactoring step was prompted by the realisation
that some functions could/should be rewritten to take advantage of
some new functionality, we should search the code for /// TODO
markers to see if anything warrants fixing. Since we are not in
the middle of implementing some functionality, we might as well
spend a few minutes on backlog and get
list_inner_adjust_index() up and running. This is left as an
exercise for the reader.
We also have a /// TODO regarding list_append(). There are
(at least) two ways to fix this:
- Revert to the previous implementation that used
list->last. - Add a special case to
list_inner_find_previous()that jumps directly tolist->lastwhenindex == upper_bound.
Arguments can be made as to what solution is preferable. Make up your own mind, and apply the fix!
10 Deleting Lists
So far we are missing the dual function of list_new() –
list_delete(). Just as we use a standard naming convention for
constructors, we name destructors for objects of type t
t_delete(). Destructors are very tricky to get right in
languages like C that use manual memory management because we
must answer the question “what to delete”. For example, if
elem_t was not an int but char * – should deleting a list
of strings delete all the strings in the list as well? There is no
one true answer to this question as it wíll vary on a case by case
basis12.
Since elem_t is defined as int, we get to dodge this issue
(for now). However, we still need to be able to delete an entire
list.
The right way to implement list_delete() is by reusing the logic
we already implemented in list_remove(). This function removes a
link for a given index, and frees up memory. Intuitively, to
delete a list with n entries, we need to make n calls to
list_remove(), and then free the list head itself.
Here is a first stab13
void list_delete(list_t *list) { while (list_size(list) > 0) { list_remove(list, 0); } free(list); }
At a first glance, this seems like perfectly valid code but if we
compile our program and run it through valgrind, the tool will
report a leak of calloc’d memory in list_new().
Both list_size() and list_remove() are public functions that
(for good reasons) do not expose the existance of the sentinel.
The fix is simple, simply add free(list->first) on the 2nd-last
line of the function above to delete the sentinel before deleting
the list head.
void list_delete(list_t *list) { while (list_size(list) > 0) { list_remove(list, 0); } free(list->first); /// Free the sentinel free(list); }
11 Adding Genericity
Because C is such a low-level language, writing generic data structures in C is a lot of work. We will now change the list so that it is able to store arbitrary values.
The first step is to redefine elem_t. If we wanted lists to only
hold pointers of some kind, we could define elem_t as void *,
but to allow lists with primitive data, we will make elem_t a
union:
typedef union elem elem_t; union elem { /// TODO: update the names of the fields to something better? int i; unsigned int u; bool b; float f; void *p; /// other choices certainly possible };
Now, a list knows that it is reading and writing elements of type
elem_t, but the client for each list must keep track of what is
actually stored inside the elem_t’s.
To allow the list to operate on its elements, we will rely on
function pointers supplied by the programmer. Consider for
example the function list_contains() which checks if an element
is a member of a list. If the list does not know the type of its
elements – how can it compare them?
Let us now define a function to do so, in the same style as
strcmp() – the string comparison function. strcmp(a,b)
returns 0 when a and b are equal, a number <0 if a comes
before b in lexicographic order, and >0 if b comes before
a in lexicographic order. For integers, this is easy to implement
by simply returning b - a14.
int compare_int_elements(elem_t a, elem_t b) { return b.i - a.i; }
To simplify passing this function in as argument to
list_contains(), we define a type, cmp_fun_t. The syntax for
doing so is arguably one of the darkest corners of C:
typedef int(*cmp_fun_t)(elem_t a, elem_t b);
We are now ready to write list_contains(). This function is
relatively straightforward – iterate over the links and apply
the function to all elements until the result is 0, which means
the element is found, and return true. If we manage to reach the
end of the list without finding the element, we return false.
bool list_contains(list_t *list, elem_t element, cmp_fun_t cmp) { for (link_t *cursor = list->first->next; cursor; cursor = cursor->next) { if (cmp(cursor->element, element) == 0) return true; } return false; }
11.1 Another Example: list_apply()
Iterating over all elements in a collection and applying some
function to them is a common operation. The same logic as in
list_contains() can be re-applied but with an additional
argument so that a user can pass some additional data to each
operation. Like with list_contains(), we use typedef to
specify the signature of functions that can be passed to
list_apply().
typedef void(*action_fun_t)(elem_t element, void *data);
With this type, we are ready to write the function, which is really quite simple:
void list_apply(list_t *list, action_fun_t fun, void *data) { for (link_t *cursor = list->first->next; cursor; cursor = cursor->next) { fun(cursor->element, data); } }
To give an idea of how someone might use this in a program, let us
reimplement list_contains() using list_apply(). To do so, we
must fist specify a struct to hold all the relevant data – the
element we are searching for, a pointer to the function used to
compare elements, and a boolean flag that keeps track of whether
we found the element.
struct found_data { elem_t element; cmp_fun_t cmp; bool found; };
We then write a function to be used with list_apply() that uses
our struct to perform element comparison and update the found flag
if the element is found.
void found(elem_t element, struct found_data *data) { if (data->found == false && data->cmp(element, data->element) == 0) { data->found = true; } }
We can now implement list_contains() in terms of list_apply().
While this may seem nice, note that because list_apply() always
goes through the entire list, so will list_contains() even if we
found the element we were looking for first in the list. Also, the
logic (at least when expressed like this in C) is less
straightforward than the original implementation. Nevertheless, if
the list did not contain list_contains() but list_apply(),
this is how a client of the list could easily roll her own
list_contains() without having to know anything about the
internal representation of the list.
bool list_contains(list_t *list, elem_t element, cmp_fun_t cmp) { struct found_data d = { .element = element, .cmp = cmp, .found = false }; list_apply(list, (action_fun_t) found, &d); return d.found; }
12 Refactoring Step
Let us now go back and change the list so that list_size()
becomes a constant time operation. We do this by amortising the
cost of keeping track of the number of elements in the list across
all calls to functions that add or remove elements.
First, we add a size field to struct list. Because we used
malloc() and not calloc() to create a new list, we need to
update list_new() to intialise size with 0. We really should
have been using calloc() in list_new() in the first place.
This way, any addition to the struct would become initialised to
zero automatically, which feels a lot more future proof. Thus,
the new list_new() becomes:
list_t *list_new() { list_t *result = calloc(1, sizeof(struct list)); /// CHANGE: malloc => calloc if (result) { result->first = result->last = calloc(1, sizeof(struct link)); } return result; }
Next, we add list->size += 1 to all functions that insert elements
and list->size -= 1 to all functions that delete elements.
Because of our previous refactorings, any insertion falls back on
list_insert(). That means that if suffices to put list->size +=
1 there and only there15. There is only a single function
that removes elements, so the only list->size -= 1 goes in
list_remove().
Now, the size field will change as a side-effect of inserting or
removing elements. This allows us to implement list_size() like so:
int list_size(list_t *list) { return list->size; }
Seeing as list_size() is a function called by many other functions
in the list implementation, the performance of this function is really
crucial for the overall performance of the list.
13 Recap
In the end, we have arrived at a solid implementation of a linked list.
13.1 Iterating Through Design Steps
We ended up with a design that favours simple code – at the cost
of one extraoneous link per list. It will be hard to find a
reasonable program where this trade-off does not make sense. The
extra link allowed us to write the function
list_inner_find_previous() which we use extensively internally.
This makes the code easier to change and maintain, including
searching for bugs.
Note that we did not magically arrive at this design. It was a step-wise refinement (iterative) process in which we started with something much simpler.
Figure 8: Initial design.
This was enough to implement a working prepend, but we quickly realised a need to improve the code to deal with aliasing.
Figure 9: After adding a list head.
The second design dealt with aliasing, but the cost of appending was
(still) huge, so we added a last pointer in list.
Figure 10: Extending list head with a last pointer.
It was only following the last change that we decided to change the data structure to use a sentinel. Following this change, we ended up with the final design, shown in Figure 11.
Figure 11: List with list head, last pointer and sentinel.
13.2 Encapsulation and Information Hiding
By only making the head of the list visible to a user, we manage
to hide the internal implementation details of the list. For
example, changing the list to use arrays internally is perfectly
possible, without making this change visible to code that uses our
list. To this end, our public functions only deal with list_t,
never with link_t, and so the typedef of link_t along with the
definition of struct link can (and should) be moved from the
public header file list.h into list.c. But we are not done –
the definition of struct list should also be moved into list.c
or the existance of link_t will still be visible
(Also, the program will not compile – can you see why? Because the compiler does not know the type link_t after the typedef was moved.)
13.3 Support for Elements of Any Type
To get going, we started out by defining a type for the elements,
elem_t. This made it simple to change the element type by simply
replacing the typedef, and also served as a reminder to ourselves
that we should not rely on the element type internally.
Before the discussion of genericity, the only use of the elem_t
type was to calculate how many bytes to store in a link_t, and
how many bytes to read and write to load and store elements. After
introducing function such as list_contains(), this still holds.
The only manipulations of elements which interpret the data in
any way happen in functions supplied externally through function
pointers. Thus, they are not technically part of the list’s
implementation.
Questions about stuff on these pages? Use our Piazza forum.
Want to report a bug? Please place an issue here. Pull requests are graciously accepted (hint, hint).
Nerd fact: These pages are generated using org-mode in Emacs, a modified ReadTheOrg template, and a bunch of scripts.
Ended up here randomly? These are the pages for a one-semester course at 67% speed on imperative and object-oriented programming at the department of Information Technology at Uppsala University, ran by Tobias Wrigstad.
Footnotes:
element fields undefined!element
fields undefined!calloc() instead of malloc() to allocate structures.list_append() by reverting to an
implementation that was not based on list_insert(), you need to
increase list->size in list_append() too.