Project 2
Table of Contents
- 1. Inledning
- 2. Skräpsamling med mark–sweep (som vi alltså inte kommer att implementera)
- 3. Kompakterande skräpsamlare
- 3.1. Effektiv allokering och avallokering
- 3.2. Naiv implementation: Två minnesareor (eng. two-space)
- 3.3. En kompakterande, konservativ skräpsamlare för C
- 3.4. Konservativ kompaktering efter Bartlett
- 3.5. Allokeringskarta
- 3.6. Höga adresser
- 3.7. Allokering med metadata
- 3.8. Formatsträng för
h_alloc_struct
- 4. Implementationsdetaljer
- 5. Att skapa och riva ned en heap
- 6. Att hitta rötterna för skräpsamlingen
- 7. Gränssnittet
gc.h - 8. Enkla prestandamätningar
- 9. Integration med existerande program
1 Inledning
Uppgiften går ut på att utveckla ett bibliotek, för enkelhets skull kallat GC, för minneshantering i form av en konservativ kompakterande skräpsamlare. En användare kan skapa en “egen heap” – ett konsekutivt minnesblock1 – i vilket man sedan kan allokera minne. Allokeringar i den egna heapen skall sedan hanteras automatiskt – när minnet tar slut2 skall skräpsamling automatiskt triggas, och alla objekt i detta minne som inte är nåbart via någon rot i systemet tas bort3. Ett korrekt implementerat projekt kan (och skall – se under integration) integreras med ett existerande C-program – en inlämningsuppgift från tidigare del av kursen. I det förändrade programmet skall all allokering skall ske med hjälp av GC-biblioteket och ingen manuell avallokering skall ske, utan att programmets minne skall ta slut.
I detta kapitel beskrivs uppgiften. Av pedagogiska skäl beskriver vi först skräpsamling med hjälp av mark–sweep (och som redan beskrivits på föreläsning), som vi inte skall använda innan vi går in på den kompakterande skräpsamlaren som använder en liknande algoritm.
2 Skräpsamling med mark–sweep (som vi alltså inte kommer att implementera)
Skräpsamling med mark–sweep vandrar genom (traverserar) den graf som heapen utgör för att identifiera objekt som fortfarande används. Alla objekt som inte används anses vara skräp och kan frigöras utan att programmet kraschar. Vi går igenom algoritmen steg-för-steg nedan.
Vi kan tänka oss att varje objekt innehåller en extra bit4, den s.k. mark-biten. När denna bit är satt (1) anses objektet vara “vid liv”. Annars är objektet skräp som kan tas bort.
Vid skräpsamling sker följande (logiskt sett):
- Steg 1
- Iterera över samtliga objekt på heapen och sätter mark-biten till 0. Detta innebär att alla objekt anses vara skräp initialt.
- Steg 2
- Sök igenom stacken efter pekare till objekt på heapen – dessa pekare kallar vi också för “rötter” – och med utgångspunkt från dessa, traversera heapen och markera alla objekt som påträffas genom att mark-biten sätts till 1.
- Steg 3
- Iterera över samtliga objekt på heapen och frigör alla objekt vars mark-bit fortfarande är 0.
Steg 2 kallas för “mark-fasen” och steg 3 för “sweep-fasen”, härav algoritmens namn, mark–sweep.
2.1 Att traversera heapen
Att traversera heapen i C försvåras av att minnet som standard allokeras utan metadata. T.ex. allokerar detta anrop
void *p = malloc(sizeof(binary_tree_node));
void%20%2Ap%20%3D%20malloc%28sizeof%28binary_tree_node%29%29%3B%0A
plats som rymmer en binary_tree_node, det sparas ingen
information om innehållet i detta utrymme, mer än hur stort
utrymmet är som p pekar på. Vi skulle vilja “fråga” minnet
vilka pekare det innehåller och hur stort det är, men det kan vi
alltså inte göra. Vi måste själva implementera stöd för detta.
Rimligtvis har en binary_tree_node åtminstone två pekare till
höger respektive vänster subträd – så hur gör man för att hitta dem?
Ett sätt är att leta igenom det minne som pekas ut av p och
tolka varje möjlig sizeof(void *) i detta utrymme som en adress.
Om adressen pekar in i den aktuella heapens adressrymd5 anser vi att den är en
pekare till det objekt som finns lagrat där (observera att pekaren
inte måste peka på starten av det objektet). Då skall vi markera
detta objekt som levande (dess mark-bit sätts till 1), varefter
dess utrymme också letas igenom på samma sätt som
binary_tree_node:en i jakt på andra pekare in i den aktuella
heapen. Om ett objekt redan markerats och traverserats behöver man
inte göra det igen.
Men hur vet man då vilka pekare som finns som pekar in i heapen? För att hitta dessa, de s.k. “rotpekarna”, måste man leta igenom stacken efter pekare till heapen på samma sätt som ovan, alltså gå igenom hela stackens adressrymd, inklusive register och de statiska dataareorna och leta efter pekare in i heapens adressrymd.
2.2 Tillåtna förenklingar map. ovanstående
Vi tillåter flera förenklingar i denna uppgift – vi kräver inte stöd för pekare “in i objekt” (alltså som inte pekar till starten av ett objekt)6, eller scanning av den statiska dataarean7. Vi uppmuntrar förstås till stöd för dessa vanliga C-idiom, men det är inte nödvändigt. (Och ta inte itu med detta förrän resten av projektet är klart!)
Nu har vi sett hur man kan leta igenom både stacken och heapen efter pekare. Då skall vi titta på hur man kompakterar heapen i syfte att minska fragmentering.
3 Kompakterande skräpsamlare
En kompakterande skräpsamlare är en relativt vanlig skräpsamlartyp som vid skräpsamling flyttar samman objekt i minnet. Det finns åtminstone tre goda skäl till att göra detta:
- Det undviker fragmentering, eftersom allt använt minne och allt icke-använt minne ligger var för sig, konsekutivt.
- Objekt som pekar på varandra tenderar att hamna nära varandra vilket förbättrar minneslokaliteten hos programmet.
- Det ger möjlighet till en mycket effektiv implementation av allokering.
3.1 Effektiv allokering och avallokering
Om alla levande objekt flyttas samman vid allokering kommer allt ledigt minne att vara konsekutivt och vi behöver inte föra bok över var ledigt minne finns, vilket vore fallet för mark–sweep. Därför kan allokering implementeras med så-kallad “bump pointer”. Det går till så att man har en pekare till starten av det fria minnet, “fronten”, och att allokering av \(n\) bytes returnerar den nuvarande addressen till fronten, varefter fronten flyttas \(n\) bytes. Denna typ av allokering är betydligt snabbare än en implementation som söker bland en lista av fria block för att hitta ett av lämplig storlek.
Vidare, om vi enbart opererar på levande objekt och ignorerar skräp blir tidskomplexiteten \(O(\#\textrm{levande objekt})\) istället för \(O(\#\textrm{objekt})\). Det tillåter oss att skriva en implementation som undviker steg 1 och steg 3 i beskrivningen av mark–sweep ovan.
Det är inte ovanligt att 90–95% av alla objekt är skräp vid en skräpsamling8, så detta är en stor tidsvinst, även om kopiering är dyrt.
3.2 Naiv implementation: Två minnesareor (eng. two-space)
Vi kommer att implementera en variant av denna efter Bartlett.
Det enklaste sättet att implementera en kompakterande skräpsamlare är att dela upp minnet i två olika minnesareor, en passiv och en aktiv. Alla objekt finns i den aktiva arean, och all allokering sker där – den passiva arean används inte.
Om man fyller den aktiva arean triggas skräpsamlingen. Den utgår från samtliga rötter och traverserar samtliga levande objekt i den aktiva arean. Varje objekt som hittas på detta sätt kopieras över9 in i den passiva heapen, och vi noterar kopians adress10. Alla pekare vi hittar i under traverseringens gång ersätter vi med objektets forwarding-adress så att vi till slut kopierat över alla levande objekt från den aktiva arean till den passiva, och uppdaterat alla pekare mellan objekten så att kopiorna pekar ut varandra. På samma sätt uppdaterar vi också alla rotpekare att peka på kopiorna. (Hela detta motsvarar alltså steg 2 i beskrivningen av mark–sweep.)
När traverseringen och kopieringen är klar byter vi så att den passiva arean blir aktiv, och den aktiva passiv.
Vad vi har åstadkommit nu är alltså att alla objekt innan skräpsamlingen finns i den numer passiva arean och betraktas som skräp. Endast de objekt som programmet kunde nå har flyttats över in i den nya aktiva arean vilket betyder att den använder minsta möjliga minne som fortfarande garanterar att programmets alla pekare är korrekta.
Notera att uppdelningen av minnet i två areor varav endast den ena är i bruk vid varje givet tillfälle (förutom vid skräpsamlingen då båda används) effektivt dubblar ett programs minnesanvändande. Detta har inte hindrat denna teknik från att användas i praktiken; de flesta program använder relativt lite minne, och smidig och korrekt minnesanvändning är ofta viktigare än yteffektiv. (Generationsbaserade skräpsamlare där flera olika skräpsamlingstekniker kombineras kan också hjälpa till att minska “slöseriet” med minne.)
Bilderna nedan visar en naiv implementation av en kopierande skräpsamlare. Minnet är indelat i två areor, en aktiv och en passiv. När skräpsamling triggas kopieras alla levande objekt över från den aktiva till den passiva arean, varefter den passiva arean blir aktiv och den aktiva passiv. Notera att i den nya aktiva arean är objekten kompakterade, dvs. lagda intill varandra. På detta vis undviks minnesfragmentering.
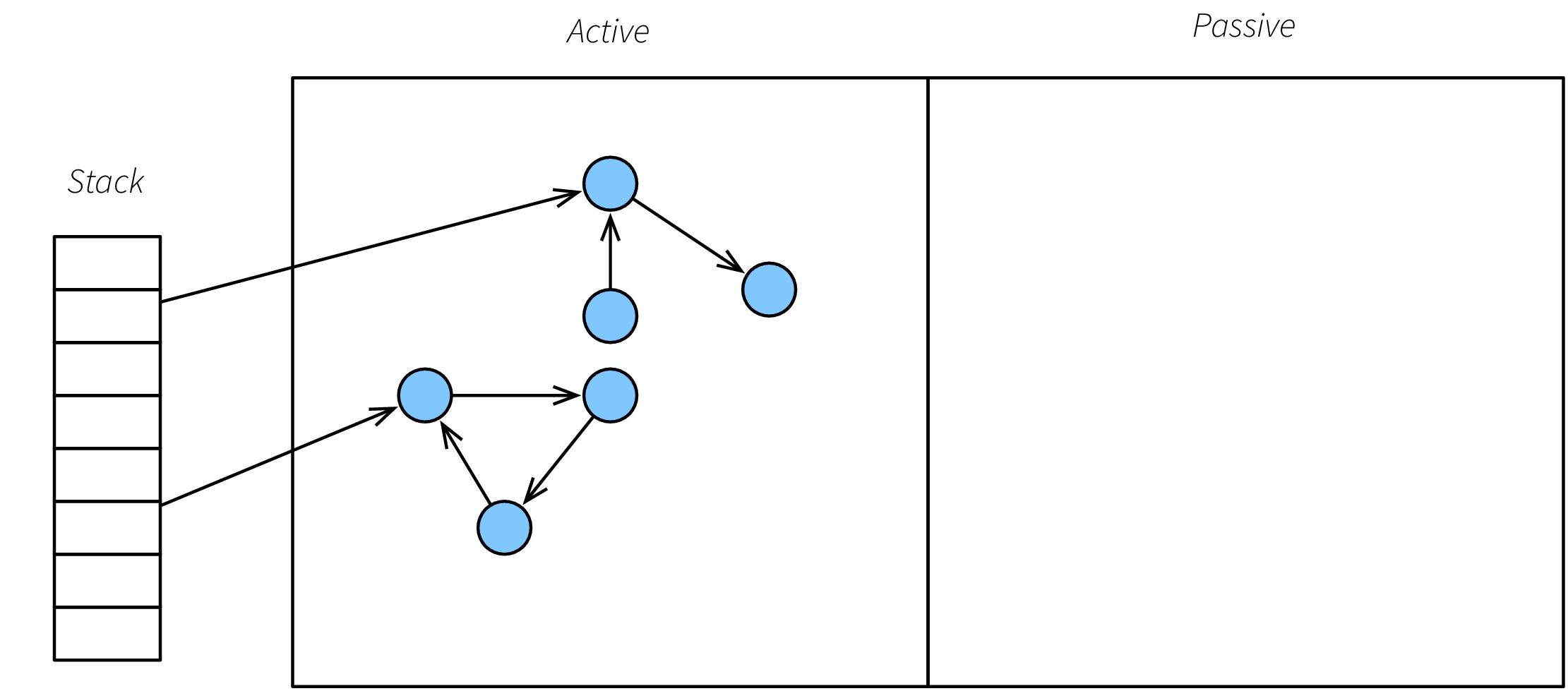
Figure 1: Precis innan skräpsamling.
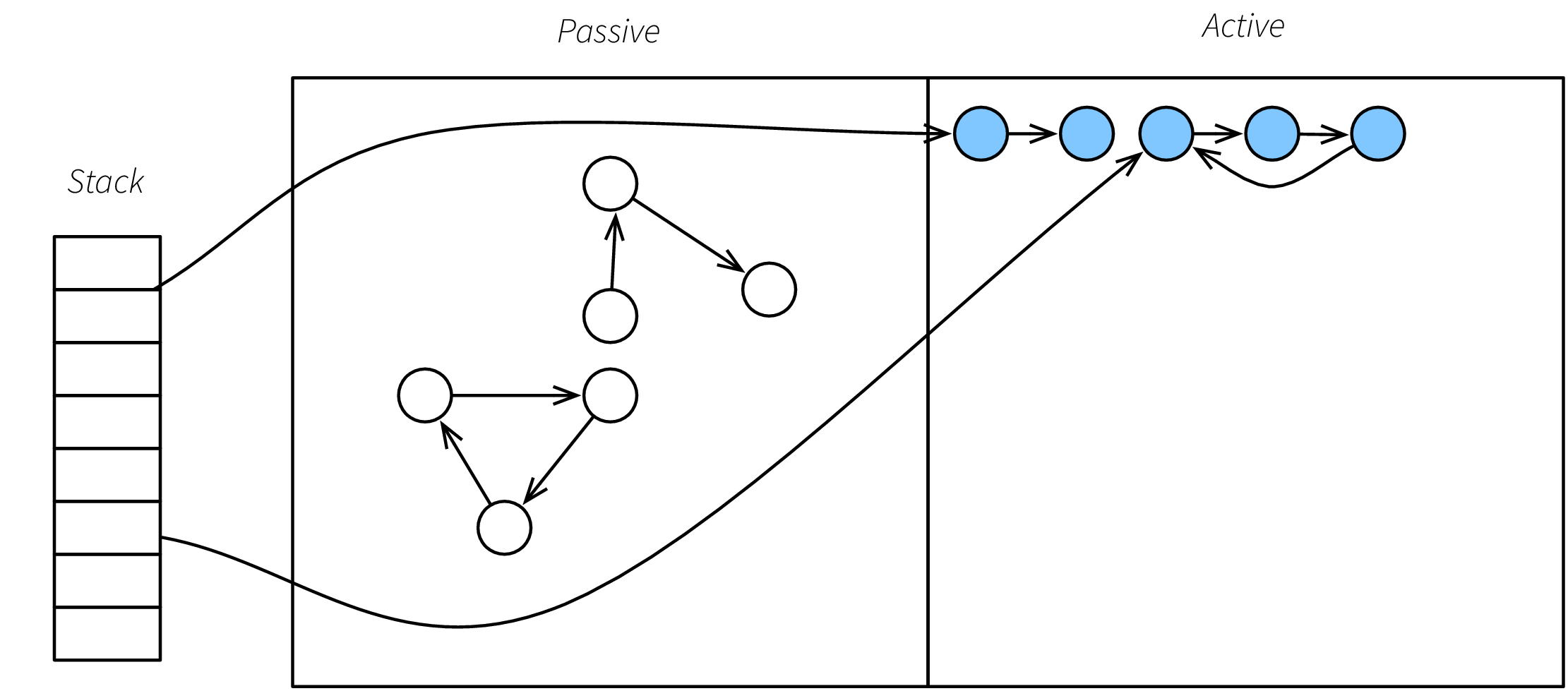
Figure 2: Precis efter skräpsamling.
3.3 En kompakterande, konservativ skräpsamlare för C
Ett problem med skräpsamling i språk som C är avsaknaden av metadata i minnet. Eftersom en pekare och en integer ser identiska ut (och en adress är ett positivt heltal!) är det möjligt att tolka heltalet 3786230 (som kanske avser slutpriset på en enrummare i Stockholms innerstad) som pekaren 0x39C5F6 (samma tal skrivet i bas 16). Har vi otur kan 0x39C5F6 råka vara en valid adress i den heap som hanteras av GC.
Vi kommer att hantera detta problem med en kombination av fyra tekniker:
- Konservativ kompaktering efter Bartlett
- Allokeringskarta
- Höga adresser (frivilligt att implementera)
- Allokering med metadata
3.4 Konservativ kompaktering efter Bartlett
Bartlett skiljer mellan säkra och osäkra pekare. En säker pekare är en adress som vi säkert vet är en pekare. En osäker pekare är en vars data vi inte säkert vet är en pekare. Ett typiskt användande av Bartletts teknik är för skanning av stacken i ett C-liknande språk, där vi inte vet vad det är för data vi tittar på. Pekare på stacken blir därför osäkra, medan pekare mellan objekt på heapen11 blir säkra.
Vi klassificerar alltså alla pekare vi hittar som säkra eller osäkra. Att vara konservativ innebär att vi måste utgå från att en osäker pekare faktiskt är en pekare i bemärkelsen att vi måste betrakta dess utpekade objekt som levande, och samtidigt att vi måste utgå från att den osäkra pekaren faktiskt inte är en pekare vilket innebär att vi inte kan flytta dess utpekade objekt i minnet eftersom det kräver att vi ändrar pekarvärdet till den nya adressen. Exempel, om vi hittar 0x39C5F6 (slutpriset på en lägenhet) på stacken måste det objekt som ligger på den adressen överleva och inte flyttas. Flyttade vi det till t.ex. adressen 0x1C0030 måste vi uppdatera värdet på stacken till 0x1C0030 (peka om “pekaren”), vilket skulle betyda att vi ändrat slutpriset på lägenheten!
För att använda Bartletts trick för att hantera osäkerhet delar vi in minnet som vi hanterar i ett antal diskreta “sidor”12. Istället för att dela in hela heapen i två delar – passiv och aktiv – ger vi varje sida statusen passiv eller aktiv. En osäker pekare till en adress \(A\) medför nu att den omslutande sidan \(P\) inte får flyttas vid kompaktering.
I en skräpsamlare av Bartlett-typ, se figuren nedan, är minnet indelat i många små sidor som var och en kan vara aktiv (grå) eller passiv (vit). Pekare kan också vara säkra eller osäkra (streckad pil). Objekt som utpekas av osäkra pekare får inte flyttas. Detta implementeras genom att hela sidan som objektet ligger på är oförändrad. Detta leder i exemplet i figuren till att ett skräp-objekt inte tas bort för att det råkar ligga på samma sida som ett osäkert utpekat objekt.
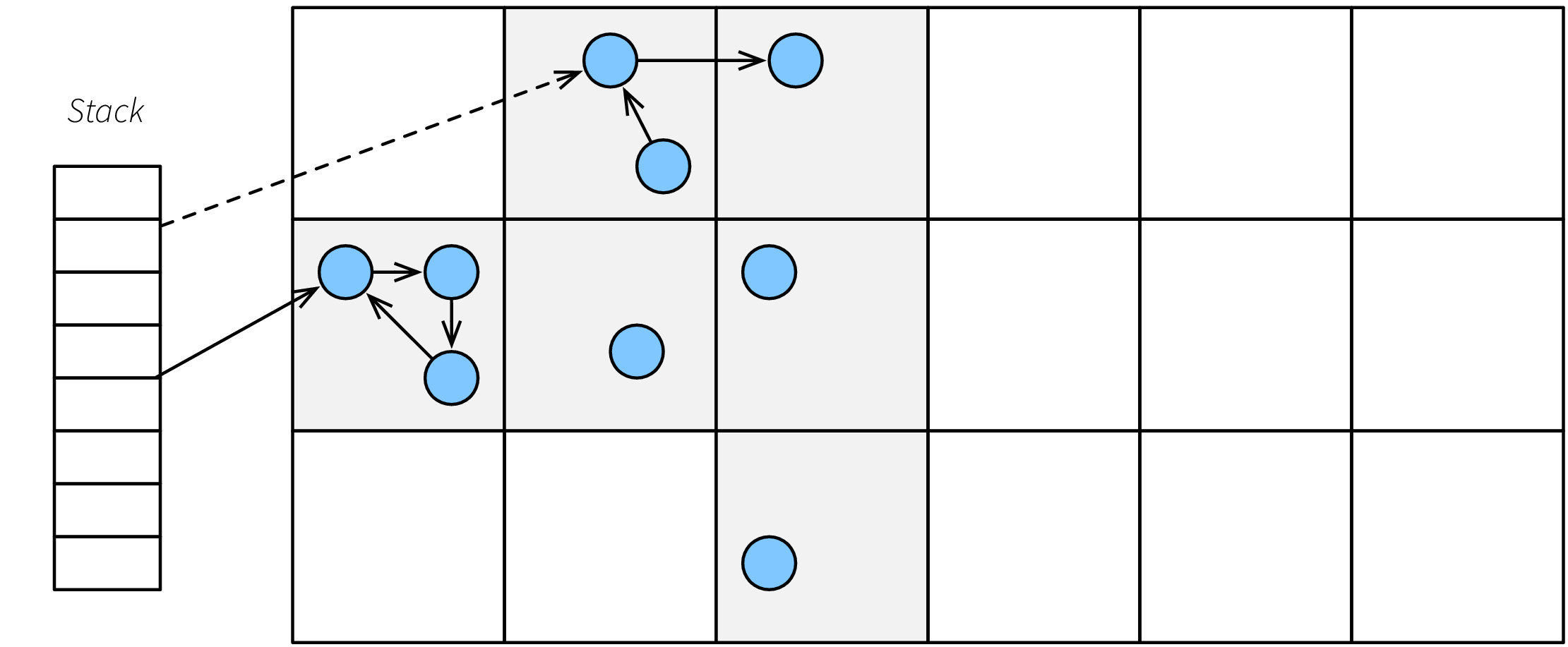
Figure 3: Precis innan skräpsamling.
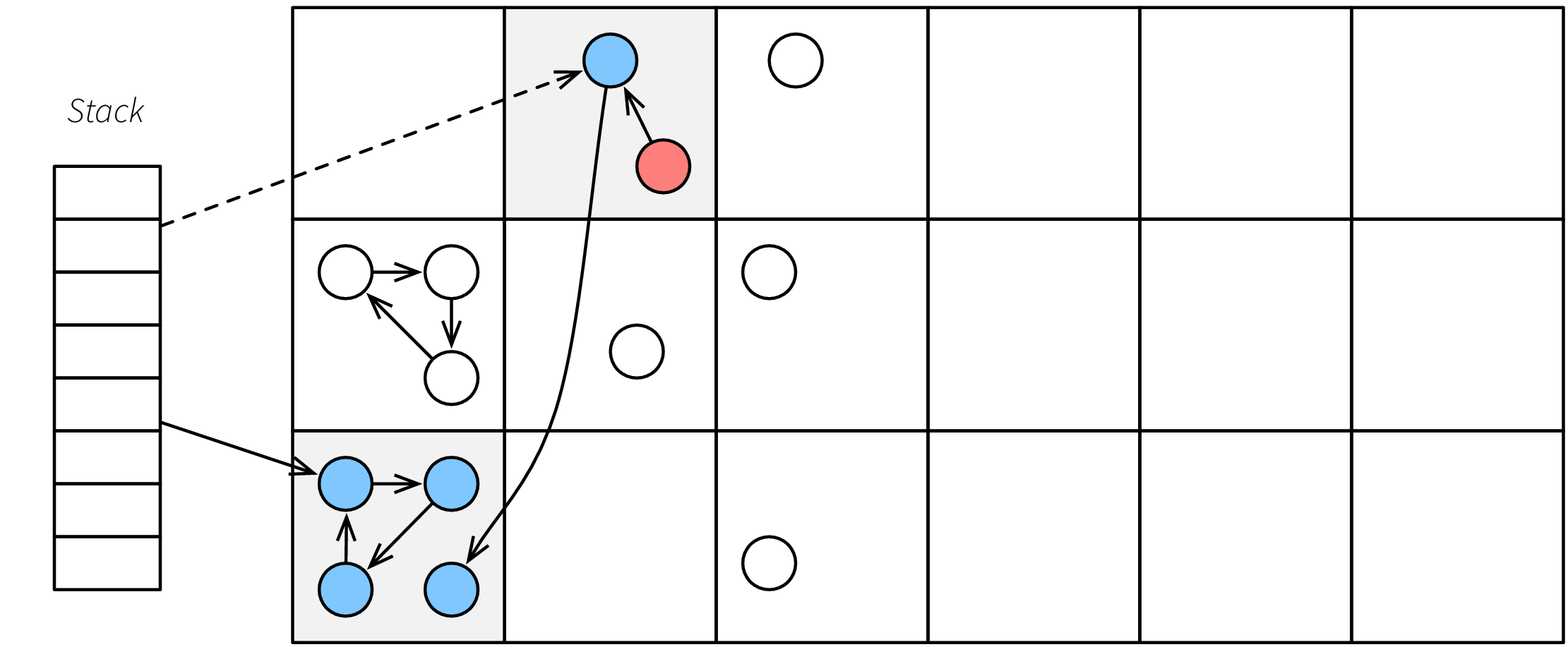
Figure 4: Precis efter skräpsamling.
3.5 Allokeringskarta
Ytterligare ett sätt att minska risken för felaktiga pekarvärden
är att använda en allokeringskarta. En allokeringskarta är en
array av booleans där varje plats i arrayen motsvarar en valid
adress för en allokering, och där true betyder att något
allokerats på den platsen (false – inte). Om man t.ex. har
(vilket är rimligt) en minsta objektstorlek på 16
bytes[fn::Inklusive header.} behöver man alltså
en array med 1024 element för att hålla reda på 16 kb. Om man
använder en bitvektor där en enskild bit är en boolean behövs
alltså bara 128 bytes för att hålla reda på 16 kb, vilket är <1%
overhead.
Om vi återgår till vårt exempel där vi hittar 0x39C5F6 (slutpriset
på en lägenhet) på stacken kan vi se om den boolean som motsvarar
den adressen i allokeringskartan är true eller false. Om
värdet är false kan vi helt ignorera 0x39C5F6. Om värdet är
true måste vi behandla det som en pekare.
Det bitset som vi kodat tidigare på kursen (utdelat i Piazza) är fritt fram att använda för att implementera allokeringskartan.
3.6 Höga adresser
Detta är enkelt att implementera och brukar ge hög avkastning.
Använd t.ex. posix_memalign för att allokera minnet till
programmets egen heap och ange en mycket hög adress som alignment.
Det medför att alla pekaradresser som skapas kommer att vara
väldigt stora. Eftersom program sällan manipulerar väldigt stora
tal minskar risken för att ett heltal i programmet skulle råka
sammanfalla med en valid minnesadress.
3.7 Allokering med metadata
För att slippa leta igenom heapen på samma sätt som stacken kommer vi att använda ett format för allokering som kräver att användaren ger den information vi behöver. Vårt skall stödja två typer av allokering:
h_alloc_struct– där programmeraren anger en slags formatsträng som beskriver minneslayouten hos objektet som skall allokeras13. Formatsträngen beskriver var i ett objekt eventuella pekare finns som också skall traverseras för att markera objekt som levande.h_alloc_raw– där programmeraren anger storleken på ett utrymme som skall reserveras14. Detta utrymme får inte innehålla pekare till andra objekt.
I alla fall ovan skall det allokerade minnet nollställas, dvs.
samma beteende som calloc.
3.8 Formatsträng för h_alloc_struct
Formatsträngen förklaras enklast genom exempel. Antag att vi har en typ
binary_tree_node, deklarerad enligt följande.
struct binary_tree_node { void *value; struct binary_tree_node *left; struct binary_tree_node *right; int balanceFactor; }
struct%20binary_tree_node%20%7B%0A%20%20void%20%2Avalue%3B%0A%20%20struct%20binary_tree_node%20%2Aleft%3B%0A%20%20struct%20binary_tree_node%20%2Aright%3B%0A%20%20int%20balanceFactor%3B%0A%7D%0A
Detta utrymme kan beskrivas av formatsträngen "***i" som
betyder att utrymme skall allokeras för 3 pekare, följt av en
int, dvs.,
alloc("***i");
alloc%28%22%2A%2A%2Ai%22%29%3B%0A
är analogt med
alloc(3 * sizeof(void *) + sizeof(int));
alloc%283%20%2A%20sizeof%28void%20%2A%29%20%2B%20sizeof%28int%29%29%3B%0A
Notera att data alignment kan påverka en strukturs layout för mer effektiv minnesåtkomst i en strukt. Detta kan betyda att två fält efter varandra i en strukt har “tomt utrymme” mellan sig för att värdens plats i minnet skall bättre passa med ord-gränser. Man kan antingen sätta sig in i hur detta fungerar15 – notera att det är plattformsberoende – eller fundera ut hur man stänger av det.16 Ange tydligt i dokumentationen hur detta har hanterats.
En bra första iteration i implementationen av stödet för
allokering med formatsträng implementerar stöd för "*" och
"r", där det sistnämnda står för sizeof(int), vilket på en
64-bitars platform ger möjligheten att allokera antingen i
“byggklossar” om 8 respektive 4 bytes17.
Åtminstone följande styrkoder skall kunna ingå i en formatsträng:
| Styrkod | Betydelse |
|---|---|
* |
pekare |
c |
char |
i |
int |
l |
long |
f |
float |
d |
double |
Ett heltal före ett specialtecken avser repetition; till exempel
är "***ii" ekvivalent med "3*2i". Man kan se det som att
default-värdet 1 inte måste sättas ut explicit, alltså * är
kortform för 1*. En tom formatsträng är inte valid. En
formatsträng som bara innehåller ett heltal, t.ex. "32", tolkas
som "32c". Detta innebär att h_alloc_struct("32") är
semantiskt ekvivalent med h_alloc_raw(32).
4 Implementationsdetaljer
Eftersom objekt i C inte har något metadata måste implementationen hålla reda på två saker:
- Hur stort varje objekt är (annars kan vi inte kopiera det), samt
- Var i objektet dess pekare till andra objekt finns.
Formatsträngen innehåller information för att räkna ut båda dessa, men formatsträngen är inte helt oproblematisk, t.ex. eftersom den ägs av klienten som kan avallokera den18
Om varje formatsträng kopierades med motsvarande strdup() skulle
vi vara mer skyddade mot att de avallokeras i förtid, men det
skulle bli ett påtagligt slöseri att skapa många kopior av
strängar. En bättre implementation skulle använda en mer kompakt
representation av formatsträngen som kunde bakas in i det
allokerade objektet19.
I implementationen av den kompakterande skräpsamlaren skall varje objekt ges en header (metadata), och vi är förstås intresserade av att denna header är så liten som möjligt eftersom program som allokerar många små objekt annars blir för ineffektiva. En bra design är att spara headern precis före varje objekt i minnet. Låt oss börja med att titta på vad headern skall kunna innehålla för information:
- En pekare till en formatsträng (
const char *) - En mer kompakt representation av objektets layout
- En forwarding-adress
- En flagga som anger om objektet redan är överkopierat till den passiva arean vid skräpsamling
Lyckligtvis kan vi representera samtliga dessa data i ett enda
utrymme av storlek sizeof(void *) med hjälp av litet klassisk
C-slughet. Vi kan börja med att notera att alternativ 1 och 2 är
ömsesigt uteslutande, dvs., finns en kompakt representation av
objektets layout behövs varken formatsträng eller en
objektspecifik skräpsamlingsfunktion, osv. Vidare behövs
forwarding-adress enbart när en kopia redan har gjorts av
objektet, vilket t.ex. betyder att forwarding-adressen kan skriva
över objektets data eftersom allt överskrivet data går att hitta
om man bara följer forwarding-pekaren. Slutligen kan vi konstatera
att flaggan i 4 enbart behövs i samband med 3.
4.1 Vilken information finns i headern
Om vi använder adresser som är “alignade” mot ord i minnet, och varje ord är minst 4 bytes, så kommer alla addresser att vara en multipel av 4, vilket betyder att de sista två bitarna i en adress i praktiken inte används. (Virtuellt minne kan medföra att vi har ett stort antal insignifikanta bitar i varje adress, detta är maskin och OS-specifikt.) Notera att man kan använda t.ex.
-falign-functions=16för att även styra vilka adresser funktionspekare får.
För att inte slösa med minnet skall vi använda de två minst
signifikanta bitarna i en pekare för att koda in information om
vad som finns i headern. Alltså, om en 32-bitars pekare binärt är
(med little-endian) 1001000111101100-01100101000001000
pratar vi om att gömma information i de sista två, dvs.
1001000111101100011001010000010__.
Två bitar är tillräckligt för att koda in fyra olika tillstånd, t.ex.:
| Mönster | Headern är en… |
|---|---|
00 |
pekare till en formatsträng (alt. 1) |
01 |
forwarding-adress (alt. 3) |
10 |
tillgängligt för utökning |
11 |
bitvektor med layoutinformation (alt. 2, se nedan) |
Notera att de två minst signifikanta bitarna måste “maskas ut” ur pekaren innan pekaren används – annars kan pekarvärde bli ogiltigt på grund av att datat vi gömt där tolkas som en del av adressen. Det betyder att varje läsning av headern som en pekare skall sätta de två minst signifikanta bitarna20 till 0 i det utlästa resultatet.
4.2 Objektpekare pekar förbi headern
Objektets header ligger alltid först i objektet, men skall inte
vara synlig i några struktar (det skulle göra programmet beroende
av en specifik skräpsamlare, vilket vore dåligt). Därför kommer en
pekare till ett objekt alltid att peka på struktens första byte,
dvs. den “pekar förbi” headern. Och om man vill komma åt headern
måste man använda pekararitmetik och “backa”
sizeof(header) bytes. Denna typ av design tillåter att
skräpsamlaren modiferas så att headern växer och krymper utan att
program som använder skräpsamlaren måste modifieras.
4.3 En mer kompakt layoutspecifikation
Vi skall använda en bitvektor för att koda in en
layoutspecifikation på ett sätt som är betydligt mer yteffektivt
än en formatsträng. Vi kan t.ex. använda en bit för att ange
antingen en pekare eller “data”, t.ex. 11001 är samma som
formatsträngen "**ii*", som ger en objektstorlek på \(32\)
bytes21 om en pekare är 8 bytes och
sizeof(int) är 4~bytes. Vi behöver också information om
bitvektorns längd. Notera att vi enbart är intresserade av
huruvida något är en pekare eller inte – om det är en int eller
en float eller en bool kvittar.
För större allokeringar av data utan pekare behöver layoutspecifikationen enbart vara en storleksangivelse. I likhet med headern kan vi reservera en bit för att ange om layoutspecifikationen är en storlek i bytes, eller om det är en vektor med mer precis layoutinformation.
På en maskin där en pekare är 64 bitar skulle alltså 2 bitar gå åt till metadata om headern, ytterligare 1 bit gå åt till att koda in typ av layoutspecifikation, och resterande 61 bitar antingen vara en storlek i bytes eller en bitvektor och dess längd22.
Notera att eftersom den kompakta layoutspecifikationen har en övre storleksgräns (30 i exemplet i fotnoten här intill) fungerar denna representation bara för data av begränsad storlek (som också styrs av huruvida headern är 32 eller 64 bitar).
5 Att skapa och riva ned en heap
Funktionen h_init som ni skall implementera skapar en ny heap
med en angiven storlek och returnerar en pekare till den. Utöver
storlek skall det gå att ställa in två ytterligare parametrar:
- Huruvida pekare på stacken skall anses som säkra eller osäkra
- Vid vilket minnestryck skräpsamling skall köras
Eftersom det måste vara möjligt att resonera om minneskraven för
en applikation skall allt metadata om heapen också rymmas i
det angivna storleksutrymmet. Dvs., alla eventuella kopior av
formatsträngar etc. skall lagras i “er heap”. Funktionen
h_avail returnerar antalet tillgängliga bytes i en heap, dvs.
så många bytes som kan allokeras innan minnet är fullt (dvs.
minnestrycket är 100%).
Det skall finnas två funktioner för att frigöra en heap och återställa allt minne:
h_deletesom frigör allt minne som heapen använder.h_delete_dbgsom utöver ovanstående också ersätter alla variabler på stacken som pekar in i heapens adressrymd med ett angivet värde, t.ex.NULLeller0xDEADBEEFså att “skjutna pekare” (eng. dangling pointers) lättare kan upptäckas.
6 Att hitta rötterna för skräpsamlingen
Att hitta rötterna (eng. root set) kräver att man letar igenom
stacken efter samtliga bitmönster som kan tolkas som pekare och
som har en adress som pekar in i den aktuella heapen. Detta kan
man göra genom betrakta stacken som en array från \(B\) till \(E\) och
pröva alla möjliga sizeof(void *)-block mellan \(B\) och \(E\).
Eftersom värden kan hållas i register kan det vara lämpligt att
använda någon C-funktion som tvingar alla register att sparas på
stacken, så att inte en pekare missas för att den för tillfället
inte finns varken på stacken eller heapen. Här är ett lämpligt
makro som gör det. Man behöver inte scanna env på något
sätt, utan innehållet dumpas på stacken (verifiera gärna detta
genom att ta reda på hur env är definierad på de aktuella
maskiner du vill köra på genom att läsa deras setjmp.h).
#include <setjmp.h> #define Dump_registers() \ jmp_buf env; \ if (setjmp(env)) abort(); \
%23include%20%3Csetjmp.h%3E%0A%0A%23define%20Dump_registers%28%29%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20jmp_buf%20env%3B%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A%20%20if%20%28setjmp%28env%29%29%20abort%28%29%3B%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%5C%0A
Toppen på stacken kan man approximera genom att t.ex. ta adressen
till en stackvariabel på den översta stack-framen. Ett bättre
sätt, som dock inte fungerar på alla kompilatorer, är att använda
__builtin_frame_address(lvl) som returnerar adressen till den
översta framen på stacken när lvl är 0, den anropande
funktionens stack frame när lvl är 1, etc. För att få toppen på
stacken i användarens program i h_gc kan man alltså bara skriva
void *top = __builtin_frame_address(0). Botten på stacken kan
man också få fram genom att läsa adressen till den globala
variabeln environ som enligt C-standarden skall ligga “under”
starten på stacken23.
Åtkomst till environ ges genom att man deklarerar den som en
extern, analogt med en global variabel:
extern char **environ;
extern%20char%20%2A%2Aenviron%3B%0A
eller lägger till den som ett tredje argument till main.
Notera att huruvida stacken växer uppåt eller nedåt i adressrymden är plattformsspecifikt. Betänk också data alignment vid genomsökning av stacken – på vilka adresser kan man hitta adresser?
7 Gränssnittet gc.h
Nedanstående headerfil sammanfattar det publika gränssnitt som skall implementeras. En doxygen-dokumenterad version finns också tillgänglig i kursens repo.24
#include <stddef.h> #include <stdbool.h> #ifndef __gc__ #define __gc__ typedef struct heap heap_t; heap_t *h_init(size_t bytes, bool unsafe_stack, float gc_threshold); void h_delete(heap_t *h); void h_delete_dbg(heap_t *h, void *dbg_value); void *h_alloc_struct(heap_t *h, char *layout); void *h_alloc_raw(heap_t *h, size_t bytes); size_t h_avail(heap_t *h); size_t h_used(heap_t *h); size_t h_gc(heap_t *h); size_t h_gc_dbg(heap_t *h, bool unsafe_stack); #endif
%23include%20%3Cstddef.h%3E%0A%23include%20%3Cstdbool.h%3E%0A%0A%23ifndef%20__gc__%0A%23define%20__gc__%0A%0Atypedef%20struct%20heap%20heap_t%3B%0A%0Aheap_t%20%2Ah_init%28size_t%20bytes%2C%20bool%20unsafe_stack%2C%20float%20gc_threshold%29%3B%0Avoid%20h_delete%28heap_t%20%2Ah%29%3B%0Avoid%20h_delete_dbg%28heap_t%20%2Ah%2C%20void%20%2Adbg_value%29%3B%0A%0Avoid%20%2Ah_alloc_struct%28heap_t%20%2Ah%2C%20char%20%2Alayout%29%3B%0Avoid%20%2Ah_alloc_raw%28heap_t%20%2Ah%2C%20size_t%20bytes%29%3B%0A%0Asize_t%20h_avail%28heap_t%20%2Ah%29%3B%0Asize_t%20h_used%28heap_t%20%2Ah%29%3B%0Asize_t%20h_gc%28heap_t%20%2Ah%29%3B%0Asize_t%20h_gc_dbg%28heap_t%20%2Ah%2C%20bool%20unsafe_stack%29%3B%0A%0A%23endif%0A
8 Enkla prestandamätningar
Beroende på vilken implementation av malloc du använder
används olika strategier för att allokera minne. Gör några enkla
prestandatest för ett program som allokerar
många objekt25 och mät:
- För ett stort program som ryms i minnet (alltså där
skräpsamlaren aldrig körs), går det att observera
prestandaskillnader mellan er minneshanterare och
malloc? Detta test mäter allokeringens effektivitet. - För ett stort program som inte ryms i minnet, går det
att observera prestandaskillnader mellan er minneshanterare och
malloc? Detta test mäter allokeringens effektivitet, men också skräpsamlingens. Traversering av objekt kostar, men samtidigt krävs endast att man bearbetar data som är levande, till skillnad frånmalloc~/~freedär allt skräp måste explicit lämnas tillbaka, vilket förstås tar tid. - Kör ett program som skapar 4 länkade listor av heltal26, där varje lista
håller i tal inom ett visst intervall, \([0,1*10^9)\),
\([1*10^9,2*10^9)\), etc. upp till \(4*10^9\). Slumpa fram \(M\) tal i
intervallet \([0,4*10^9)\) och stoppa in dem i rätt listor[fn::Det
är viktigt att varje slumptal tas fram ur intervallet
\([0,4*10^9)\) och inte att man först slumpar lista ett, sedan
lista två etc.]. (*) Slumpa sedan fram \(N\) tal och sök igenom
rätt lista och svara på om talet finns där. Detta program
kommer att delas ut. Använd både
mallococh er egen minneshanterare i ovanstående program och jämför körtiderna. Storleksförhållandet mellan M och N bör vara sådant att \(M\approx 10*N\). Pröva också att göra en skräpsamling vid punkten (*) i programmet och justera N uppåt utan att ändra \(M\). Kan man se en skillnad i körtider? - Frivilligt! Jämförelse med Boehm–Demers–Weiser’s GC (BDW).
Ladda ned och installera skräpsamlaren BDW. Den fungerar
liknande som den skräpsamlare vi bygger på denna kurs, men är
betydligt mer avancerad och fungerar med flertrådade program,
etc. BDW har bara bara stöd för en enda heap, vilket betyder att
interfacet är enklare: inkludera (dess)
gc.hoch ersätt alla anrop tillmallocmedGC_malloc, samt anropaGC_init()först i programmet. Jämför er prestanda med BDW genom att göra motsvarande integrationer med BDW för programmen ovan.
Resultatet av prestandatesterna kommer att efterfrågas i samband med redovisningen. (Grafer är ett bra sätt att förmedla information!)
Körtid kan man mäta t.ex. med time (ett POSIX-program) eller
genom att använda C:s inbyggda funktioner för att läsa av
systemklockan (t.ex. time.h).
9 Integration med existerande program
Kronan på verket när skräpsamlaren är klar är att integrera den med ett existerande program. Vi kommer att plocka ett slumpvist valt program från en godkänd redovisning av Z101 (fas 1/sprint 2). Detta program kommer inte ha några globala pekare och allokera sitt minne dynamiskt (jmf. krav på denna inlämningsuppgift).
Vi kommer sedan att ta detta program och skriva om det så att alla
anrop till malloc / calloc går till h_alloc (eller
h_alloc_raw).
Vid slutseminariet skall ni demonstrera att er skräpsamlare fungerar med detta program!
Questions about stuff on these pages? Use our Piazza forum.
Want to report a bug? Please place an issue here. Pull requests are graciously accepted (hint, hint).
Nerd fact: These pages are generated using org-mode in Emacs, a modified ReadTheOrg template, and a bunch of scripts.
Ended up here randomly? These are the pages for a one-semester course at 67% speed on imperative and object-oriented programming at the department of Information Technology at Uppsala University, ran by Tobias Wrigstad.
Footnotes:
calloc, posix_memalign i stdlib.h, eller mmap i
sys/mman.h, eller…printf
beskriver hur en utskriven sträng ser ut och var olika värden
skall stoppas in. Se nedan.malloc.01 för r och 11 för * och 00 för inget mer så
räcker det med att scanna bitvektorn tills man hittar 00 för att
avgöra längden och maxlängden blir 30. Men är detta en
optimering?