Assignment 3 (Phase 2, Sprint 1)
Table of Contents
- 1. Introduction
- 2. Letting Go of C – A Prelude to the Assignment
- 3. A Symbolic Calculator
- 4. The Language of the Calculator
- 5. Important Concepts
- 6. Choosing Your Approach
- 7. Parsing the Calculator’s Language
- 8. Implementing the AST
- 8.1. Step B1: Skeleton Class Hierarchy
- 8.2. Step B2: Adding Constructors
- 8.3. Step B3: Adding Simple Methods
- 8.4. Step B4: Creating a Small Test Expression
- 8.5. Step B5: Printing Expressions
- 8.6. Step B6: Adding Support for Equality Comparison
- 8.7. Step B7: Evaluating Expressions
- 8.8. Step B8: Implementing Commands
- 9. Integration and Extension Part
Intended start: 2018-10-29
Soft deadline: 2018-11-16
Hard deadline: 2018-11-30
This is a complete rewrite of an old assignment on this course. The old text of this assignment is available here for now. Feel free to look at the old text and see if you prefer it (it is shorter!). Note that there are some changes and some extensions to the assignment in its new form.
Please help me improve this assignment by asking questions, suggesting improvements, etc.
1 Introduction
This assignment serves several purposes:
- Demonstrate typical object-oriented programming idioms, and typical Java idioms.
- Highlight the differences between Java and C
- Create multiple opportunities to demonstrate mastery of achievements.
- Force you to code – reading and writing code are the only two techniques that work when learning how to program, and only if you do both.
2 Letting Go of C – A Prelude to the Assignment
This section is pure “theory” – not discussing the actual assignment. Everything in this section was also said during lectures.
Object-oriented programs consist of networks of objects that communicate with each other by sending messages. At face value, these messages are not much different from a function call, but there are key differences stemming from object-oriented abstraction, encapsulation and polymorphism. In a C program, we might write something like:
foo(bar)
which means perform the foo operation on the bar data. In this case, we (the programmer) chose what operation to perform, and the foo operation must be able to know how a bar datum is constructed to carry out its work.
In contrast, an object-oriented program might write:
bar.foo()
While this is more or less syntactically equivalent to foo(bar), morally, the difference is huge: in this case, we are asking the bar object to (please) respond to the foo message. In practice, this means that:
- Whatever foo means will be decided by the bar object. A
classic example is
cowboy.draw()andcircle.draw()– illustrating that the meaning of draw is highly contextual (while obviously being a tad contrieved). - The contents of bar may not even be known to us – we could
have
x.draw()and not knowing whetherxis a cowboy or a circle.
The designers of Java choose to make their program syntactically similar to C in order to make the switch to Java from C easier or more appealing. Semantically, however, Java is very different from C, as was hopefully illustrated by the difference between function calls (foo(bar)) and methods calls (foo.bar()).
The reason for pointing this out is that the syntactic similarities make it very easy to keep writing C-style programs in Java, which means that you are not working with the languages strenghts and also not getting any of the benefits of C (as in the reasons why you should ever program in C).
2.1 Class Hierarchies
The object is central to object-oriented programming. In prodecural programming languages like C, when we were designing a program, our focus was on indentifying the operations in the program and defining functions (aka procedures) that carry out these operations. When we design object-oriented programs, our focus is on identifying the key actors or objects in the system, and defining their interaction.
Once we have analysed a problem or a specification and found the objects, we should ponder the relationship between the objects. If we find many objects that fill a similar function, we define a class for those objects. A class is a description of a group of objects that specify the data and behaviour of those objects. Classes are thus often referred to as blueprints for objects. Classes are so common in object-oriented programming languages that the term class-based object-oriented programming is virtually extinct – we don’t need a special term to describe “normal object-oriented programming”1.
Just like we group related objects in classes, we may also group related classes and organise them into hierarchies. Class hierarchies can be used for several things, perhaps most notably:
- They allow us to use existing classes to build new classes (code reuse)
- They allow us to build specialised versions of more generalised classes – including many “parallel specialised versions” (specialisation)
- They allow us to modularise some logic so that certain things can be described or handeled in isolation (modularisation, cf. coupling and cohesion)
In most object-oriented programming languages, class hierarchies
form a tree rooted in some common object. In Java, for example,
the root class is called Object. The relationship between
classes is called inheritance because children in the
inheritance relation inherit the state and behaviour of their
parents. The inheritance relationship is transitive, meaning that
if A inherits from B and B inherits from C, then A inherits from C
as well. In Java, all classes inherit from Object, either
directly or indirectly.
For example, if classes AB and BC share a common “B” part, we might extract B into a new class B, and let classes A and C inherit from B (this is also called be derived from, or extend). If the B concept does not make sense from the view of the program’s domain – this is a case of 1 above. If B represents something sensible, e.g. AB = Teacher and BC = Student, we might introduce a class Person and move common person-related parts from Teacher and Student there, like name, age, social security number, and whatnot.
Sometimes, it makes sense to add a class which exists solely to construct a nicer hierarchy. In a university setting, there is no need for an “unspecific Person concept”, but it still makes sense as common logic can be moved there. In these cases, a class can be declared abstract. This means that it cannot be used to construct objects.
In this assignment, we are going to use class hierarchies in the
way of 2 and 3 above as we construct an abstract syntax tree of
symbolic expressions (these concepts will be explained below).
At the root of our class hiearchy sits the class
SymbolicExpression which is an abstract class from which many
classes are derived, directly or indirectly.
2.2 Relations Between Objects and Classes
Above we discussed the inheritance relation which is a class–class relationship. Another important relation is the so-called is a relationship between classes and objects that denotes “membership” of an object in a class. An object created from the Teacher class is a teacher. Notably, for each class \(C\) such that Teacher extends \(C\) (meaning Teacher inherits from \(C\)), a teacher object is a \(C\). For example, a Teacher is a person (believe it or not). Often you can test whether an object \(o\) is is a-related to a class \(C\) by simply saing “\(o\) is a \(C\)” out loud and see if it makes sense.
Person<........ ^ . | . inherits . | . Teacher<---is a---obj
In this assignment, the is a relation is key to expressing the abstract syntax trees. For example, because both a number and division is a expression, we can build code and structures that operate on branches of the AST in terms of expressions, without actually caring whether they are numbers, divisions, etc.
The programming language feature we rely on is subtype polymorphism which allows us to have multiple objects of different types all masquerade as being of a common supertype.
2.3 Relations Between Objects
Since object-oriented programs consist of networks of objects, it is clear that many objects in an object-oriented program are related. In the sense that the inheritance relation between classes is used to explain that one class is a building block of another, we talk about the aggregation relation between objects, when one or more objects are intregral in constructing another object. Objects which are constructed of many other objects are often called aggregate objects or sometimes composite objects. A linked list object could be said to aggregate its links – the links are integral building blocks of the linked list and there is no need for links to exist unless there is a list to which they belong. A hand object would aggregate its fingers, etc.
In the assignment, we will use aggregation to let the program aggregate its parser and also let e.g. binary expressions (like \(a + b\)) aggregate their subexpressions (\(a\) and \(b\)).
3 A Symbolic Calculator
In this assignment, we are going to build a symbolic calculator. The calculator is like a simple interactive programming language. Typical interaction works like this:
- A user enters expressions in the terminal (e.g.,
5 + 37). - The calculater parses these expressions and converts them into something called an abstract syntax tree (AST) which is a representation of an expression that is convenient to operate on, for example to evaluate the expression.
- The calculator evaluates the expression using the AST relying on method overriding.
In the next assignment, we are going to improve on how we perform AST manipulations to demonstrate some typical object-oriented patterns and concepts.
Below is a video showing a sample interaction with a symbolic calculator:
Hopefully, the above video makes it more concrete what you are going to build. Below, we go through more sample interaction with the program and explain what happens bit by bit.
The prompt in the program is the ?. Each line is an expression
that is evaluated immediately and the result is printed on the
following line. Note the strange syntax for assignments where
variables go to the right of the value, e.g., 3 = x to assign 3
to the variable x. There is no declaration of variables like in
C or Java – instead they are created on first assignment. The
text within [brackets] below are comments for the reader.
$ java Calculator Welcome to the Symbolic Calculator! ? 2*(5-2) 6.0 [All numeric operations use floating point arithmetic (double)] ? 1/(2+8) = a [Assign values to variables -- variable names to the right!] 0.1 [Assignments return the value of the variable.] ? 2 = x = y [Multiple assignments are supported.] 2.0 ? (x+y=z) - (z-1)*(1=x) [Assignments are allowed inside expressions. Evaluation from left to right.] 1.0 ? -sin(exp(a*a*10)) [Elementary functions.] -0.8935409432921488 ? ans [This is a built-in variable that stores the value of the last expression evaluated.] -0.8935409432921488 ? -ans+2 [Ans can be used as a normal variable.] 2.8935409432921488 ? - - -x -1.0
Additional examples of interaction.
? b [Undefined variables evaluate to themselves]
b
? 1 = a
1.0
? a + b [Sometimes evaluation results in an expression]
1.0 + b
? b + a = c [Values can be expressions]
b + 1.0
? 2 = b [Assigning a value to b does not change previous expressions containing b]
2.0
? c [Evaluation only happens once -- values are not evaluated!]
b + 1.0
? 2*x = y
2.0*x
? vars [Built-in command to list all existing variables and their values.]
2 {ans=1.0, a=0.1, x=1.0, y=2.0, z=4.0}
? 3**5 ++ x [Failure handling -- no crashing.]
*** Syntax Error: Unexpected: *
? foo(x+y)
*** Syntax Error: Unexpected: (
? 1/0 [Some errors can be left to Java to handle.]
Infinity
4 The Language of the Calculator
The language of the calculator is pretty simple and is hopefully
familiar. Parsing starts at the top-level, by parsing a single
statement followed by an “end of line” (aka '\n').
Below is the grammar for the input language that the calculator
will understand expressed in BNF form. Words formatted like this:
quit, vars, exp etc. are terminal symbols meaning they are
special words that the calculator should recognise. Words
formatted like this: EOL, number etc. are special terminal
symbols which are explained after the figure. Words which are
formatted like this: \(\textit{statement}\), \(\textit{term}\), (etc.)
are non-terminal symbols, meaning they denote one or more subexpressions.
For example, the string “5 + 37 = theanswer” is parsed thus: the whole string is a statement, and the statement is an assignment, whose left-hand side (LHS) is the expression “5 + 37” and whose right-hand side (RHS) is an identifier (“theanswer”). The expression “5 + 37” is in turn parsed as addition whose left term is the primary number 5 and whose right term is the primary number 37.
\begin{array}{rcll} top\_level & ::= & \textit{statement} ~ \textbf{EOL}\qquad & \text{One line of input, followed by end of line} \\ \textit{statement} & ::= & \textit{command} \\ & | & \textit{assignment} \\ \textit{command} & ::= & \texttt{quit} & \text{Quit the calculator}\\ & | & \texttt{vars} & \text{Print the variables}\\ \textit{assignment} & ::= & \textit{lhs} \\ & | & \textit{lhs} ~ \textit{rhs} \\ \textit{lhs} & ::= & \textit{expression} \\ \textit{rhs} & ::= & = \textit{identifier} \\ & | & = \textit{identifier} ~ \textit{rhs} & \text{(note the recursive definition)} \\ \textit{expression} & ::= & \textit{term} \mathop{+} \textit{term} & \text{Addition}\\ & | & \textit{term} \mathop{-} \textit{term} & \text{Subtraction}\\ & | & \textit{term} \\ \textit{term} & ::= & \textit{factor} \mathop{*} \textit{factor} & \text{Multiplication}\\ & | & \textit{factor} \mathop{/} \textit{factor} & \text{Division} \\ & | & \textit{primary} \\ \textit{factor} & ::= & \textit{primary} & \text{You can unify factor and primary} \\ \textit{primary} & ::= & \texttt{(}~ \textit{assignment} ~\texttt{)} \\ & | & \textit{unary} \\ & | & \textbf{number} & \text{An integer or floating point number} \\ & | & \textbf{identifier} & \text{A name consisting of letters a-z and A-Z} \\ \textit{unary} & ::= & \mathop{-} \textit{primary} & \text{Negative numbers} \\ & | & \texttt{exp} ~ \textit{primary} \\ & | & \texttt{log} ~ \textit{primary} \\ & | & \texttt{sin} ~ \textit{primary} \\ & | & \texttt{cos} ~ \textit{primary} \\ \end{array}
EOL means \n. number means any positive number e.g., 0,
3.14159, 42, etc. identifier means a single word comprised of
letters a-z and A-Z. Note that keywords like quit and vars
should not be accepted as idenfiers.
Note that the grammar describes a tree where the leaves will be terminal symbols and all other nodes be non-terminals.
4.1 Examples of Evaluation
The following examples are meant to be executed from top to bottom. Read the explanations.
| Input | Result | Comment |
|---|---|---|
3=x |
3 |
The assignment returns the assigned value as the result 3 |
x+y |
3+y |
If a symbol has a value, that value will be used in its place on assignment |
z+2=y |
z+2 |
|
3=z |
3 |
|
y |
z+2 |
Symbols are only evaluated once (else the value would be 5) |
y=f |
z+2 |
Again, only evaluated once |
f+z*2 |
z+2+6 |
Optional: symbols are evaluated once, but… |
f+z*2 |
z+8 |
Optional: …one could imagine simplifications anyway! (Hard!) |
z+x=g |
6 |
g is assigned the value 6 |
g |
6 |
|
f |
z+2 |
|
z |
3 |
|
(f+z*z) |
z+2+9 |
4.2 Grammar as BNF in ASCII
The following figure captures exactly the same information as above, but presented in a more compact format.
top_level ::= statement EOL
statement ::= command
| assignment
command ::= *quit*
| *vars*
assignment ::= lhs
| lhs rhs
lhs ::= expression
rhs ::= = identifier
| = identifier rhs
expression ::= term + term
| term - term
| term
term ::= factor * factor
| factor / factor
| primary
factor ::= primary
primary ::= ( assignment )
| unary
| number
| identifier
unary ::= - primary
| exp primary
| log primary
| sin primary
| cos primary
4.3 Grammar as Syntax Diagrams
Below follows yet another representation of the same information as in the BNF grammar above, this time in the form of syntax diagrams. They are included here as I suspect different people prefer different representations of the same information.
The diagrams below state that input the program consists of statements, one per line. In an earlier version of this assignment, factor also contained derivates. Now that these are gone, you can unify factor and primary.
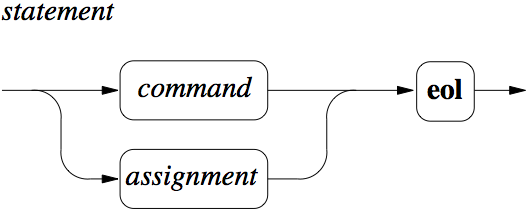
Figure 1: Statement
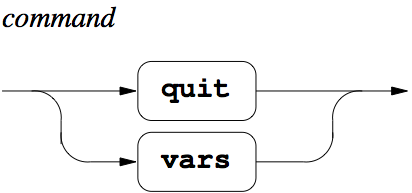
Figure 2: Command
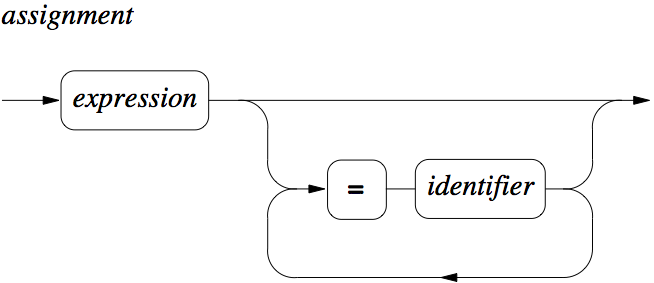
Figure 3: Assignment
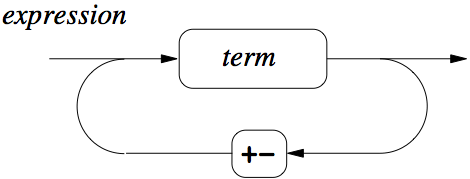
Figure 4: Expression
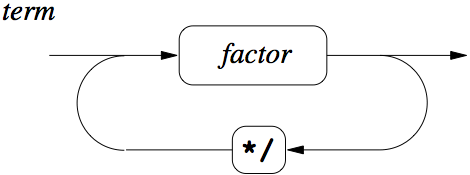
Figure 5: Term

Figure 6: Factor
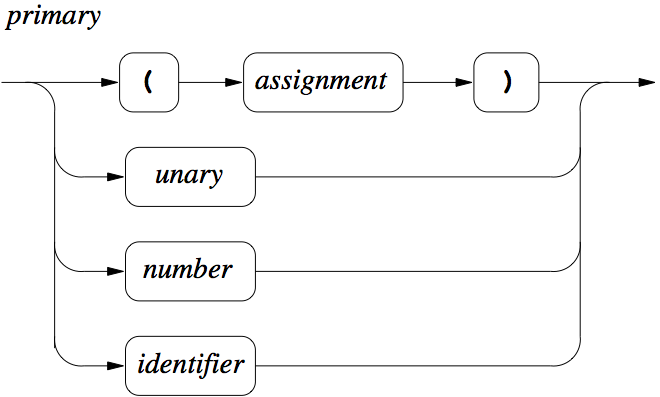
Figure 7: Primary
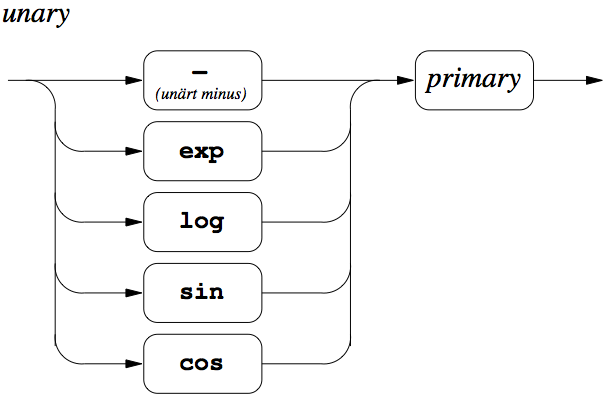
Figure 8: Unary
5 Important Concepts
Before we start discussing the implementation, let us first discuss two key concepts: parsing and abstract syntax trees.
5.1 Parsing
Parsing is the process of analysing a string of symbols conforming to the rules of a formal grammar.
The mathematical expression
sin x + 5*a - 3*(u+1) = z = t
is represented by the following parse tree:
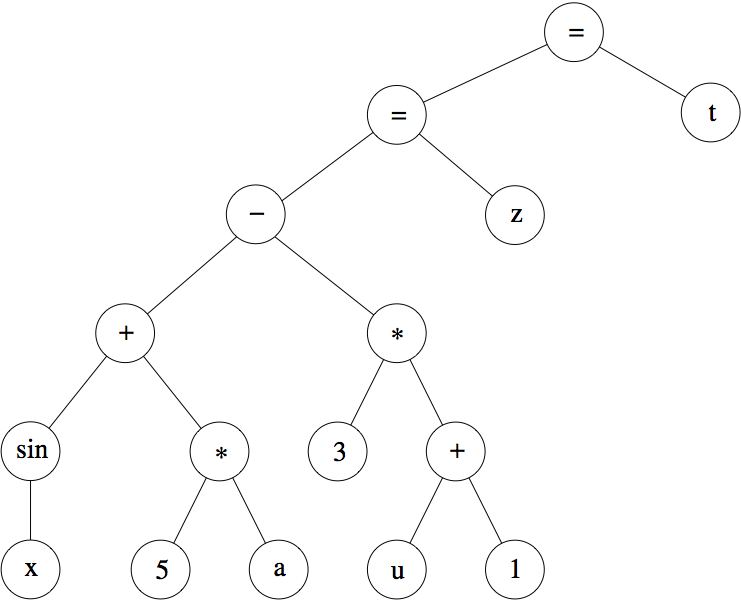
Figure 9: The representation of sin x + 5*a - 3*(u+1) = z = t in the form of an abstract syntax tree.
Note that the tree implicitly encodes evaluation order. In order
to perform the top-level assignment to t, we need to calculate
the value to be stored into t (the LHS of the assignment). This
means calculating the inner assignment to z, which means
calculating its LHS. This keeps repeating until we reach the
leaves. If we start at the leaves and move up, we can see that if
we know the value of x, we can calculate sin x (otherwise,
sin x evaluates to sin x) and so on for 5 * a etc.
5.2 Abstract Syntax Tree
As discussed above, parsing an expression results in the creation of a tree of objects that is the internal representation of the expression. This abstract syntax tree is good for many operations, including evaluating the expressions.
Each node in the tree represents either an operator (e.g., +),
function (e.g., sin), variable (e.g., x) or constant (e.g.,
42).) Variables and constants will be stored in leaf nodes,
which capture that they are “atoms”, that can be evaluated
immediately. Operators and functions will be stored in non-leaves.
Subtrees represent subexpressions that must be evaluated before
the whole expression can be evaluated.
The node objects will be instances of the following concrete classes, that represent the different type of expressions:
- The class
Varsfor the commandvars. - The class
Quitfor the commandquit. - The class
Variablefor variable identifiers. - The class
Constantfor numbers like 42 or 3.14. - The classes
Sin,Cos,Exp, andLogfor unary functions. - The class
Negationfor negations of expressions like -42 or -x. - The classes
Addition,Subtraction,Multiplication, andDivisionfor the binary operations. - The class
Assignmentfor assigning expressions to variables.
To construct a class hierarchy, additional abstract classes are added:
- The class
SymbolicExpressionis the root of our class hierarchy. We need this class to declare what methods one can expect from all nodes in the tree and to define common default behaviour for all expressions. By havingSymbolicExpressionat the top, all expression objects will be is aSymbolicExpression, meaning that the Java compiler will allow any expression to be stored in a variable of typeSymbolicExpression. Binaryis the common superclass of all binary operations (Addition,Subtraction,Multiplication,DivisionandAssignment). All binary expressions have in common that they have two subtrees – one to the left of the operator, and one to the right.Unaryis the common superclass of all unary operations (Sin,Cos,Exp,Log, and -Negation). All unary expressions have in common that they have one subtree, the expression operated on by the unary operator or function.Atomis the common superclass of all terminal expressions, i.e., the ones without a subexpression.Commandis the common superclass of all commands,VarsandQuit, which are not expressions, and are not evaluated to a value.
It may be confusing to some that there are two kinds of trees in this assignment. The abstract syntax tree is built out of objects and represents an expression in the language of the symbolic calculator. Unary and binary expression objects aggregate their subtrees. The AST is the key data of the program, that the program explicitly manipulates.
The class hierarchy on the other hand is a hierarchy of classes
that describe the is a relation between classes. The class
hierarchy helps us modularise the logic for the expressions, e.g.,
describe common aspects of binary expressions in a single place
(the Binary class). The class hierarchy is important for
software engineering – the principles for building and
maintaining software. The class hierarchy is not considered part
of the data that the program manipulates2
– but a structuring principle for the text (code!) of the program.
The classes Atom and Command have less immediate value in the
system as Unary and Binary. However, by creating them, the
class hierarchy becomes a lot more symmetric, which is nice. One
could make a YAGNI argument against them, but symmetry is nice and
the cost for having Atom and Command is very low.
6 Choosing Your Approach
You can go about this assignment in several ways. Here are the ways I considered as I wrote this up (not in any particular order):
- Parsing, AST, Integration – Steps A, B and C in that order
- AST, Parsing, Integration – Steps B, A and C in that order
- Two persons could theoretically do steps A and B in parallel (note that you still need to understand all parts!), and then collaborate on C (which covers both parts)
- Flip back and forth between steps in A and B, and then do C
Parsing is very much about algorithms, whereas the AST is more about data structures. Most object-oriented concepts are demonstrated in B and C.
The parsing part of the assigment is by example, and is not broken down into multiple steps. The AST and Integration parts are step-based, like Assignment 1.
6.1 Packages
Java divides code into packages, which can be used for modularisation and encapsulation. We are going to use three packages:
org.ioopm.calculator.ast,org.ioopm.calculator.parser, andorg.ioopm.calculator
The first package will contain all classes that are part of the
AST (meaning all classes that we are currently concerned with).
The second package will contain the parser logic. The third
package will contain all other classes. Start each class in the
AST with package org.ioopm.calculator.ast; (and similar for
parser classes and all other classes when we get there).
Writing software with multiple packages
Note that if you have a class that wants to use a class from
another package (except for java.lang), you must import that
package explicitly. For example, if you create a small test
class in Test.java and want to play around with AST classes,
you will have to write import org.ioopm.calculator.ast.*;
at the top of Test.java (or place the file in the same
package, but that is a bit weird).
Example:
package foo.bar; public class Foo {}
import foo.bar.*; public class Test { foo.bar.Foo foo; /// always works because we give the absolute name of Foo Foo foo; /// yields a "duplicate class error" unless Foo is imported (like it is here) }
7 Parsing the Calculator’s Language
We are going to implement the parser using a technique called recursive descent. If we were developing this program not as a learning experience, we would have used some form of parser library or parser generator instead. However, these are often quite complicated because they also support much more complicated languages, so it is not clear that this would be simpler at all.
The parser is not very object-oriented and would be quite similar
if it was written in e.g., C. All the code for the parser will be
written inside a single class CalculatorParser. There will roughly a 1–1
mapping between methods and grammar rules.
The parser’s constructor will create a new parser object. The
state of the parser object is a StreamTokenizer object – a
helper object for parsing strings, that allows us to read strings
“one token at a time”. This object will be created anew for each
call to the parse() method, so the constructor can leave this
object as null.
7.1 Example-Based Instructions
To prepare you for writing a parser of your own, you are invited to study a somewhat simpler parser for a simpler language:
expression ::= term
| addition
| subtraction
addition ::= term + expression
subtraction ::= term - expression
term ::= factor
| factor * term
factor ::= number
| '(' expression ')'
Here are some valid expressions in this language:
42 42 + 0 ( 42 ) 42 * 42 + 12 - 8 * 5
The first example is parsed like this, read this is conjunction
with the code of the ParserExample below.
- We try to parse an expression, and try to read a term
- In the term rule, we try to read a factor
- In the factor rule, we check that we are not looking at a
(meaning, we try to read a number- In the number rule, we successfully read a number and return
- Since we are only trying to read a number, we can simply return
- In the factor rule, we check that we are not looking at a
- Back in the term rule, we see that the number is not followed by a
*so we return
- In the term rule, we try to read a factor
- Back in the expression rule, we see that the number is not followed by a
+so we return
Here is the code for ParserExample. Note that in addition to
parsing expressions, the expressions are also evaluated. This
code uses a StreamTokenizer tied to System.in – this is not
great for testing, because it only reads input from the terminal,
as opposed from a string. The tokenizer allows us to treat the
input as a stream of tokens, so that we can access elements in the
stream at a higher level of abstraction. When nextToken() is
called on the StreamTokenizer, it will read an entire token from
the stream, which may be a number, like 42, or a symbol, like
+ or (.
The code below uses the following methods and fields, which you are invited to read up on in the Java documentation:
ordinaryChar()– used to mark certain characters as ’ordinary’, which is related to the default configuration of the tokenizereolIsSignificant()– whether we ignore end of line or treat it as a tokennextToken()– parse the next token in the stream, setting the valuesttypeandsvalornvalas a result (depending on the token read)pushBack()– push back the last read token onto the stream (allows looking ahead)ttype– a field that indicates what kind of token was just parsedsval– a field that holds a string value which is defined ifttype == TT_WORDnval– a field that holds a number value which is defined ifttype == TT_NUMBERTT_NUMBER– a constant indicating that a number token has been read
/// File ParserExample.java import java.io.StreamTokenizer; import java.io.IOException; public class ParserExample { private final StreamTokenizer st = new StreamTokenizer(System.in); public ParserExample() { /// We want to treat - and end of line as an ordinary tokens this.st.ordinaryChar('-'); /// parse object-oriented as "object" - "oriented" :) this.st.eolIsSignificant(true); } /// This is the top-level expression -- the "entry point" public double expression() throws IOException { /// Read a term and make it the current sum double sum = term(); /// Read the next token and put it in sval/nval/ttype depending on the token this.st.nextToken(); /// If the token read was + or -, go into the loop while (this.st.ttype == '+' || this.st.ttype == '-') { if(this.st.ttype == '+'){ /// If we are adding things, read a term and add it to the current sum sum += term(); } else { /// If we are adding things, read a term and subtract it from the current sum sum -= term(); } /// Read the next token into sval/nval/ttype so we can go back in the loop again this.st.nextToken(); } /// If we came here, we read something which was not a + or -, so we need to put /// that back again (whatever it was) so that we did not accidentally ate it up! this.st.pushBack(); /// We are done, return sum return sum; } /// This method works like expression, but with factors and * instead of terms and +/- private double term() throws IOException { double prod = factor(); while (this.st.nextToken() == '*') { prod *= factor(); } this.st.pushBack(); return prod; } private double factor() throws IOException { double result; /// If we encounter a (, we know we are reading a full expression, so we call back up /// to that method, and then try to read a closing ) at the end if (this.st.nextToken() == '('){ result = expression(); /// This captures unbalanced parentheses! if (this.st.nextToken() != ')') { throw new SyntaxErrorException("expected ')'"); } } else { this.st.pushBack(); result = number(); } return result; } private double number() throws IOException { if (this.st.nextToken() == this.st.TT_NUMBER) { return this.st.nval; } else { throw new SyntaxErrorException("Expected number"); } } } /// File SyntaxErrorException.java public class SyntaxErrorException extends RuntimeException { public SyntaxErrorException() { super(); } public SyntaxErrorException(String msg) { super(msg); } }
Here is an old screencast that covers parsing with recursive
descent. This film was recorded many years back and may make
references to old facts about the course. To run the code above,
you need a driver that creates a parser and calls its
expression() method:
/// File: ParserDriver.java import java.io.IOException; class ParserDriver { public static void main(String[] args) { Parser p = new Parser(); System.out.println("Welcome to the parser!"); System.out.print("Please enter an expression: "); try { double result = p.expression(); System.out.println("result: " + result); } catch(SyntaxErrorException e) { System.out.print("Syntax Error: "); System.out.println(e.getMessage()); } catch(IOException e) { System.err.println("IO Exception!"); } } }
7.2 Steps A1–An: The CalculatorParser Class
We are going to write our parser in the class CalculatorParser.
It should be located in the package org.ioopm.calculator.parser.
It will look quite similar to the code above, but the language is
more complicated so the code will have more cases and more
methods. Also, we are not going to calculate the expressions in
the parser – we are going to build up abstract syntax trees which
are evaluated later. As a consequence, the methods in the
CalculatorParser will return objects of type
SymbolicExpression instead. If you haven’t written such a class
yet, go ahead and define it, so we can write code and get it to
compile. For now, the class can be mostly empty:
package org.ioopm.calculator.ast; /// could place this in parser *for now* public abstract class SymbolicExpression { private String name; private String[] subExpressions; /// The second argument allows us to pass in 0 or more arguments public SymbolicExpression(String name, Object... subExpressions) { this.name = name; this.subExpressions = new String[subExpressions.length]; for (int i = 0; i < subExpressions.length; ++i) { this.subExpressions[i] = subExpressions[i].toString(); } } /// Returns e.g., "Constant(42)" if name is "Constant" and subExpressions is ["42"] public String toString(String msg) { StringBuilder sb = new StringBuilder(); sb.append(this.name); sb.append("("); for (int i = 1; i < this.subExpressions.length; ++i) { sb.append(this.subExpressions[i]); if (i + 1 < subExpressions.length) { sb.append(", "); } } sb.append(")"); return sb.toString(); } }
Now, whenever we arrive at a point in the parser where we should
be creating a SymbolicExpression object, we can create them
using the SymbolicExpression class. This helps us come back
later and replace those places in the code, once we have the
classes in the abstract syntax tree. For example, here is a
possible implementation of the expression() method:
public SymbolicExpression expression() { SymbolicExpression result = term(); while (st.ttype == '+' || st.ttype == '-') { int operation = st.ttype; st.nextToken(); if (operation == '+') { result = new SymbolicExpression("Addition", result, term()); } else { result = new SymbolicExpression("Subtraction", result, term()); } } return result; }
Eventually, we will replace code like
result = new SymbolicExpression("Addition", result, term());
with the creation of an actual addition node, like this:
result = new Addition(result, term());
If you already created the AST nodes, you might want to opt for this solution from the start, but on the other hand, it might be nice to only debug one part of the code at a time.
7.3 A Word on Parsing Identifiers
Allowing keywords (commands) like quit and vars to be parsed as
identifiers is not great as illustrated by the following example:
? 42 = id id
If id is a non-keyword, like x, this program sets the varible
x to 42.0 on the first line and then prints the contents of the
variable on the second. If id is quit, the first line sets the
variable quit to 42.0 on the first line and then – rather than
printing the contents of the variable on the second, quits the
program!
To handle that problem, keywords should not be valid identifiers. That can be handled in the rule for parsing an identifier, e.g. by checking a just parsed idenfifier against a set of known keywords and throwing an exception if the identifier happens to be in that set.
7.4 A Better Stream Tokenizer
In the parser that you are going to write, we are going to avoid
connecting the tokenizer directly to System.in. Instead we are
going to use a StringReader that creates a stream from an
ordinary Java string.
Here is how it can be done:
... = new StreamTokenizer(new StringReader("42 + 4711"));
This creates a new tokenizer object, that reads from the
underlying string reader which reads from the underlying string
"42 + 4711". Replace the string literal with a string passed in
to the parse() method in the CalculatorParser class.
If you find the instructions above hard to grasp, then maybe you want to start with the implementation of the AST instead. This might serve to better give you an idea for how the code should be structured.
7.5 Basic Makefile [Instruction Repeated Below]
Make is not a good program to use for Java because make expects a 1-1 relation between code files and object-files. This might not be the case in Java, which makes it hard to use makefiles as elegantly as with C. Feel free to use somemthing more fancy, but for simplicity, we will stick with make.
The following makefile is going to sustain us for the rest of this assignment, unless you want to extend it to better fit your workflow (note that this makefile assumes all Java sources are in the same directory – it is otherwise quite common to have a directory structure that matches your package structure):
all:
javac -d classes *.java
run:
java -cp classes org.ioopm.calculator.Calculator
clean:
rm -rf classes
This makefile has three targets, which we discuss below. Note that the targets have no dependencies, so we will always recompile the entire program, not just the parts that have changed.
- all – compile all Java source files in the current directory
and store them in the directory
classeswhich will be created unless it exists. Once you have compiled your program, take a peek inside theclassesdirectory and explore the output of the Java compiler. If we did not specify the-dflag, the result of the compilation would end up in the current directory. - run – run the compiled program by loading the class
org.ioopm.calculator.Calculatorand execute itsmain()method. The-cpflag sets the classpath of the Java VM to theclassesdirectory in the current directory. Thus, it will expectclasses/org/ioopm/calculator/Calculator.classto exist (note how packages names map to directory structures). - clean – toss the entire
classesdirectory and all its contents. The-rfflag stands for recursive (meaning class, and its subdirectories) and force (meaning don’t ask – just delete).
7.6 Finish These Steps
- Implement the parser following the instructions above. Ask for help if you get stuck (as always).
- Develop a set of tests, ad hoc or more proper ones (that you do not need to check for correctness ocularly) to help you catch bugs. Also test that syntactic errors lead to exceptions being thrown.
- Make a commit and push it to GitHub. After the normal push, add
a tag
assignment3_stepA(be careful to spell it just like that) and push the tag to the server by adding--tagsto thegit pushcommand. If your partner wants to pull the tag, he or she needs to add a--tagsto thegit pullcommand, but if you were careful to have a commit which was just a tag, then having that synced is not important.
8 Implementing the AST
8.1 Step B1: Skeleton Class Hierarchy
In this step, we are going to create the class hierarchy outlined
above. Java mandates that we use one file per class, and that the
file is named like the class, so the class Sin will have its own
file named Sin.java, etc.
So far, let us consider only a few aspects of the class hierarchy: inheritance, abstract vs. concrete classes, and fields.
8.1.1 Inheritance
For each class in the hiearchy except the root class, add an
explicit inheritance relation. For example, the Sin class is a
unary function, so a kind of a unary expression meaning the Sin
class is a subklass of Unary.
public class Sin extends Unary {
8.1.2 Abstract Classes
Mark all abstract classes abstract. For example, the
SymbolicExpression class is abstract:
public abstract class SymbolicExpression {
8.1.3 Aggregation
From the description above, it should be mostly clear what classes
create objects with subtrees. Subtrees are stored in fields in the
objects created from the expression classes. Because a subtree can
be an arbitrary expression, we cannot statically know its exact
type – for example in the binary expression 5 + 37, both
subtrees are constants, but in x + y, both subtrees are
variables.
Luckily, here is where inheriance and subtype polymorphism comes
to the rescue. For example, both the Variable class and the
Constant class are subclasses of the Atom class, meaning we
could use Atom as a type of a field holding sometimes variables
and sometimes classes.
However, 5 + (37 * x) is also legal and here, the left and right
subtrees are of different kinds, and the right subtree is not an
atom (it is some concrete subclass of Binary). Applying the same
reasoning, we can see that there is a common superclass of both
atoms and binary expression: SymbolicExpression. Now we have
reached the root class of our expression tree and so any
expression object can be stored in a variable whose type is
SymbolicExpression.
So, concretely, as the Binary class represents expressions with
a left and a right subtree we can write like this in the Binary
class:
public class Binary extends ... { private SymbolicExpression lhs = null; private SymbolicExpression rhs = null;
where lhs and rhs are common abbreviations for left-hand side
and right-hand side respectively.
Note that this technically allows ill-formed expressions such as
quit + vars, but the grammar of the calculator language excludes
these, and a correct parser will give a parse error for this.
Further, note the use of the private access modifier above! This
keyword means that only the binary class itself should be able to
access its lhs and rhs fields. This may be overly restrictive,
but it is better to start like that and lift this restriction when
and if the need arises than the other way around.
8.1.4 Additional Data
Variable objects need to store the identifier of the variable,
e.g., "x". For this, we can use the type String. A suitable
name for the field is identifier and we start with private as
always.
Similarly, Constant objects need to store their constant values.
Since we have said that all values are floating point values, we
can choose double as the type for this field, value as the
name and make it private.
8.1.5 Basic Makefile [Instruction Repeated Above]
Make is not a good program to use for Java because make expects a 1-1 relation between code files and object-files. This might not be the case in Java, which makes it hard to use makefiles as elegantly as with C. Feel free to use somemthing more fancy, but for simplicity, we will stick with make.
The following makefile is going to sustain us for the rest of this assignment, unless you want to extend it to better fit your workflow (note that this makefile assumes all Java sources are in the same directory – it is otherwise quite common to have a directory structure that matches your package structure):
all:
javac -d classes *.java
run:
java -cp classes org.ioopm.calculator.Calculator
clean:
rm -rf classes
This makefile has three targets, which we discuss below. Note that the targets have no dependencies, so we will always recompile the entire program, not just the parts that have changed.
- all – compile all Java source files in the current directory
and store them in the directory
classeswhich will be created unless it exists. Once you have compiled your program, take a peek inside theclassesdirectory and explore the output of the Java compiler. If we did not specify the-dflag, the result of the compilation would end up in the current directory. - run – run the compiled program by loading the class
org.ioopm.calculator.Calculatorand execute itsmain()method. The-cpflag sets the classpath of the Java VM to theclassesdirectory in the current directory. Thus, it will expectclasses/org/ioopm/calculator/Calculator.classto exist (note how packages names map to directory structures). - clean – toss the entire
classesdirectory and all its contents. The-rfflag stands for recursive (meaning class, and its subdirectories) and force (meaning don’t ask – just delete).
8.1.6 Get it to Compile
Now it is time to get this all to compile. Use the make file. Read the output of the compiler. Fix the bugs. Try again.
Once you get this to compile, there is no working program (yet), but a working class hieararchy that mostly consists of empty classes and their inheriance relations and some fields. Now that we have a system that compiles, we can extend it bit by bit and use the makefile to catch early bugs as we go.
8.1.7 Finish this step
- Declare all the classes in the AST, one class per file. If you
find switching between multiple buffers annoying, you can have
all AST classes in a single file (only making one, e.g.,
SymbolicExpressionpublic), and later splitting this file into multiple files and making all classespublic. - Add the
extendsrelation between the classes. - Make classes which do not correspond to expressions in the language
abstract(e.g.,SymbolicExpressionandBinary). - Add the correct subtrees to the classes following the language of the calculator.
- Add other variables needed to the classes. Make all instance variables
private. - Create a basic makefile unless you haven’t already done so.
- Make sure the code compiles correctly.
8.2 Step B2: Adding Constructors
In this step, we will add constructors to the classes in our hierarchy. If you are new to constructors, or is not familiar with Java’s rules for constructor naming and chaining, or default constructors, you should read the below primer on constructors.
8.2.1 A Brief Primer on Constructors
Constructors are special methods that are run only once when an
object is created. Different programming languages treat
constructors differently – in C we had to call them explicitly,
but in Java they are called automatically. Moreover – it is not
even possible to create an object without running at least one of
its constructors. This means that constructors can be used to
establish invariants, e.g. “this field is never null” or, “the
sum of all fears always add up to 42”.
Constructors thus have special rules in Java that do not apply to normal methods. First, constructors must always be named exactly like the class in which they appear. Second, a class must always have a constructor, even if Java must add it itself. As a running example, consider the following class hierarchy:
class A { private int a; } class B extends A { } class C extends B { } ... C = new C(); // OK!
Let’s say that the designer of A decides that when we create an
A, we must set its a field to a positive number. This can be
enforced by adding a constructor to A that raises an error if
a < 0.
class A { private int a; public A(int a) { if (a < 0) { throw new IllegalArgumentException("a must be > 0"); } this.a = a; /// this.a is the field, a is the argument! } }
Now we can write new A(42) (or new A(-42), which throws an
exception), but we can no longer write new C() like before.
Actually, we cannot even compile the classes B or C. The
reason for this is that all B’s and C’s are A’s (because of
the inheritance relation). This means that whenever we create a
new B (or C), we are also creating a new A, which means
we must call its constructor!
Solution (for B):
class B { public B(int a) { super(a); /// This calls A's constructor! } }
With this class in place, we can do new B(x) and have the value
of x be forwarded to the constructor of A so that we can
establish the invariant a >= 0 in A. We must also do the same
for C. However, we could imagine that the designer of C solves
this differently:
class C { public C() { super(42); /// This calls B's constructor! } }
Now, new C() works again, because its constructor now calls
B’s constructor with the constant 42 get’s forwarded to A’s
constructor. So, in this example every instance of C is an
instance of A whose a field always has the value 42.
Note that the call to a superclass’ constructor using super()
must always happen on the first line of the forwarding
constructor. The reason for this is that Java tries to prevent you
from operating on the object until it has been properly
initialised. Thus, because the super calls always happen first,
the constructor of A is guaranteed to have finished before the
constructor of B runs etc.
Actually, when you leave out constructors from your classes, the Java compiler will add a so-called default constructor in. This is what the Java compiler actually compiles for the initial class hierarchy.
class A { private int a; public A() {} } class B extends A { public B() { super(); } } class C extends B { public C() { super(); } }
8.2.2 Adding Constructors
Now it is time to add constructors to our AST classes.
- Remember that a constructor for class
Cmust be namedC - Always make constructors
publicuntil there is a reason not do so (we will see an example later) - It is common to overload constructors to give different ways to create an object
When you are done with this step, it should be possible to create instances of all concrete (i.e., non-abstract) classes in the AST and have their fields properly initialised.
When we create objects from our AST classes, we are going to want
to pass in values to initialise the fields. For example, here is a
constructor for Constant:
public Constant(double value) { /// Does it need to call super? this.value = value; }
Note how we distinguish the field named value from the argument
named value by prefixing the former with this..
Technically, if the argument value was named differently,
value would mean the field. In this course, I am going to write
this. explicitly (except when I forget) to make it clear that an
assignment changes or accesses the current object in some way.
8.2.3 Finish This Step
- Add constructors for all classes
- Consider what classes do not need a constructor (when the default constructor is enough) and what classes’ constructors need to call their superclass’ constructor.
- Make sure that the code compiles using your makefile
8.3 Step B3: Adding Simple Methods
8.3.1 Add method isConstant()
Later, when we evaluate expressions, we are going to want to know whether an expression is a constant or not. There are several ways to do this. First, the wrong way:
if (expr instanceof Constant) { ... /// We only come here is expr points to an object whose /// class C inherits from Constant (in 0 or more steps) }
This exemplifies something we could not do in C! We can ask an
object about itself. In this case, we test if its class is a
subclass of Constant (including Constant itself).
The reason why this is bad is because it is bad practise to hard
code a class name into the source code. For example, there might
be – perhaps as the result of a future addition – other classes
in the hierarchy which are effectively constants too, without
being subclasses of Constant. Thus, this test is to be avoided
unless it is absolutely necessary.
A better, and much more flexible way, is to add a method
isConstant() that returns true for constants and false
otherwise. Any class in the AST can implement this method such
that it returns true. We have now decoupled the concept of being
a constant from the class Constant which is great.
Since we want to be able to ask any expression whether it is a
constant or not, we should add isConstant() to the
SymbolicExpression class, and give it a default implementation
that returns false. This behaviour will be inherited by all its
subclasses, meaning that we will have to override it for those
classes where we want isConstant() to return true.
- Add at least two
isConstant()methods, including one inSymbolicExpressionthat returnsfalseand another one in a suitable place that returnstrue. Your end goal is that all objects that represent constant expressions (that do not need to be evaluated) should returntruewhen asked ifisConstant(). - Make the
isConstant()methodspublic.
8.3.2 Add method getName()
As part of printing expressions, we need to be able to get
operator names from expressions. As before, we want to add this
method to SymbolicExpression so we can call it on any
expression, even if we do not know its type.
The method getName() should return the operator name as a string
for expressions which have operators. For all other operators,
calling this method is an error.
Here is an example of getName() for the Sin class:
public String getName() { return "sin"; }
and another one for the Addition class:
public String getName() { return "+"; }
Since calling this method is an error for expressions which do not have operators, we can have those methods throw an exception. We will return to how exceptions work later, but for now, here is how to throw an exception and have the program crash nicely with a good stack trace and error message:
throw new RuntimeException("getName() called on expression with no operator");
Following the logic of before, add a default getName() behaviour
in SymbolicExpression that throws an error and override this
behaviour for the classes where an operator exists.
8.3.3 Add method getPriority()
In the program, we are going to want to print expressions. When we do so, we only want to print parentheses where they are needed, to avoid cluttering the output, for example:
(a + b) * (c - d)– here the parenthesis is needed, dropping it changes the meaning of the expression.(a * b) * (c / d)– here the parenthesis is not needed, so it should not appear in the printout of this expression.
The method getPriority() should return an integer number that
represent precedense order. When printing a binary expression, we
are going to check whether the priority of a subtree is lower than
the priority of the current operator, and if so, put parenthesis
around the subtree. For example, assume that multiplication and
division have priority 100 and that addition and subtraction have
priority 50. With these numbers, consider the printing of the
following AST:
*
/ \
+ *
/| |\
a b c d
Because 50 \(\lt\) 100, we are going to put parentheses around the left
subtree, but because 100 \(\not\lt\) 100. So this will be printed like so:
(a + b) * c * d.
We have two choices to implement getPriority():
- Add a
priorityfield toSymbolicExpressionand give it a default value (what?) Add a singlegetPriority()method toSymbolicExpressionthat simply returns the value of thepriorityfield. Then use the constructors of the expression classes for which you wish to alter the priority to set the priority number to a suitable value. - Add a
getPriority()method toSymbolicExpressionthat returns a constant default priority value (what?). Then override that method in the classes classes for which you wish to alter the priority to set the priority number to return a suitable value.
8.3.4 Add method getValue()
The getValue() method returns a constant’s value. Calling this
method on something which is not a constant causes an error. This
implementation follows a similar pattern as a previous method.
This method is going to be instrumental to implement evaluating
expressions. Evaluation is really reduction, i.e., we are
reducing the expression to simpler expressions, to the extent
possible. For example, we can reduce 5 + 37 to 42. If we
reduce 3 * x to an expression for which isConstant() returns
true, we can safely call getValue() to read its value.
8.3.5 Finish This Step
- Add the
isConstant(),getName(),getPriority()andgetValue()methods to the appropriate classes. Make thempublic. If you run into access problems due to your making all instance variablesprivateconsider adding methods in the super classes that allow “getting” the value of the variables, and if that is not enough, also “setting” their values. s - Think about whether there are cases where the implementation
of a method should call the super class’ implementation of
the method using the
super.methodName(args)notation. - Make sure that the code compiles using your makefile
8.4 Step B4: Creating a Small Test Expression
Time to create a small test expression! Let’s create the
expression (5 + x) * 2. This simple expression consists of 5
nodes: a multiplication node with an addition node as its
left-hand side and a constant as its right-hand side. The
addition’s left-hand side is a constant and its right-hand side a
variable. Here is how to construct it bit by bit:
Constant c1 = new Constant(5); Constant c2 = new Constant(2); Variable v = new Variable("x"); Addition a = new Addition(c1, v); Multiplication m = new Multiplication(a, c2);
Alternatively, and definitely less readable, we could write it like this, in a way that more closely resembles the structure of the AST:
new Multiplication(new Addition(new Constant(5), new Variable("x")), new Constant(2));
Create a new file Test.java with a public class Test with a
main() method. It will need to import
org.ioopm.calculator.ast.*; which gives it access to all the AST
classes. In the main method, create the above expression (5 +
x) * 2 and print it like so:
System.out.println("(5 + x) * 2 ==> " + m);
where m is the variable holding the root of the multiplication
tree.
Sadly, this does not print well. Java objects do not magically know how to represent themselves as strings, so we get some gobbledegook which we shall not go into here as output instead.
Create a bunch of other AST trees manually like above and print
them all. Still same gobbledegook for sure. Make sure to test
simple expressions (like new Constant(42)) as well as more
complex combinations.
Time to fix that gobbledegook! Time to move on to the next step –
but first, let us switch to a more test-driven approach. Convert
each print statement above call to testPrinting():
testPrinting("(5 + x) * 2", m);
where testPrinting() is the following method that you can paste
into your program:
public void testPrinting(String expected, SymbolicExpression e) { if (expected.equals("" + e)) { System.out.println("Passed: " + e); } else { System.out.println("Error: expected '" + expected + "' but got '" + e + "'"); } }
This program is now a proper test, and the goal of the next step is to make sure that the test passes without errors.
8.4.1 Finish This Step
- Implement the
testPrinting()method following the instructions above and use it in a bunch of tests of your own choosing. This code should live in its ownTest.javafile so you will need to make imports and/or packages to work correctly. - Make sure that the code compiles using your makefile.
- Make sure you can run the tests and that they all fail –
working success criteria for the following steps. Actually, you
can improve on the tests above by adding
assertstatements. They look a bit different in Java, and do not require any imports. However – they need to be enabled explicitly when the program is run. Time to edit the Makefile and make sure that there is a way to run the tests with assersions enabled. Writejava -helpon the command line to list the Java options. If your Java speaks Swedish, then you want to look for something like this: aktivera verifieringar med den angivna detaljgraden. There is a long and a short name for the flag that enables assersions, and as you can see from runningjava -help, you can turn them on and off for different packages or classes. Super nice! (The short name is-ea, but use the long name in the make file for enhanced readability.) - Note that it may not make sense to run with assertions on during test-driven development – now we are expecting tests to “blow up”.
8.5 Step B5: Printing Expressions
Time to print expressions. Printing expressions will be useful
e.g., to feedback errors to the user so that she may see how a
certain expression was parsed. For the printing, we will rely on
Java’s toString() method concept. Each method in Java
understands the toString() method, which returns a string
representation of the object. The default implementation is
inherited from java.lang.Object, Java’s root class, which means
that it will not do any good in almost all programs.
Whenever Java thinks that we want to get an object’s string
representation, it will automatically insert a call to
toString() unless we already did so explicitly. For example, in
System.out.println("Passed: " + e);, the compiler sees that we
are concatenating the string “Passed: ” with a non-string object,
so it automatically compiles this as System.out.println("Passed:
" + e.toString);. This is the reason why we wrote
expected.equals("" + e) instead of expected.equals(e) because
the latter will compare the string expected with the AST node
e, rather than the string representation of e. A slightly more
verbose way of saying the same thing is
expected.equals(e.toString()).
In this step, we are going to add toString() methods to several
classes in the AST. Explore how to do that in a postorder
traversal order, meaning start at the leaves. For example, here is
the toString() method for Constant:
public String toString() { return String.valueOf(this.value); }
Here is one for Unary, which exemplifies how a composite
expression (i.e., one built up of subexpressions) uses the
aggregated subtrees to calculate its value:
public String toString() { /// Note how the call to toString() is not necessary return this.getName() + " " + this.argument.toString(); }
This uses the getName() method from before to get the name of
the unary operator (e.g., “cos”) and a call to toString() on its
subtree (here called argument) to get its string representation.
In the end, a new string will be created from the three strings
and returned from the method.
Note that there is no need for abstract toString() methods
(every object has one inherited from java.lang.Object), or
toString() methods that throw exceptions since such errors will
be caught in testing anyway.
Experiment from the leaves up until your tests from before pass.
(If you did not take that step seriously, go back and do so before
coming back here again.) Take special care to catch the correct or
incorrect writing out of parentheses, which should rely on
getPriority().
8.5.1 Finish This Step
- Start by verifying that the assertion fails for the tests which are our success criteria for this step.
- Implement the
toString()method correctly for all classes. - Where possible/necessary, use
super.toString()for printing – never make a fieldpublicto make this work. - Make sure that the code compiles using your Makefile.
- Make sure that the tests from the previous step all pass!
8.6 Step B6: Adding Support for Equality Comparison
We are almost at the step of evaluating expressions. As we have said before, evaluation is reduction, and full reduction down to a constant is only possible if all variables store numeric values. For simplicity, we are going to take this in strides. (Later, we are going to redo how the evaluation happens.)
However, let ut start by extending the simple test from before. For the same expressions as you tested in printing, let us add tests for the evaluation.
We could do something like this (note that eval() comes in
later, but you may add a dummy for it now in the root class if you want):
public void testEvaluating(double expected, SymbolicExpression e) { SymbolicExpression r = e.eval(); if (r.isConstant() && r.getValue() == expected)) { System.out.println("Passed: " + e); } else { System.out.println("Error: expected '" + expected + "' but got '" + e + "'"); } }
However, that only works for expressions that are fully evaluated.
In the example above, of (5 + x) * 2, that is not going to be
the case, so already here the test seems to not work out.
To mirror the previous tests, it would be better if something like this was possible:
public void testEvaluating(SymbolicExpression expected, SymbolicExpression e) { SymbolicExpression r = e.eval(); if (r.equals(expected)) { System.out.println("Passed: " + e); } else { System.out.println("Error: expected '" + expected + "' but got '" + e + "'"); } }
This however requires that we teach AST nodes how to correctly perform equals comparisons with other objects.
Equality comparison in programming languages is important and
hard. In Java, like in C, it is easy to forget that == compares
identity and not equality for strings, for example. In
object-oriented programming languages, equivalence tests are
commonly implemented as a method call on one object, i.e.:
a.equals(b), asking a whether b is equivalent or not.
Because a.equals(b) looks up a definition of equality in a, it
is easy to end up in situations where a.equals(b) holds but
b.equals(a) does not! Whenever you implement equality, take care
to make sure equality is symmetric!
The equals() method in Java must be defined in a particular way:
public boolean equals(Object other) { ... /// implementation }
The reason why the type of argument is Object and not something
more specific is this:
String a = new String("Hello"); Object b = a; a.equals(b); /// asking a string if it is equivalent to an object a.equals(a); /// asking a string if it is equivalent to a string b.equals(a); /// asking an object if it is equivalent to a string b.equals(b); /// asking an object if it is equivalent to an object
It should be clear from the above that it we let the type of the
argument affect which method we dispatch to, then the same objects
may be compared differently depending on what we statically know
about the objects. That seems wrong and brittle and error-prone.
Thus, memorate the standard equals incantation of public boolean
equals(Object other).
An equals() method in a class C should follow the following pattern:
- Test whether if
other instanceof C– if not, returnfalse. This is a case where use ofinstanceofis reasonable because we always sayCinside the classCitself, so future changes are easily tractable. - If the test in 1. passed, then downcast
othertoCand store in a local variabletmp. - Compare the suitable values in
tmpwith the suitable values inthis. Note that inside a class, it is safe/allowed to access the private variables of another object of the same class. Returntrueorfalsedepending on the outcome of the comparison.
I often break case 3. out into a separate method which can take
C the type of its argument and call this method in conjunction
with 2.
Here is an example of 1–3 for constants:
public boolean equals(Object other) { if (other instanceof Constant) { return this.equals((Constant) other); } else { return false; } } public boolean equals(Constant other) { /// access a private field of other! return this.value == other.value; }
sFollowing the same strategy as with the printing, implement support for equals methods. Work from the leaves up, starting with constants and so on. For example, two unary trees are equivalent if their operators are equivalent and their subtrees are equivalent.
Now that we have equals() methods, we can compare two AST trees
with each other, meaning the method public void
testEvaluating(SymbolicExpression expected, SymbolicExpression e)
above now works.
Copy and patch the printing tests (or write new ones!) into
evaluation tests, manually reducing the expressions. Here is an
example call of testEvaluating() with a composite expression and
its expected reduction after evaluation.
SymbolicExpression a = new Assignment(new Constant(5), new Constant(37)); SymbolicExpression b = new Constant(42); testEvaluating(b, a); /// Tests if reducing a returns b (it should!)
Do not limit yourself to tests that fully reduce to a constant
since we added equals() methods in order to lift this
restriction. Feel free to take inspiration from the examples
further up these instructions since they are “authoritative”.
In the spirit of test-driven development, create a few tests using
testEvaluating() and then move to the next step, the goal of
which is to get these tests to pass.
8.6.1 Finish This Step
- Create a new set of tests isomorphic to the
testPrinting()ones using thetestEvaluating()method that you will also have to implement. - Implement the
equals()method correctly for all classes. Again, not thatequals()takes anObjectas argument, not aSymbolicExpressionor a subclass to that class. - Where possible/necessary, use
super.toString()for printing – never make a fieldpublicto make this work. - Make sure that the code compiles using your Makefile.
- Make sure that the new tests all fail which is to be expected since we have not implemented
eval()yet.
8.7 Step B7: Evaluating Expressions
Finally it is time to evaluate expressions! We already have our tests set-up for us (albeit a bit ad hoc) as the output of the preceeding step. First, we are going to dodge and implement support for evaluation without variables. Then once that is done, we will add variable support in.
8.7.1 The Method eval() – Without Variable Support
Evaluation happens in postorder traversal in the tree, meaning from the leaves up. This should not come as a surprise at this point, given that’s how we have done most things with the AST.
An expression is evaluated by calling the eval() method on its
top object (the root of the expression tree). What happens now is
decided by that object – different types of nodes will behave
differently. A constant is an atom and already knows its value. A
binary expression like + will have to recurse and call eval()
on its left and right subtrees before it can calculate its
resulting value. There is however one exception: assignment will
not evaluate its right subtree because that is always (in a
correct tree – the parser takes care of this) a variable to be
assigned, not to be evaluated.
Add a method public abstract SymbolicExpression eval(); to the
SymbolicExpression class. This method is abstract and must be
overridden in the subclasses. For commands, let eval() throw an
exception with the message that commands may not be evaluated. The
eval() method should attempt to reduce an expression maximally.
Some examples follow:
eval(new Constant(5))should returnnew Constant(5)eval(new Variable("x"))should returnnew Variable("x")eval(new Addition(new Variable("x"), new Constant(37)))should returnnew Addition(new Variable("x"), new Constant(37))(cannot be reduced)eval(new Addition(new Constant(5), new Constant(37)))should returnnew Constant(42)
You can look at Java’s Math class to see what functions are
available for some of the operations, for example to calculate
cos, we can use Math.cos().
Get this to work with your tests!
Here is an example of what eval() could look like in the Sin
class:
public SymbolicExpression eval() { SymbolicExpression arg = this.arg.eval(); if (arg.isConstant()) { return new Constant(Math.sin(arg.getValue())); } else { return new Sin(arg); } }
8.7.2 The Method eval() – With Variable Support
Now is the time to add variable support. We can keep track of
variables and their values by using a hash table. Java has a very
nice hash table implementation already in java.util.HashMap. You
can do import java.util.HashMap; to import it into your program.
Hashmaps are parametrically polymorphic. The type of a hashmap
that maps variables to symbolic expressions is this:
HashMap<Variable, SymbolicExpression>. This restricts all keys
to be of type Variable and all values to be of type
SymbolicExpression.
Extend the signature for eval() with HashMap<Variable,
SymbolicExpression> vars. This hashmap can be used as a simple
store where we use vars.put(a, b) to store a value b inside a
variable a and vars.get(a) to lookup the value for variable
a. Note that we now add side-effects to these programs!
In your test program, add a hashmap that you can pass in as
argument to all eval() calls. For example, you can do this:
HashMap<Variable, SymbolicExpression> vars = new HashMap<>();
Now you need to extend eval() in Assignment so that the
evaluated left-hand side is stored in the variable on right-hand
side using vars.put(...). Furthermore, in eval() in
Variable, you need to look up the variable’s value in vars. If
it is there, the variable v evaluates to vars.get(v),
otherwise it is as before. In all other cases, you will need to
propagate vars to all eval() calls on all subtrees.
You should now be able to run your tests fully and pass them.
Revisiting the eval() example in the Sin class, extended with
variables, here is what we could get:
public SymbolicExpression eval(HashMap<Variable, SymbolicExpression> vars) { SymbolicExpression arg = this.arg.eval(vars); if (arg.isConstant()) { return new Constant(Math.sin(arg.getValue())); } else { return new Sin(arg); } }
However, because HashMap<Variable, SymbolicExpression> is boring
to write, and because that class name isn’t very informative, let
us add a new name (and class!) to our program that improves on the
explanation:
public class Environment extends HashMap<Variable, SymbolicExpression> {}
This is an empty class that says that Environment is a hashmap
whose keys are Variables and values are SymbolicExpressions.
Think of this a bit like a typedef in C, except that whereas in C,
typedefs insert type equivalences, there is no equivalence here
– but an is a relation from Environment to HashMap<Variable,
SymbolicExpression>, not in the other direction!
8.7.3 Finish This Step
- Implement the
eval()method without support for variables as a first step. You can still use the tests to make this work. - Once you have a working
eval()without variable support, it is time to move on to this step.- First change the
eval()method to take the additionalEnvironmentargument. Because we are usingeval()intestEvaluating(), we are going to have to extend that method to also take anEnvironmentargument. - Make all the old tests running and passing again, by calling
them with an empty environment. Note that you should creat a
new
Environmentper call totestEvaluating()so that no side effects carry over between tests (once assignments start producing them!). - Now, extend your tests so that we have a working test for
eval()with support for variables. You most likely have a test from before that uses a variable, say something like(5 + x) * 2. If we evaluate this test using an environment in which the variablexis bound to8, the whole expression should evaluate to42.0. Write a test for this that creates a newEnvironmentand setsxto8and uses this as the argument totestEvaluating(). This should fail initially, because the currenteval()does not yet reduce variables to constants. - Because
Environmentis a map withVariablesas keys, we need to make sure that two different variable objects that both denote the same variable always return the samehashCode(). You can test this by printing the hash codes for two variables:System.out.println("a = " + a.hashCode() + "\nb = " + b.hashCode());. If your variable objecs hash differently when they should not, you can override thehashCode()method in theVariableclass and return thehashCode()of the underlying strings that hold the variable names. Strings are part of the Java library and therefore should uphold the property mentioned in the previous link that If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result.
- First change the
- Change
eval()so that the environment is propagated through evaluation. Importantly, change its definition inAssignmentto insert or update variables’ values, and inVariableso that a variable evaluates to its value in the current environment. - Make sure that the code compiles using your Makefile.
- Make sure that the new tests all pass.
If you suddenly get failing tests, it may be that you have tests that suddenly have side effects! Double-check for correctness, and update the tests if that is the case. Any test that defines a variable to the left of a use to that same variable on the right is a candidate for this happening.
Consider the quote above: /If two objects are equal according to
the equals(Object) method, then calling the hashCode method on
each of the two objects must produce the same integer result./ Do
we satisfy this? We did add new equals implementations so we may
need to override the default hashCode() behaviour for other
classes too. Note that nothing in the implementation other than
variables are stored in hashmaps, so you could omit this step and
hopefully never suffer.
8.8 Step B8: Implementing Commands
Commands work differently that normal expressions. Commands are never mixed with expressions, and should be evaluated differently.
When implementing commands, we can use something called the
Singleton Pattern, which is a technique to make sure that there is
only a single instance of a particular class in the entire
program. Here is an example of how this can be achieved for the
Vars class:
public class Vars extends Command { private static final Vars theInstance = new Vars(); private Vars() {} public static Vars instance() { return theInstance; } ... /// The rest of the code }
The second line above declares a field theInstance with three
modifiers: private, static and final.
The private keyword prevents the field from being accessed other
than from the class itself. Only within the start { and end }
of Vars may we access that field, or the program will not
compile.
The static keyword means that theInstance is a class variable,
not a normal instance variable. Instead of having one field
theInstance per object created from the Vars class, there is
only a single theInstance field shared between all the objects.
This is achieved by placing the field in the object that
represents the Vars class.
Finally, the final keyword means that once the field has been
initialised, its value will not change. Thus, there is only one
field theInstance with a constant value – a reference to a
Vars instance.
The third line declares an empty constructor for Vars. The key
feature with this constructor is that it is private. Like with
accesses to theInstance, we may only create new Vars within
the start { and end } of the Vars class itself.
Finally, likes 4–6 declare a class method that returns the
value of theInstance. Like with the theInstance field, the
static modifier makes the method part of the class, not part of
the object.
Now, to get hold of a reference to the only instance of the Vars
class, one can now simply write Vars.instance().
Also, add an isCommand() method to the class hierarchy that
returns true for all command and false otherwise.
8.8.1 Finish This Step
- Make all commands (
VarsandQuit) singletons, so that there are only one object of each class for each program. If you want to be defensive, you can add anassertto the constructors that trigger the second time the constructor is run to capture bugs that could cause multiple instances of a command to be created. - Add the
isCommand()method to the class hierarhy. Try to add it in as few places as possible. - Make sure the code compiles using your makefile, and that all the tests run and pass.
- Make a commit and push it to GitHub. After the normal push, add
a tag
assignment3_stepB(be careful to spell it just like that) and push the tag to the server by adding--tagsto thegit pushcommand. If your partner wants to pull the tag, he or she needs to add a--tagsto thegit pullcommand, but if you were careful to have a commit which was just a tag, then having that synced is not important.
9 Integration and Extension Part
We have now arrived at the last series of steps of the development
of the calculator program, which is the integration. In the A
series of steps, we developed a parser based on recursive descent
which conforms to the language of the calculator as given in this
specification. In the B series of steps, we defined the AST tree
as a hierarchy of classes rooted in SymbolicExpression, with
methods for printing, equality comparison, evaluation, etc. In
these step, we are going to extend and integrate these parts so
that:
- The calculator understands the new command
clearwhich will require both an extension of the AST and the parser - The calculator understands the concept of a named constant which will require both an extension of the AST and the parser
- The parser correctly generates an AST tree for any valid expression in the langauge
- Commands (
vars,quitandclear) are intercepted by the event loop of the main program, and not handled byeval() - All other commands are evaluated, using a hash map of variables stored by the main program
9.1 Step C1: Full Monty 1/2
In this step, we are going to extend the program with constants
of known value. You can think of these as being variables, except
that they are always defined and their values cannot change. Thus,
we cannot model constants as variables. (Otherwise, we could have
added a variable pi with a value of 3.14592654 from the start,
for example.) We are going to touch the AST, the parser and the
main program.
We could call such a constant a NamedConstant, and they behave
very much like constants, except that they have a name which they
will print. An instance of a NamedConstant needs to keep track
of its name, in addition to its value. This name can be passed in
as an argument to the constructor.
9.1.1 Preventing Constants to be Redefined
To prevent constants from being redefined, we could extend
eval() in assignment to check that its right-hand side is not a
named constant, and if so, throw an exception “Error: cannot
redefine named constant”. Alternatively, we could extend the
parser to give a syntax error if the name of a known constant
appears on the right hand side of an =. Because it lets us play
around a little with exception handling, we are going to choose
the first of these.
Given this design choice, we will need some way to check the
right-hand side inside assignment. Maybe we can use isConstant()
for that, or maybe not? You will have to figure that out. (You
could also just add an isNamedConstant() along the same lines as
isConstant() but it would be better not to if isConstant()
works so that we reduce the amount of code that must be
maintained.) When – during the evaluation – we find that we
are about to reassign a named constant, we are going to throw
an IllegalExpressionException exception. This is a new class
that you are going to write. It will look like this:
public class IllegalExpressionException extends ... { ... }
…and you throw it like this (in eval()):
throw new IllegalExpressionException(...);
If you are unclear about the consequences for the code between
checked exceptions and unchecked exceptions, I suggest that you
make Exception the superclass of IllegalExpressionException
and play along for a few minutes with what the compiler suddenly
complains about with respect to eval() and all methods that call
eval(). Think about whether this improves your code or not! Tip:
commit just before so you can easily revert to the previous state
if you feel the need.
If you change the superclass from Exception to
RuntimeException, all these errors go away, and the compiler
does not require any propagating changes to eval(). However,
we are no longer forced to catch IllegalAssignment,
or declare where they may appear and wreak havoc.
You decide: what should be the superclass of IllegalAssignment and why.
9.1.2 Extending the Parser
Obviously we need to extend the parser with support for
named constants. A named constant can be added as a case in
primary where we look for identifiers which are knowns strings
(e.g., pi). However, we want to be able to extend the number of
constants that we support in the program without having to
change the parser. To that end, we are going to want to have a
global set of known constants which the parser will access.
Let’s write a new class for this:
package ... import ... public class Constants { public static final HashMap<String, Double> namedConstants = new HashMap<>(); static { Constants.namedConstants.put("pi", Math.PI); Constants.namedConstants.put("e", Math.E); ... /// TODO: the rest of the constants, go wild! } }
The static block will be run at load-time, that is when the JVM
starts and loads this class into the program. This will add
entries in the hashtable that maps strings (“pi” in our example
above) to values (Math.PI above). Note that the Double above
is not a misspelled double – Java does not support primitive
types with parametric polymorphism. The solution is to use
Double instead of double, which means use an object holding
the double instead of a double itself. Java converts quietly
between double and Double so you mostly do not need to care
about this. Rule of thumb: use primitives when you can and their
corresponding object types only when you must.
Following this addition, we have, in the specialisation of primary
in the parser, a choice – either the identifier is in the set of
keys in Constants.namedConstants, in which case it is a constant
– or it is a variable name. Look in the Java API for the
HashMap API for how to check if something is in the map – it
should be familiar after Assigment 1.
For now, we want to support at least the following named constants:
piwhich evaluates to whateverMath.PIis defined asAnswerwhich evaluates to42Lwhich evaluates to \(6.022140857 \times 10^{23}\).ewhich evaluates to whateverMath.Eis defined as
Examples of uses of named constants:
$ Answer + Answer 84.0 $ 43 = Answer Error: cannot redefine named constant 'Answer'
9.1.3 Finish This Step
- Add a
NamedConstantclass with the appropriate methods. For each method that it inherits from its superclass(es) – think about whether it makes sense to override it and provide a more specific implementation. If so, also think about whether it makes sense to call the overridden method in the superclass as part of the more specific behaviour. - Add the extra exception class.
- Implement
eval()so that an exception is thrown on an attempt to redefine a named constant. - Extend the parser so that it parses at least the named
constants named above, using the
NamedConstantclass. Note that since we are using the name of the named constants, not the constant itself, as the key in the hash map, we avoid the issue withhashCode()inVariablethat we had before, with respect to theEnvironment. An alternative (better?) implementation onNamedConstantwould be to make the hashmap store instances ofNamedConstantinstead of doubles. That way, we could simply lookup our named constant objects from there, and also have to create fewer objects. - Add tests to your
Test.javafile – both for correct uses of named constants, and for attempts to reassign them that should result in exceptions being thrown. - Make a commit and push it to GitHub.
9.2 Step C2: Full Monty 2/2
In this step, we are going to extend the program with one more
command that was not in the grammar above: clear. The purpose
of the clear command is to clear all the variables, making them
undefined. The extended grammar looks thus:
command ::= *quit*
| *vars*
| *clear*
Since clear is a command, it does not get evaluated, and you can
follow the logic of the other commands to implement it.
Note that this command also needs to go into the parser!
9.2.1 Finish This Step!
- You don’t need instructions for this one. But don’t forget testing or committing!
9.3 Step C3: Integration of Parser and AST Tree in Main Program
Time to write a main program that runs this whole things. This
will be very simple. Essentially, the main program is an event
loop that runs until the user issues a quit command.
The main class should be called Calculator and its starting
point is the usual public static void main(String[] args). In
the main function, we want to obtain a handle to a console object
from which we can read strings, create a parser, create an empty
hashmap of variables, and then go into the event loop.
9.3.1 Create the Parser and the Variable Store
Create the parser object and the hashmap (Environment) for
holding the variables. They can be stored in a local variable on
the stack. We should not create a new parser everytime we want to
read a string, and the same variable store should be used
throughout the program. To make this more explicit, designate the
variables holding the parser and the variables as final. Final
is reminiscent of C’s const and simply means that the variables
cannot be reassigned.
(Note that you will need to do some import of classes for the variable store.)
9.3.2 Read input
The simplest way to get a handle to an object from which we can read strings from the terminal is this:
String input = System.console().readLine();
That will work fine.
9.3.3 Write the Event Loop
At least as a starting point, we can make this an infinite loop (you may dislike infinite loops and want to add other exit conditions, perhaps):
while (true) { /// Event loop code here! }
In the event loop, we want to do the following:
- Read a string from the console
- Feed this string into the parser and get back a
SymbolicExpressionobject - Branch on this object
- If it is a command, we need to do whatever it wants (quit the program, clear the variable list, or print the variable list)
- Otherwise, we want to evaluate the
SymbolicExpressionobject using the current variable list
- Go back to 1. and start over
In our case, quitting the program means breaking out of the loop,
which eventually terminates the main() method and we are done.
To check whether a parsed expression is a command or not in 3.
above, we can use the isCommand() method that you implemented in
Step B8. To learn what type of command in 3.1., we can rely on
identity comparison using the singleton instance() method on the
command classes.
In the even loop we also want to watch out for exceptions that may
arise. What parts of the system throw exceptions? How should they
be handled? For example, an IllegalAssignment aborts evaluation
and could probably be handled just by printing an error and going
around in the loop again. A parse error, on the other end, means
that we are not going to get an AST, so there is no point in going
on with the subsequent steps (we can simply recurse).
We should really implement evaluation so that if an expression throws an exception during evaluation, no changes to or additions of variables should be visible afterwards. There are several ways to do this, and the simplest possible way is to make a backup copy of the old variable state at the start of each loop, and restore the copy if there is an error during evaluation.
Also ponder what should happen if we get an exception that is
defensive in nature, like accidentally calling eval() on a
command That should not happen, and unlike IllegalAssignment
that is not an error on the user side that we cannot rule out –
it is a bug that we inserted. We should catch them so that the
program does not die with an ugly crash, but what should we do
then? Quit the program because clearly something is amiss, or
simply continue asking for a next expression?
9.3.4 Quitting
When the user quits, a nice message should be written to the
terminal, and statistics of how many expressions were entered, how
many were successfully evaluated, and how many could be fully
evaluated, e.g., down to 42.0 as opposed to 42.0 + a.
9.3.5 Finishing the Assignment
- Go over your backlog of cheats and dodges and see which ones need taking care of. Ideally this stack should be empty.
- Write up the documentation of your program, any extra
documentation needed because of design decisions you took or
deals made with the teachers. Put this in a
README.mdin the top-level directory for this assignment. - As the first section of
README.md, add instructions for how to build and run the program. Ideally, this should be as easy asmakefollowed bymake run. - Prepare a demonstration of z103 to give at the next lab. In addition to z103, pick another 2-3 achievements to tick off, and include these in your demonstration preparation. To back up your presentation, present evidence like places in your code where relevant things show up, documentation, paper drawings, etc. – things that support your demonstration. Think carefully about what things fit together (ask for help if you feel uncertain after trying) and what achievements tell a good story together. Make sure that not one person dominates the demonstration or answers all questions to avoid someone failing the demonstration because there was no evidence of achievements mastery.
- Send an email to z103@wrigstad.com with your names and usernames, a link to the GitHub repository where the code can be checked out.
- Create a final commit for the assignment and check it into
GitHub. After the normal push, add a tag
assignment3_done(be careful to spell it just like that) and push the tag to the server by adding--tagsto thegit pushcommand. If your partner wants to pull the tag, he or she needs to add a--tagsto thegit pullcommand, but if you were careful to have a commit which was just a tag, then having that synced is not important. - Optional Please take time to feedback on the assignment.
Note: Don’t expect any feedback on your program over what you have got from the oral presentations. If you want more feedback on specific things, ask questions in conjunction with your presentations, or add your name to the help list.
Questions about stuff on these pages? Use our Piazza forum.
Want to report a bug? Please place an issue here. Pull requests are graciously accepted (hint, hint).
Nerd fact: These pages are generated using org-mode in Emacs, a modified ReadTheOrg template, and a bunch of scripts.
Ended up here randomly? These are the pages for a one-semester course at 67% speed on imperative and object-oriented programming at the department of Information Technology at Uppsala University, ran by Tobias Wrigstad.