Assignment 2 (Phase 1, Sprint 2)
Table of Contents
- 1. Simple Webstore Backend
- 2. The Frontend
- 2.1. Actions
- 2.1.1. Add Merchandise
- 2.1.2. List Merchandise
- 2.1.3. Remove Merchandise
- 2.1.4. Edit Merchandise
- 2.1.5. Show Stock
- 2.1.6. Replenish
- 2.1.7. Create Cart
- 2.1.8. Remove Cart
- 2.1.9. Add To Cart
- 2.1.10. Remove From Cart
- 2.1.11. Calculate Cost
- 2.1.12. Checkout
- 2.1.13. Undo
- 2.1.14. Quit
- 2.1.15. Persistance on File optional
- 2.1. Actions
- 3. The Backend
- 4. Non-Functional Requirements
- 5. Tips: omdirigering av stdin för att testa programmet
- 6. Implementing Undo
- 7. Persistens på fil optional
- 8. Additions optional
- 9. Hints and Examples
- 10. Finishing the Assignment
This is a new version of this assignment from 2018. Please report all bugs and ask questions for things that are not clear. Because the assignment is new, expect bugs!
1 Simple Webstore Backend
In Assignment 2, we are going to put the data structures we implemented in Assignment 1 to use as we build a small program that pretends to be a back-end for a shopping website, which draws upon Labs 4 and 5. Like the labs, the program will be an interactive TUI program (TUI = Text User Interface or Terminal User Interface). The reason for going with an interactive program is because it tends to make things easier – if the program segfaults right after I hit “edit item”, then it is quite easy to know where to start looking for bugs.
Most programs do not have a user interface at all! Most programs interact with other programs, the surrounding OS and/or hardware. This is a surprising thought for many – after all, we tend to interact with software and often equate the program with its user interface.
Programming user interfaces is outside the scope of this course. We do not even use fancy libraries for dealing with TUIs like ncurses – because we don’t have the time to learn complex APIs.
User interfaces also come with lots of new interesting challenges, for example with respect to testing. How do we test that the program behaves like we want it to – e.g. that clicking button \(B\) takes us to dialog window \(D\), with field \(f\) in focus, etc. When developing for the web, for example, making sure things are legible, visible or even on the screen can be daunting. (Luckily, there are lots of tools and infrastructure for doing these kinds of things.)
During the course of this assignment, feel free to pretend that we are coding (part of) the logic for the backend of a website that sells stuff. We will focus on what goods are in stock, the quantities, the locations for these in a warehouse, and management of shopping carts. (There is of course tons more in the backend than what we will implement, like recommendations, search, tracking user’s movements through the store for A/B testing, etc.)
1.1 Terminology
Key terminology in this document:
- Merchandise (aka merch)
- Goods sold in this web store that may or may not be in stock. An example merch is “Wouldn’t it be Nice” (name) which is “a book by Brian Wilson and Todd Gould” (description) which costs 100 SEK (price – quite a bargain).
- Stock
- Inventory for a specific merch, e.g. we might have 1000 copies of “Wouldn’t it be Nice” that we hope might get into the hands of eager buyers. These 1000 copies might be spread across different storage locations.
- Storage Location
- A place that holds at least 1 copy of some merch. For example, the 1000 copies of “Wouldn’t it be Nice” could be stored at storage locations A25, B17 and C04. We do not keep track of empty storage locations. We also do not support mixing the items stored on a single location.
- Be in stock
- A merch is considered in stock if there is at least one storage location that holds at least 1 copy of it.
- Shopping cart
- A “list” of merch that a customer is interested in with an associated quantity for each. For example, a shopping cart can be empty, or hold 29 copies of “Wouldn’t it be Nice”.
2 The Frontend
To test the interaction of all the parts of our program, we are going to build a small frontend in the form of a text user interface. We could easily imagine the commands being issued by a store front. Some good news is that lots of the frontend work is already done – by you, during the labs. We have infrastructure for reading user inputs and parsing them.
2.1 Actions
The system should support the following actions through the text-user interface. When the program starts, it should enter into an event loop with the following actions, similar to what we did in the labs.
The system should ask for names, quantities, etc. and ask to confirm destructive updates like removing things. For example, if the text below reads add some quantity of a merchandise, this is to be interpreted as “ask the user for a name of a merchandise in the form of a string and a quantity of a merchandise in the form of an int”.
2.1.1 Add Merchandise
- This adds a new merch to the warehouse with a name (string), description (string), and price (integer).
- A newly added merch is not in stock.
- Adding a new merch with the same name as an existing merch is not allowed.
2.1.2 List Merchandise
- This should list all items in the store. Items should preferably (soft requirement) be printed in alphabetical order on their names. Because there may be more things in the database than might fit on a screen, items should be printed 20 at a time, and the user is asked to continue listing (if possible) or return to the main menu.
- In the implementation of Edit Merchandise, Remove Merchandise and Show Stock, show all Merchandise in the same fashion as List Merchandise and allow the user to pick an item by number from this list.
2.1.3 Remove Merchandise
- Removes an item completely from the warehouse, including all its stock.
2.1.4 Edit Merchandise
- Allows changing the name, description and price of a merch. Note that this does not affect its stock.
- Changing the name of a merch to the name of an existing merch is not allowed.
- Note that changing the name may mean changing the key unless you use a unique id for each merch.
2.1.5 Show Stock
- List all the storage locations for a particular merch, along with the quantities stored on each location. Storage locations should preferably be listed in alphabetical order (e.g., A20 before B01 and C01 before C10).
- Names of storage locations follow this format always: one capital letter (A-Z) followed by two digits (0-9).
2.1.6 Replenish
- Increases the stock of a merch by at least one.
- You can replenish on an existing storage location or a new one.
- The stock for a merch is the sum of all items on all storage locations holding that merch.
- A storage location stocks items of one (type of) merch, never more.
- For simplicity, there is no limit to the amount of storage locations nor is there a limit on the number of items a location can hold.
2.1.7 Create Cart
- Creates a new shopping cart in the system which is empty.
- A shopping cart represents a possible order.
- Adding/removing merch to/from a cart does not change the stock for that merch – stocks are changed only during checkout.
- Shopping carts are identified by a monotonically increasing number, i.e., the number of the \(i\)’th shopping cart created is \(i\), regardless of how many shopping carts have been removed.
2.1.8 Remove Cart
- Removes a shopping cart from the system.
2.1.9 Add To Cart
- Adds some quantity of a merch to a specific shopping cart.
- All possible orders in the system must be fullfillable. For example, we may only have one or more carts with 12 items of a merge \(M\) if the total stock of \(M\) in the system at least 12. Thus, if all users go to checkout at the same time, they should all succeed.
2.1.10 Remove From Cart
- Removes zero or more items of some merch from a particular cart.
2.1.11 Calculate Cost
- Calculate the cost of a shopping cart. If a cart holds 2 items of a merch \(M_1\) with a price of \(50\) and 8 items of a merch \(M_2\) with a price of \(3\) the cost of the cart is \(2\times 50 + 8\times 3 = 124\).
2.1.12 Checkout
- This action represent the user going through with a purchase of all the items in a particular shopping cart.
- Decrease the stock for the merches in the cart.
- Remove the shopping cart from the system.
2.1.13 Undo
- Undos an action.
- Multiple undos should be supported (i.e., pressing undo \(N\) times undos the \(N\) last actions for \(N \leq 16\).)
- You cannot “undo an undo” (aka “redo”).
2.1.14 Quit
- Quits the program.
2.1.15 Persistance on File optional
- The program should save its data on disk between runs. There is a discussion about how to implement this further down in this document.
Notes on storage locations and items
- A storage location can only store items of one (kind of) merch
- Always stores at least one item (not zero)
- Items of a single merch can be stored at multiple storage locations
3 The Backend
We can pretend that the frontend is queries and information going back and forth between some fancy website interface and the backend, which holds all the logic of the system.
3.1 Data Design
Analysing the functional specification of the program, it is clear that we navigate through the data in several different ways.
- Given the name of an item, find its information
- Given the name of an item, find its storage locations in the warehouse
- Given a storage location, find what is stored on it
We can design a struct \(S\) that holds the information about an item \(i\) as well as a list \(L\) of the locations in the warehouse storing \(i\)’s, including the number of items at each location. We can then use our hash table from Assignment 1 using names of items as keys and pointers to instances of \(S\) as values. With this design, given a name of an item, we can easily find its information and storage locations, satisfying Requirement 1 and 2 in the list above. Let us call this hash table \(HT_{n\to S}\).
However, let us see what happens under that data design, if we try to find what is stored on storage location \(s\) (Requirement 3).
With the current data design, we would have to get all values of the hash table (i.e., all \(S\) structs) and for each \(S\), go through its \(L\) in search for \(s\). That seems both complicated and inefficient.
Thus, we can extend our data design with a second hash table that uses storage location names as keys and items (or item names) as values. This allows us to satisfy Requirement 3 just as straightforward as Requirements 1 and 2. Let us call the second hash table \(HT_{s\to n}\).
The price for this extra complexity in the data design is keeping \(HT_{n\to S}\) and \(HT_{s\to n}\) in sync.
In summary, the key data structures in the system are:
- \(HT_{n\to S}\): a central hash table mapping names1 of items to their information
- \(HT_{s\to n}\) a central hash table mapping names of storage locations to names of items stored on the location
- for each item \(S\), a list \(L\) of the locations where it is stored, and the amount stored at each location
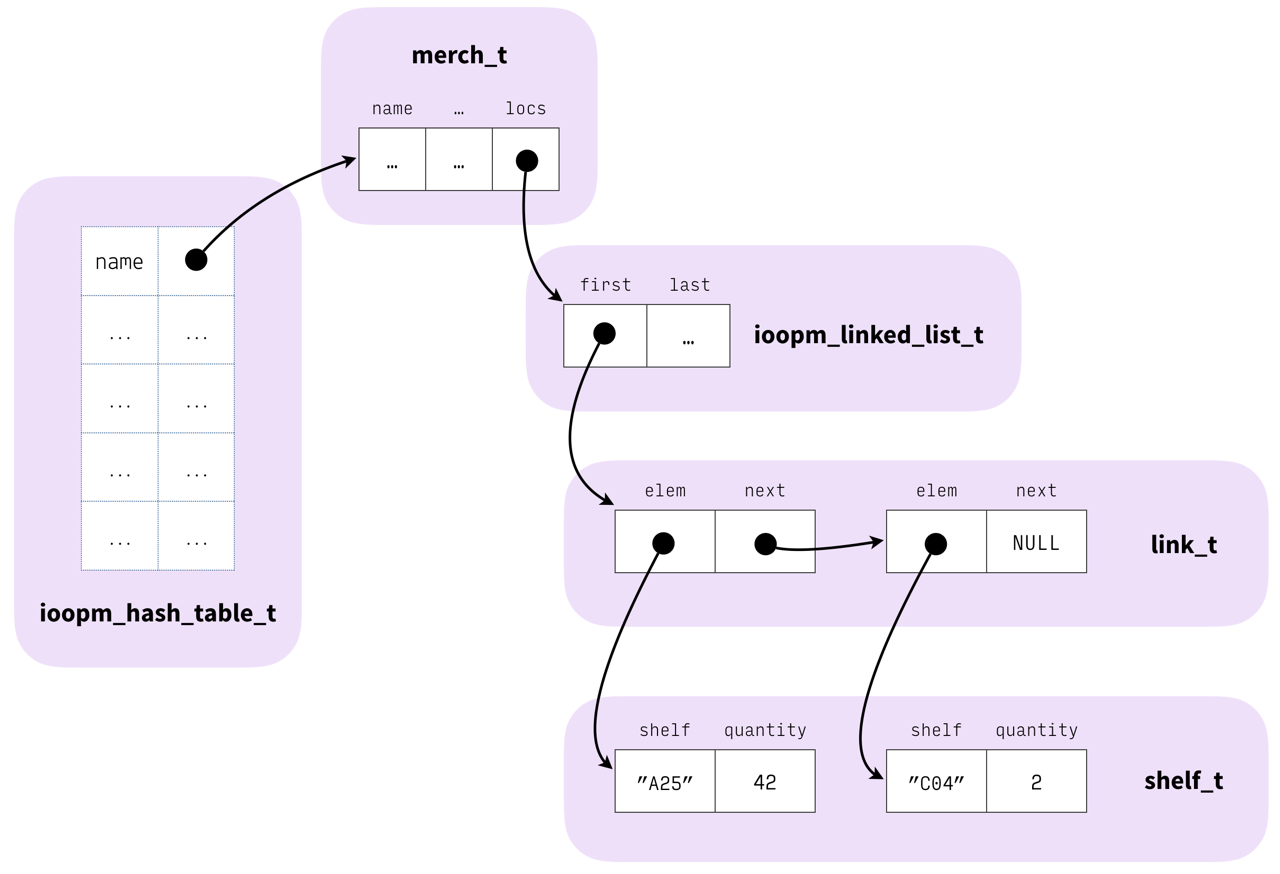
Figure 1: An overview of what the first hash table (\(HT_{n\to S}\)) could look like, including \(L\).
3.2 Shopping Cart
A shopping cart is basically a mapping from names of items to quantities greater than zero. Thus, on a first iteration (at least!) we can use a hash map as a shopping cart.
We can use a linked list to hold all the shopping carts in the system. Or, if we give each shopping cart a unique identifier (for example, some username of the user to which the cart belongs), we can use another hash map to hold all the shopping carts in the system.
3.3 Handling faulty inputs
The system should not allow entering values that are not in the
allowed range. If the user enters bad input, an error message
should be printed and the user asked to try again.
This is how we have built up the ask_question_... functions from before.
4 Non-Functional Requirements
The above specification details the functional requirements i.e., what the software does. In contrast, non-functional requirements are about how the software does what it does, and its constraints.
Non-functional requirements are often every bit as important for a piece of software as the functional requirements. For example, if we must fit the program withing 1 Mb or memory, or always respond within 10 milliseconds, etc. – it may well be that a functionally perfect software is unusable for the customer if we fail to deliver on these.
In this assignment, the non-functional requirements are a bit unusual in that they come in the form of constraints on your implementation which are meant to guide to write good code, or face interesting situations. Nevertheless, these requirements are indeed non-functional ones.
4.1 Separation Into Modules
The program should be divided into at least four modules:
- generic data structures
- Lists, hashmaps, and more – if you need them.
- generic utils
- Utilities (many of which we have implemented before) which are not specific to a program.
- business logic
- All non-user interface logic that concerns the system, e.g. shopping carts, merchandise, adding and removing items from the “database” (most of which will delegate to e.g. the hash table library), etc.
- user interface
- Everything that has to do with the program’s user interface.
This does not mean e.g.,
ask_question_string()and the like – these are generic library routines not specific to this program. However, functions like printing options and reading input of data specific to the program in question belongs in this module.
The two first modules are called generic for a reason: they should
be usable across many programs, which neither know of – nor wants
to know of – merchendise or what input is valid in some
particular dialog. If you find that you want utils.c to include
db.h or ui.h (or whatever they might be called), something is
wrong.
4.2 Quality Assurance
4.2.1 Code Reviews
As part of the quality assurance, you will enlist the help of some other team in your group to review your code. You can read more about code reviews here. The other team will report on your code through GitHub as an issue with feedback and you will respond to their issue through comments.
4.2.2 Reliance on Testing
Testing is of utmost importance here. You are going to use CUnit for your unittests.
Note that we are not going to test the user interface part of the assignment. We should, but there is no time. We could e.g., use a behaviour-driven test tool that is able to parse output and so on.
Unittests will focus on invididual methods in the backend. For example, adding a new merchendise will test the behaviour on good and back input (how handle duplicates?), and check that stock for new merchendise come back as zero.
Note that you are building on data structure libraries that come with a set of tests. We don’t need to test that e.g., the hash table is correct in our tests – we should test that the treatment of merchendise, items, storage locations etc. are correct. That means we are staying (at least) one solid level of abstraction above the hash table, list, etc.
As a rule of thumb, all functions outside of the user interface module need to be properly tested.
4.2.3 Koddokumentation
This applies to the generic utils and the business logic modules, and of course basic data structures (but that part is almost 100% handed out).
Använd verktyget doxygen för att dokumentera din kod. Du kan börja med att titta på exempel i headerfiler från Inlupp 1. Målet med koddokumentation är att förklara för en användare av koden (inte programmet) hur den skall användas.
Tänk dig att vi plötsligt skulle byta ut din implementation mot en annan grupps implementation, som du aldrig har sett. Förmodligen är många funktioner väldigt lika, men det finns säkert också stora skillnader. Funktioner som du aldrig har sett blir betydligt enklare att använda om de har en beskrivande text och funktioner som du också har, men som skiljer sig litet, är ännu viktigare att ha dokumentation för eftersom din förförståelse för hur de fungerar kommer att vara fel.
Dokumentation är med fördel kort för enkla saker och längre för komplexa saker. För komplexa funktioner kan man t.ex. ha ett exempel på hur man kan använda den för att göra något.
Tänk på att dokumentation kostar! När programmet ändras måste dokumentationen också ändras för att fortfarande vara korrekt. Felaktig dokumentation är en klassisk felkälla.
4.3 Integrating Code from Different Sources
This assignment reuses components from earlier in the course:
- Hash table (assignment 1)
- Linked list (assignment 1)
- Utils (C bootstrap labs)
You are doing Assigment 2 in a team of two people. As a starting point of this work, you need to pick components 1–3 above from 3 discrete sources from within the same group. For example, let Alice, Bob and Cecil be members of the same group, and Alice and Bob work together on Assignment 2. In the start of their work, Alice and Bob compile the following:
- Hash table comes from Alice’s Assignment 1
- Linked list comes from Cecil’s Assignment 1
- Utils comes from Bob’s C bootstrap labs
This is documented in the README.md file in their Assignment 2
directory.
Note that goods, shelves etc. from the bootstrap labs were not part of Utils. Alice and Bob are free to reuse their old goods and shelves stuff from the bootstrap labs, or start afresh as they please.
During their work, Alice and Bob discover a bug in Cecil’s linked list implementation. They report this bug as an issue on GitHub. If they have a suggested fix locally, they can even make a pull request so that Cecil simply needs to vet their code, not write an own solution.
5 Tips: omdirigering av stdin för att testa programmet
I UNIX-miljö kan indata till ett program komma från en textfil. När programmet körs läses svaren till programmets frågor från en fil istället för att matas in för hand. Detta kommer att vara nyttigt för att testa ditt program i denna uppgift eftersom det kommer att krävas många inmatningar för att fylla programmet med intressant data.
Du kan t.ex. pröva att styra en minimal interaktion med programmet
så här. Nedanstående antar att menyvalen är Q för Quit, A
för Add Item, L för List Items, och att ordningen på indata i
Add Item är namn, beskrivning och pris.
- Skapa en fil
test.txtmed innehålletQoch en radbrytning. (Qför att avsluta programmet – byt till annat tecken om du gjort ändringar.) - Kör programmet så här:
./myprog < test.txtdärmyprogär det kompilerade programmet.
Nu kan du pröva att ändra i test.txt. T.ex. så här:
A Kritor Vita kritor 20 L Q
Detta skall lägga till en vara (kritor), lista hela varukatalogen, och sedan avsluta. (Notera att ditt program kanske tar emot indata i en annan ordning!)
6 Implementing Undo
This is a candidate for axing if we need to make the assignment smaller. It makes sense to schedule this last in your implementation.
Implementing support for undoing actions is possible by maintaining a LIFO stack of actions in the program (we call this the undo stack). Every time the user performs an undoable action through the frontend, we push its counter-action to the undo stack. When the user wants to undo, we simply pop the last counter-action from the undo stack and perform it.
Some actions might require that we reset the undo stack. For example, support for opening another database file could be such an event.
Note that we can use our list to implement a LIFO stack – push using prepend and pop using remove with index 0.
Examples:
- The counter-action for adding a merchandise \(m\) is the removal of \(m\).
- The counter-action for the removal of shopping cart \(c\) is adding \(c\) back to the carts list.
- The counter-action for checkout of shopping cart \(c\) is adding \(c\) back to the carts list, and replenishing the stock for all merchandise that was removed when \(c\) was checked-out.
- There is no counter-action for calculating the costs of a shopping cart.
One possible design is to create a struct action which holds a
pointer to an undo function that should be called, all the
arguments to this function, and a pointer to the next action to be
performed in case the undo action requires several function calls.
Because different functions take different arguments, the
arguments part of action should probably be a union.
Here is an incomplete sketch of how we could implement undo functionality. It adds a type for the undo stack, and create, push and pop functions for it. It shows how the add merchandise backend function – in addition to adding a merchandise to the database – creates an undo action datum, populates it, and pushes it to the undo stack. Last, it shows the undo function that pops from the undo stack, and calls the function of the popped action.
typedef undo_stack_t list_t; undo_stack_t *undo_stack_create() { return ioopm_linked_list_create(); } action_t *undo_stack_pop(undo_stack_t *undo_stack) { if (ioopm_hash_table_size(undo_stack) > 0) { elem_t e = ioopm_linked_list_remove(undo_stack, 0); return e.pointer; } else { return NULL; } } void undo_stack_push(undo_stack_t *undo_stack, action_t *action) { ioopm_linked_list_prepend(undo_stack, action); /// if the size of the stack is > 16, remove from the end and /// free actions and (possibly) their associated memory } bool add_merch(db_t *db, undo_stack_t *undo_stack, merch_t *m) { ioopm_hash_table_insert(db, m.name, m); action_t *undo = calloc(1, sizeof(action_t)); /// FIXME: move to a create function undo->func = undo_add_merch; undo->args.db = db; undo->args.merch_id = m.name; undo_stack_push(undo_stack): } bool undo(undo_stack_t *undo_stack) { action_t *action = pop_undo(undo_stack); if (action == NULL) return false; /// Nothing to undo do { action.func(action.args); /// call the undo function with its arguments action_t *tmp = action; action = action->next; free(tmp); } while (action); //7 to support several linked actions return true; } void undo_add_merch(undo_args_t *args) { remove_merch(args->db, args->merch_id); /// any calls to free necessary }
typedef%20undo_stack_t%20list_t%3B%0A%0Aundo_stack_t%20%2Aundo_stack_create%28%29%0A%7B%0A%20%20return%20ioopm_linked_list_create%28%29%3B%0A%7D%0A%0Aaction_t%20%2Aundo_stack_pop%28undo_stack_t%20%2Aundo_stack%29%0A%7B%0A%20%20if%20%28ioopm_hash_table_size%28undo_stack%29%20%3E%200%29%0A%20%20%20%20%7B%0A%20%20%20%20%20%20elem_t%20e%20%3D%20ioopm_linked_list_remove%28undo_stack%2C%200%29%3B%0A%20%20%20%20%20%20return%20e.pointer%3B%20%0A%20%20%20%20%7D%0A%20%20else%0A%20%20%20%20%7B%0A%20%20%20%20%20%20return%20NULL%3B%0A%20%20%20%20%7D%0A%7D%0A%0Avoid%20undo_stack_push%28undo_stack_t%20%2Aundo_stack%2C%20action_t%20%2Aaction%29%0A%7B%0A%20%20ioopm_linked_list_prepend%28undo_stack%2C%20action%29%3B%0A%0A%20%20%2F%2F%2F%20if%20the%20size%20of%20the%20stack%20is%20%3E%2016%2C%20remove%20from%20the%20end%20and%20%0A%20%20%2F%2F%2F%20free%20actions%20and%20%28possibly%29%20their%20associated%20memory%20%0A%7D%0A%0Abool%20add_merch%28db_t%20%2Adb%2C%20undo_stack_t%20%2Aundo_stack%2C%20merch_t%20%2Am%29%20%0A%7B%0A%20%20ioopm_hash_table_insert%28db%2C%20m.name%2C%20m%29%3B%0A%0A%20%20action_t%20%2Aundo%20%3D%20calloc%281%2C%20sizeof%28action_t%29%29%3B%20%2F%2F%2F%20FIXME%3A%20move%20to%20a%20create%20function%0A%20%20undo-%3Efunc%20%3D%20undo_add_merch%3B%20%0A%20%20undo-%3Eargs.db%20%3D%20db%3B%0A%20%20undo-%3Eargs.merch_id%20%3D%20m.name%3B%0A%0A%20%20undo_stack_push%28undo_stack%29%3A%0A%7D%0A%0Abool%20undo%28undo_stack_t%20%2Aundo_stack%29%0A%7B%0A%20%20action_t%20%2Aaction%20%3D%20pop_undo%28undo_stack%29%3B%0A%20%20if%20%28action%20%3D%3D%20NULL%29%20return%20false%3B%20%2F%2F%2F%20Nothing%20to%20undo%0A%0A%20%20do%20%0A%20%20%20%7B%0A%20%20%20%20%20action.func%28action.args%29%3B%20%2F%2F%2F%20call%20the%20undo%20function%20with%20its%20arguments%0A%20%20%20%20%20action_t%20%2Atmp%20%3D%20action%3B%20%0A%20%20%20%20%20action%20%3D%20action-%3Enext%3B%0A%0A%20%20%20%20%20free%28tmp%29%3B%20%0A%20%20%20%7D%0A%20%20while%20%28action%29%3B%20%2F%2F7%20to%20support%20several%20linked%20actions%0A%0A%20%20return%20true%3B%0A%7D%0A%0Avoid%20undo_add_merch%28undo_args_t%20%2Aargs%29%0A%7B%0A%20%20remove_merch%28args-%3Edb%2C%20args-%3Emerch_id%29%3B%20%0A%20%20%2F%2F%2F%20any%20calls%20to%20free%20necessary%0A%7D%0A
The greatest difficulty of supporting undo in our C program is figuring out how to manage memory. For example, we cannot call free on a merchendise when we remove it, because we need it in the undo stack.
The upper bound on the undo history is 16 meaning that pushing more than 16 actions should trigger calls to free due to old actions in the undo stack being “retired”.
7 Persistens på fil optional
Nu skall vi lägga till stöd för att spara databasen på fil och läsa upp
den igen. Börja med att bekanta dig med hur funktionerna fopen,
fread och fclose fungerar, lämpligen genom att implementera en egen
version av UNIX-programmet cat (skriv man cat om du inte känner till
programmet).
Programmet skall ta som kommandoradsargument, namnet på den fil som innehåller databasen. Om denna fil inte finns skall den skapas och databasen skall vara tom. När programmet avslutas skall databasen sparas ned på filen så att den kan läsas upp igen nästa gång programmet startar. Det finns inga kommandon i programmet för att spara eller ladda databasen – det sker automatiskt.
För att spara datat i databasen har du två val:
- Spara datat som radorienterad text där varje vara tar upp minst
3 rader (namn, beskrivning, pris, …); en lagerplats tar upp
minst tre rader (lagerplats, vilken vara, vilken kvantitet,
…), och motsvarande för en shopping cart.
För enkelhets skull kan du ha en separat fil för varje typ av data
du vill spara (varor, lagerplatser, kundvagnar, …) – så kan du
läsa rätt antal rader och skapar en post i databasen från den.
När man når
EOF– end of file – är du klar med en fil. - Definiera ett binärt filformat på motsvarande sätt. En hyfsat bra start för varor är detta:
int siz; // antal bytes i posten int name_siz; // antal tecken i nästföljande sträng char[name_siz] name; // namnet int desc_siz; // antal tecken i nästföljande sträng char[desc_siz] desc; // beskrivningen int price; // pris
int%20siz%3B%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20antal%20bytes%20i%20posten%0Aint%20name_siz%3B%20%20%20%20%20%20%20%20%2F%2F%20antal%20tecken%20i%20n%C3%A4stf%C3%B6ljande%20str%C3%A4ng%0Achar%5Bname_siz%5D%20name%3B%20%2F%2F%20namnet%0Aint%20desc_siz%3B%20%20%20%20%20%20%20%20%2F%2F%20antal%20tecken%20i%20n%C3%A4stf%C3%B6ljande%20str%C3%A4ng%0Achar%5Bdesc_siz%5D%20desc%3B%20%2F%2F%20beskrivningen%0Aint%20price%3B%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20pris%0A
Man kan till och med tänka sig att själva filen startar med en int som
berättar hur många poster den innehåller, men det går förstås också bra
att leta efter EOF – end of file.
8 Additions optional
These are meant for those who like to tinker with the assignment, wants to do more, or needs an idea for an extension to demonstrate something.
- Find the cheapest or most expensive merchendise
- Print the sum of all items in stock
- Compaction: move all items of the same merchendise to a single storage location
- Support for multiple sort orders when printing merchendise
- Search for a certain merchendise and see all storage locations for that
- Support some degree of “fuzzy matching” for 5.
- Add an upper limit on how many items can be stored on a storage location. Note the interaction with this and 3. above – make sure that all items of a single merchendise are stored consequtively.
- Make the program case insensitive, meaning the following will be considered three different merches: “foo”, “Foo” and “FOO”.
- Support changing the name of a merchendise – this might affect its key!
- Support for saving the database to file and opening a different database file while the program is running.
- Merge two merches into one, with one name, description and all the stock of the original two.
9 Hints and Examples
9.1 Creating a Hash Table Mapping Names to Merch
Imagine we have a type merch_t (for example) which has a field
name of type char *. We know that names of merch are unique,
so names are good keys.
We can create a hash table like so:
ioopm_hash_table_t *ht = ioopm_hash_table_create(17, string_knr_hash, string_key_eq);
ioopm_hash_table_t%20%2Aht%20%3D%20ioopm_hash_table_create%2817%2C%20string_knr_hash%2C%20string_key_eq%29%3B%0A
Clearly, ht is not a very good name. The role of the hash table in
the program is a much better naming strategy than “it’s a hash table”.
The string_key_eq() function simply extracts strings from the
elem_t typed keys and delegates to strcmp() like so:
bool string_key_eq(elem_t k1, elem_t k2) { return strcmp(k1.string, k2.string); // if elem_t has field char *string }
bool%20string_key_eq%28elem_t%20k1%2C%20elem_t%20k2%29%0A%7B%0A%20%20return%20strcmp%28k1.string%2C%20k2.string%29%3B%20%2F%2F%20if%20elem_t%20has%20field%20char%20%2Astring%0A%7D%0A
10 Finishing the Assignment
- At the end, go over your backlog of cheats and dodges and see which ones need taking care of. Ideally this stack should be empty. If you have made any special deals for some parts of your code, make sure these are documented somewhere (in the repo).
- As the first section of
README.md, add instructions for how to build the program and run its tests. Ideally this should be as easy asmake test. In this section, also state the line coverage and branch coverage per.cfile and what tool you used to obtain these numbers. - Write a minimal documentation of how to use your program –
after building it, how does one start it, and what files etc.
(if anything) must be present. Put this in a
README.mdin the top-level directory for this assignment. - Prepare a demonstration of z101 to give at the next lab. In addition to z101, pick another 2-3 achievements to tick off, and include these in your demonstration preparation. To back up your presentation, present evidence like places in your code where relevant things show up, documentation, paper drawings, etc. – things that support your demonstration. Think carefully about what things fit together (ask for help if you feel uncertain after trying) and what achievements tell a good story together. Make sure that not one person dominates the demonstration or answers all questions to avoid someone failing the demonstration because there was no evidence of achievements mastery.
- Send an email to z101@wrigstad.com with your names and usernames, a link to the GitHub repository where the code can be checked out.
- Create a final commit for the assignment and check it into
GitHub. Tag the commit with
assignment2_done. - Optional Please take time to feedback on the assignment.
Note: Don’t expect any feedback on your program over what you have got from the oral presentations. If you want more feedback on specific things, ask questions in conjunction with your presentations, or add your name to the help list.
Questions about stuff on these pages? Use our Piazza forum.
Want to report a bug? Please place an issue here. Pull requests are graciously accepted (hint, hint).
Nerd fact: These pages are generated using org-mode in Emacs, a modified ReadTheOrg template, and a bunch of scripts.
Ended up here randomly? These are the pages for a one-semester course at 67% speed on imperative and object-oriented programming at the department of Information Technology at Uppsala University, ran by Tobias Wrigstad.